
数据不均衡现象
数据不均衡,顾名思义即数据中的正负样本量比例过大。在机器学习领域,正负样本数量比例大于1:10,即判断数据不均衡。数据不均衡问题,广泛出现在机器学习的各个场景中,如广告领域的点击与转化问题,医疗领域的癌症检测问题,安全领域的网络攻击识别问题等。
但相比于传统机器学习数据,在金融反欺诈领域中,正负样本比例往往更加悬殊。如上一期“金融反欺诈实战(一):电子银行非本人交易识别解析”所提到欺诈交易识别问题中的正负样本比例常为1:1000~1:10000,甚至在部分特殊场景下,比例可以达到1:100000。
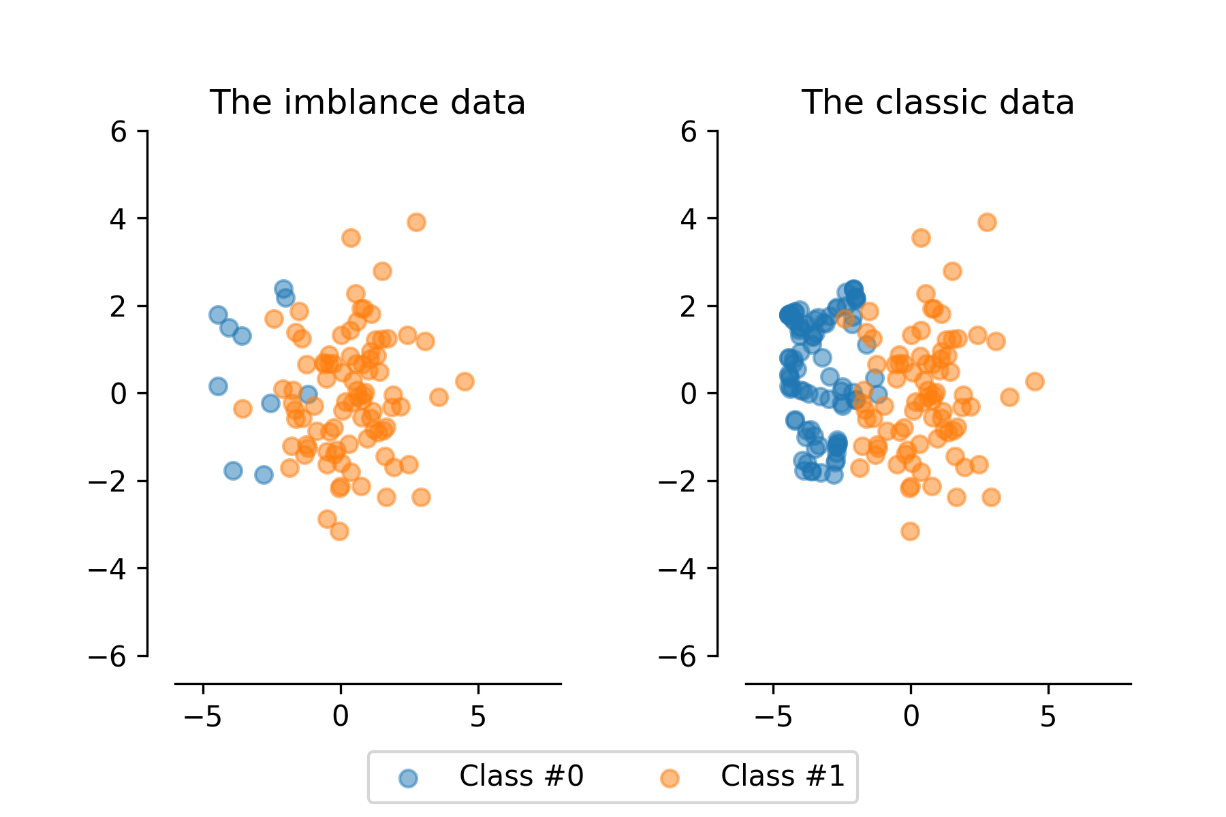
图1 不均衡数据与经典均衡数据比较
召回/准确率陷阱
在正负样本数量差距如此悬殊的背景下,盲目套用传统机器学习建模思路,无疑是极为不适合的。本篇文章作为金融反欺诈实战系列的第二篇,将会讨论如何使用合理、有价值的评价指标去评价反欺诈识别模型。
诚然,评价指标对任何算法建模都极其重要,但在数据不均衡场景下,因为数据特点,评价指标相比于其他场景面临着更多的问题与挑战,更凸显其重要性。在此我们以常用的准确、召回率为例,进行简要的解释说明。

图2 准确召回率计算
