前言
随着大数据时代的到来,数据的价值在流通、融合、共享中被挖掘和提升,给各行各业的发展和人们日常生活带来了极大的便利。而与此同时,国家将个人隐私和数据安全的保护要求提升至法律层面,数据隐私安全越来越受到重视。如何在满足法律法规,保证数据隐私安全的前提下,充分发挥数据的资源和资产的特性,成为研究热点。其中,联邦学习(Federated Learning)作为行之有效的解决方案引起了广泛关注。
运营商拥有海量的数据,在保障公司数据资产安全的前提下,研究联邦学习,探索大数据共享协同,可充分促进数据生产要素的流通,发挥数据价值。
联邦学习与隐私保护
联邦学习技术最初由谷歌AI团队提出,是一种新兴的人工智能基础技术,指各个参与方能够在原始数据不离开本地的前提下,联合开展模型训练,构建机器学习模型。根据训练数据的特征空间和样本空间的分布情况,联邦学习可以分为横向联邦学习、纵向联邦学习等。
横向联邦学习,指各个参与方的数据集有相同的数据特征和不同的样本ID集合的情况下,基于各参与方的同构数据进行的机器学习建模。而纵向联邦学习则与其不同,各个参与方是通过使用相同的样本ID集合和不同的数据特征来共同建模。
联邦学习通过与隐私保护技术结合,可确保隐私数据不出本地,并且信息在交互过程中得到最大限度的保护,各参与方能够安全的协同训练机器学习模型。
运营商与各个企业及政府机构,在各种垂直行业中,均存在大数据共享协同的应用场景,下面以电信反诈为例介绍联邦学习在运营商的应用。
电信反诈横向联邦学习建模
近年来电信诈骗呈现持续高发态势,诈骗形式层出不穷。运营商是电信反诈的主力军,但面对当前复杂多变难防的电信诈骗案件,以一己之力应对是不够的,各运营商应联合起来,使数据分析更加全面,提高诈骗识别准确率。
运营商所拥有的数据有相似的特征,而服务的客户群体一般来说重叠交集比较少,可以通过横向联邦学习建立电信反诈机器学习模型。
诈骗电话在通信行为上常常与正常电话存在区别,而且诈骗电话多为主叫,可以选取某些通信行为特征,如主叫通话次数、主叫外地通话次数、主叫率、主叫通话时长、被叫通话次数等多个特征维度的用户样本数据进行联合训练。具体步骤如下:
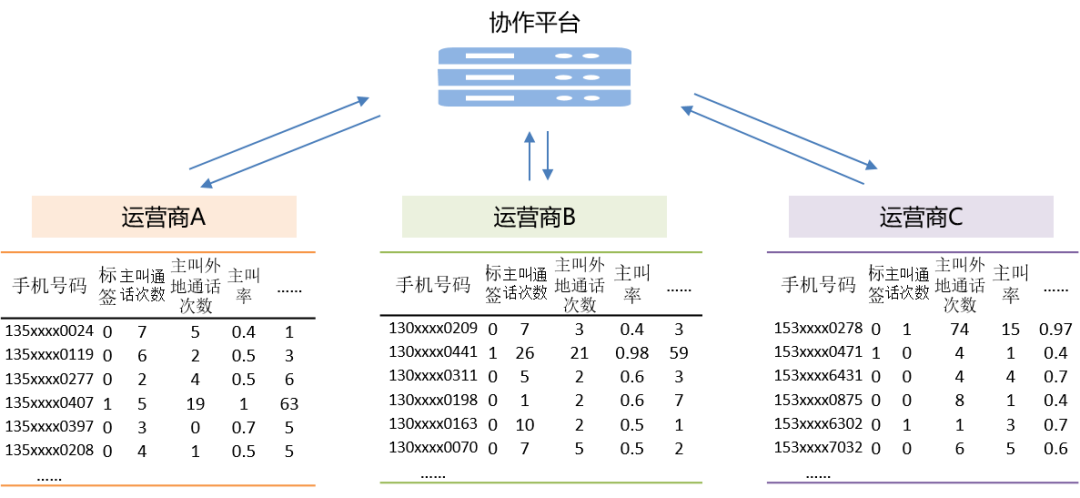
步骤一:各运营商在本地使用机器学习算法(如逻辑回归算法),对上述通信行为特征样本数据集计算模型梯度,并使用同态加密、差分隐私或秘密分享等加密技术,对梯度信息进行加密处理后,发送至协作平台。