假设我们拥有一个由100万负样本,1万正样本组成的数据,需注意的是实际上反欺诈领域的数据倾斜往往大于此比例。假设训练好的反欺诈模型将全部样本都判别为负样本,那么基于全局准确、召回指标评价模型,其准确、召回率均为99%,显然不能客观的评价模型效果。
当然这是较极端的例子,在实际使用中,为了避免此种情况,通常基于不均衡样本中某一类样本的准确、召回来进行模型评价,以此在一定程度上降低评价指标受到数据不均衡问题的影响,提高评价指标对于不均衡数据的敏感度。
评价指标敏感度
我们用评价指标敏感度来衡量评价指标受数据不均衡影响的大小程度,受影响大为敏感,反之不敏感。针对数据不均衡问题,我们应尽量选用不敏感的评价指标。
常用评价指标对于样本不均衡问题的敏感度,如下图所示:
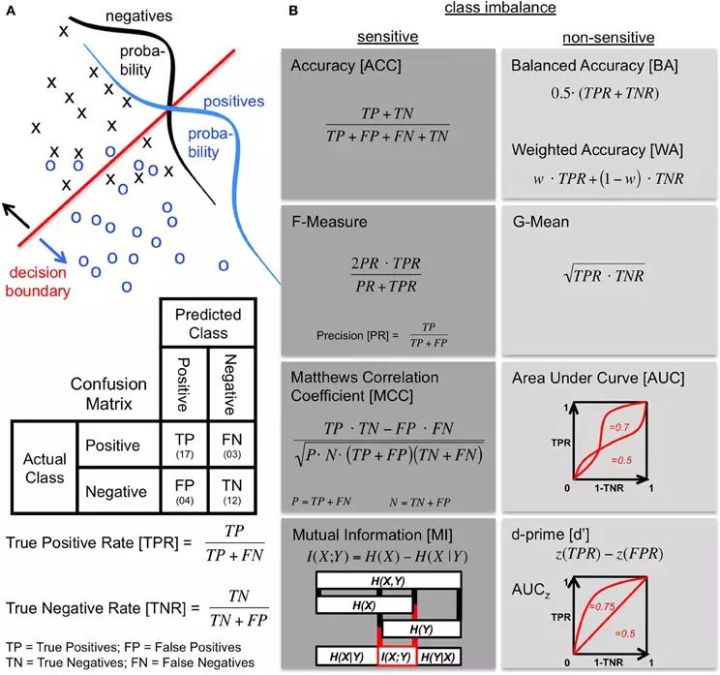
图3 评价指标不平衡数据敏感度,引用图片来自于参考文献[1]
总结上图,敏感度高的评价指标主要有AUC、WA、G-Mean等;敏感度低的评价指标主要有ACC、F-Meature、MI等。
问题真的解决了吗?
经过前半部分的分析介绍,看起来我们已经可以根据自己的数据来选择适合自己的评价指标,完成反欺诈模型的指标评价。但我们不妨停下来想一想,问题真的迎刃而解了吗?
在此我们认为至少还存在三个问题,需要进一步思考。
1.基于样本区分能力的评价指标是否合理
2.测试数据如何选取
3.如何将理论化、难以理解的评价指标,转化为业务部门易于理解的业务指标
接下来我们一起来观察在不均衡条件下,相对不敏感的评价指标AUC得分所受的影响。AUC(Area under the Curve of ROC)由ROC曲线计算而来,其值为ROC曲线下方面积,常用来判断二分类预测模型在数据上表现的优劣。AUC值越高,我们认为模型对于样本区分能力越强,对于正负样本区分能力越好。
举一简单样例进行说明,假设原始测试数据由50个负样本与5个正样本组成的。针对于原始测试数据,我们只调整测试数据中一个正样本数据特征,得到测试数据集A与B,使用相同模型获得三个数据集的样本得分。
样本得分越高,标志着样本被模型判断为正样本的置信度越高。在三个数据集样本得分上,负样本得分完全相同,正样本得分在被调整的正样本上有微小波动。
在下图中,被标红的正样本得分标志着A、B数据集中调整的正样本的得分,以此我们来观察在样本不均衡情况下,正样本极小波动对于AUC得分所造成的影响。
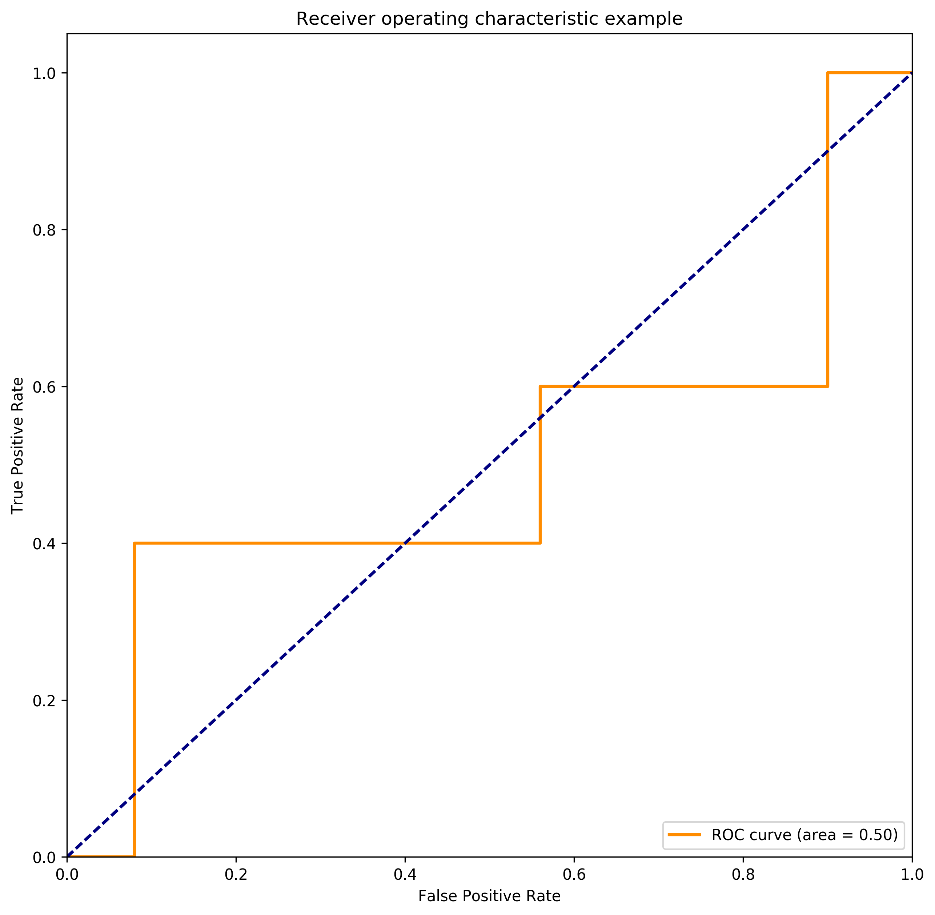
图3 原始数据集:正样本得分 0.9,0.9,0.4,0.1,0.1 AUC得分0.5
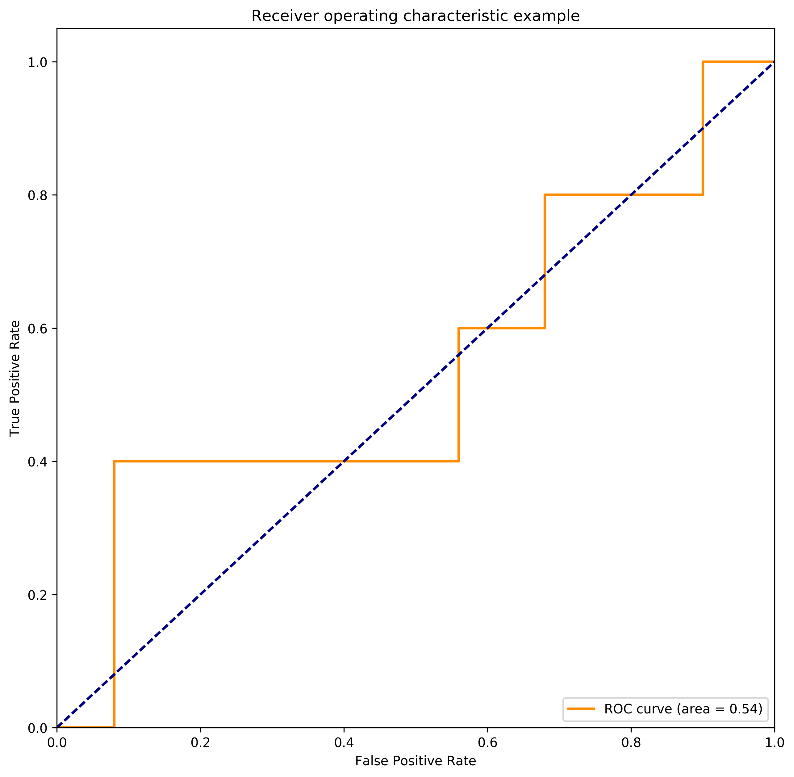
图4 数据集A:正样本得分0.9,0.9,0.4, 0.3 ,0.1 AUC得分0.54
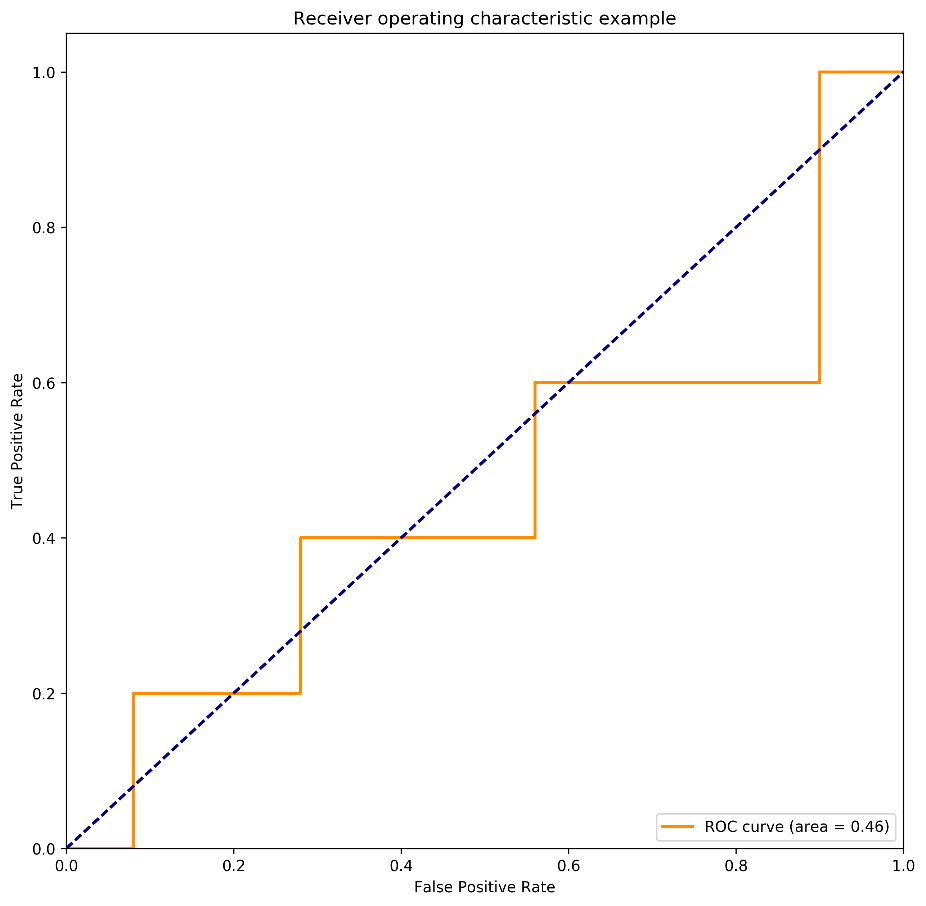
图5 数据集B:正样本得分0.9, 0.7,0.4, 0.1,0.1 AUC得分0.46
结合上图,我们可观察到,当少数类样本中有一样本得分由0.1升为0.3时,对应的全局AUC提升了10%,在模型评测中已可算为重大的模型提升。但在实际分类应用时,单个样本得分提升至0.3,对于最后的分类结果可以说影响微乎其微。