步骤二:协作平台对接收到的各运营商的加密梯度信息进行安全聚合,做加权平均后,将计算的梯度信息发送给各个运营商。
步骤三:各运营商收到加密的梯度信息后,解密得到梯度明文,更新本地模型参数。
步骤四:进行多轮迭代后,当模型收敛,或者达到允许的迭代次数上限,完成训练和模型评估,使用模型可进行电信反诈在线预测。
在联邦学习过程中使用安全多方计算等隐私保护技术对梯度信息或模型参数信息加密,能够防止数据泄密,保护用户隐私数据。
电信反诈纵向联邦学习建模
由于诈骗渠道和手段越来越多样化、专业化,作案手段已从最初的发短信、打电话等发展到使用各社交APP软件等多种渠道联合作案的新型犯罪手段。运营商有必要联合互联网社交平台企业,构建电信反诈模型,通过互联网社交平台的信息帮助运营商提高诈骗识别准确率。
运营商与互联网企业拥有很多有交集的用户群体,因各自的商业模式不同而拥有不同的用户特征数据,联合不同的特征数据具有互补性,有助于提升电信反诈识别率,可以通过纵向联邦学习建立电信反诈机器学习模型。具体训练步骤如下:
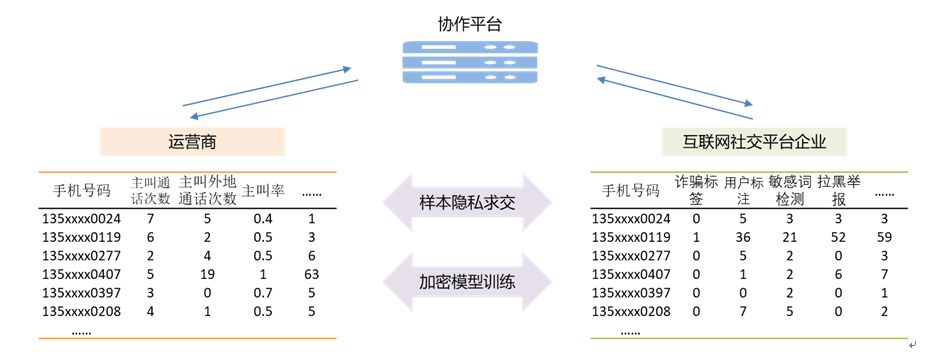
步骤一:运营商与互联网社交平台企业之间需要先进行样本对齐,使用安全的隐私求交技术,如基于Diffie-Hellman密钥交换或基于RSA、哈希算法,找到双方公共ID集合。
步骤二:双方基于本地数据和机器学习算法(如逻辑回归算法),分别计算出本地特征向量的模型中间结果,并对中间结果进行加密,发送至协调方。
步骤三:协调方获取双方的中间结果后,协同计算出完整的模型参数信息,将模型参数信息按参与方特征向量进行划分后再分别发送给参与方。
步骤四:参与方对数据解密获得模型参数信息,进行本地模型参数更新,得到新一轮迭代结果。重复执行上述步骤,直到模型收敛,训练结束。
总结
除了电信反诈场景,运营商还可以通过数据共享协同,帮助银行实现金融风控,与广告公司联合构建广告投放推荐模型,与交通部门联合构建实时拥堵预警模型等等。运营商在与各个企业机构协作共享时,虽然场景不同,数据对象不同,但是有共性的保障本企业数据资产和数据隐私保护需求。使用联邦学习技术可以有效保障运营商自身的数据隐私安全,充分促进数据生产要素的流通,发挥数据价值。
声明:本文来自禾云安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