同样,当单个少数类样本得分由0.9变为0.7时,模型AUC评分下降了10%。但在实际分类应用时,其影响也并无AUC指标表示的差别如此之大。
合理选择评价指标
总结从前面AUC示例学习到的经验,我们认为在应用此类评价指标时,应注意两点:第一,如非必要尽量不使用全局数据进行评价,而应锚定指定阈值或一定数量样本,使用局部AUC指标计算;第二,可引入专家系统,人工赋予正样本危害度权重大小,以此为基础完成评价,可参考使用经典的MAP、NDCG等推荐排序指标。
在此简单介绍MAP指标。MAP(Mean Average Precision平均准确率)来源于自然语言处理,其计算方式为使用正样本在测试数据中的排序序号除以对应正样本在模型结果中的排序序号后求和。MAP值越高,意味着模型的检索能力越强,也即模型对于正负样本区分性越强。
例如:假设有一份测试数据,其中1~7为正样本,其序号越大代表案件危害性越大。在此使用MAP评价两个模型。模型1检索识别出4个正样本,其序号分别为1, 2, 4, 7;模型2检索出3个正样本,其序号分别为1,3,5。则模型1的MAP为(1/1+2/2+3/4+4/7)/4=0.83。模型2的MAP为(1/1+2/3+3/5+0+0)/5=0.45。
合理选择评测数据
关于评测数据的选择,在数据分布均衡的模型评测中,训练集、测试集由全部数据按一定比例切分而来,无需担心由不均衡数据导致的各种问题。
但在不均衡数据上,由于正样本极度稀少,如按传统切分方式,那么可能造成两种情况:测试集中正样本数据极少,不足以客观评价算法;训练集中正样本数据极少,无法充分训练数据。如下图一般,有锅无米。

为解决上面的问题,有时会采取变通的方式,使用固定数目正样本加指定数据随机采样负样本的样本混合策略来完成测试数据的提取,进行模型评测。显然在此情况下,评测指标(如P/R值等)很大程度上受测试数据正负样本比影响。
故针对欺诈交易识别问题,结合实际应用经验,我们推荐较合理的测试数据为:在有一定案发量前提下的一段时间内全部交易数据。采用此种数据进行测试,可回溯测试模型在真实线上数据的效果表现。在条件有限的情况下,亦可采用有案件的各天交易数据进行评测,但此时欺诈交易模式突变或当天案发量极少(小于5笔)时,存在评测指标波动的风险。
评价指标应结合实际业务
通过上述分析,我们终于选取了适宜的反欺诈评测指标,但此时一个更棘手的问题又摆在我们面前:业务部门作为反欺诈模型的应用方往往难以理解我们复杂的评价指标,并对于模型效果难以通过指标直观发现其价值,往往无法顺畅地沟通。
当我们用一个较好的指标评价模型时,给业务部门直接反馈技术评价指标,我相信对于绝大部分金融机构业务人员而言,是很难直观的将其与实际业务中所面对的交易相关数据进行结合。
因此,技术人员需要用尽可能贴合业务的方式更好的描述指标,展现模型效果。通常在反欺诈模型应用中,我们常用覆盖住一定比例案件的情况下,模型的误报率(即每判别一个正样本,牺牲负样本的比例)来与业务部门沟通。基于此,业务部门可直观得到在设定案件覆盖率的情况下,每日需处理的模型误报量及对应模型所能识别的案件量。
以上为笔者对于反欺诈领域模型评价指标的浅显思考,欢迎留言讨论。
参考文献
[2]Bekkar M, Djemaa H K, Alitouche T A. Evaluation measures for models assessment over imbalanced data sets[J]. Journal of Information Engineering & Applications, 2013.
[3]Basic evaluation measures from the confusion matrix
作者:360企业安全反欺诈实验室
声明:本文来自360企业安全反欺诈实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
