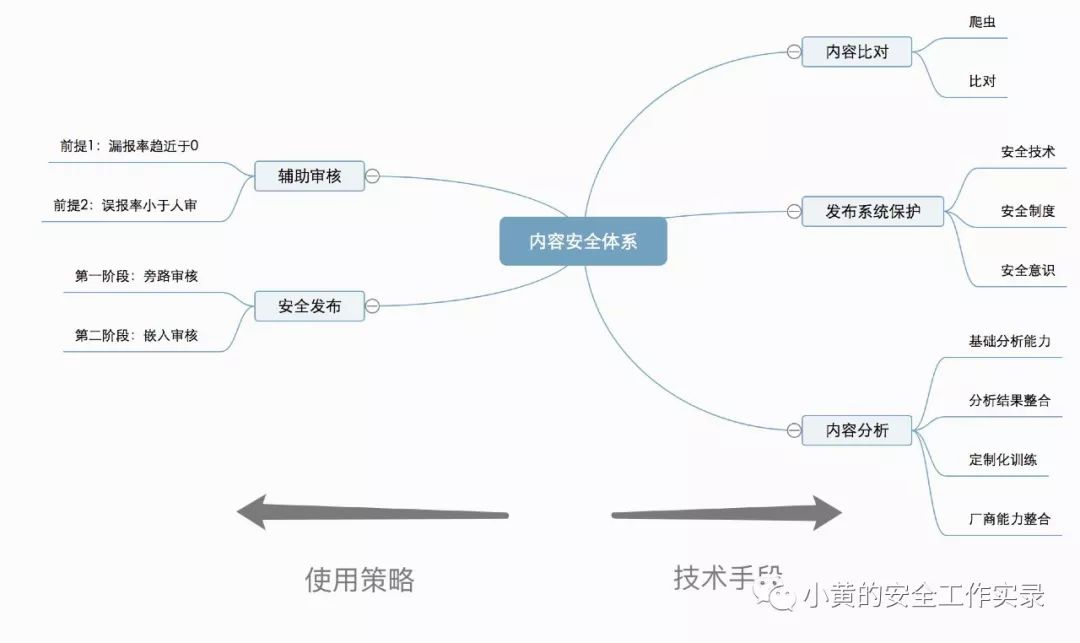
笔者几个月前曾写过两篇文章(问题篇和方案篇)介绍内容安全的基本情况。回看之前的文章,感觉当时思路比较零散,不成体系。经过多方面测试和交流,梳理内容安全的整体体系建设的思路,总结如下:
适用场景:
对自己发布内容极为敏感的内容平台。
整体架构:
内容安全体系将从技术手段和使用策略两个方向设计,我们展开一下。
一、内容比对
这套逻辑主要针对网站内容没有完成https改造的情况设计,所以已经实现了https的朋友可以跳过这段内容。由于内容明文传输,理论上网络上任何位置都可以对网站内容进行劫持,并篡改成攻击者想要的内容。大到运营商骨干链路,小到小区宽带出口,都有篡改风险。
内容比对逻辑的关注点不在于如何防止劫持,而是快速发现。基本思路就是在公网上部署监测点(爬虫),模拟正常访问,将内容与发布系统的内容进行比对。笔者在《内容安全那些事之方案篇》中介绍了比对的基本逻辑,这套逻辑是根据笔者公司所遇到的实际情况设计的,比较复杂,有很多优化的空间。比对逻辑做重要的就是如何选择监测点部署的位置,因为我们不可能无限的部署监测点,必须要根据实际情况将监测点部署到最容易出问题,或者企业最关注的区域。
二、发布系统保护
完成https改造后,内容安全的视角基本可以从外部转向内部。首先是对发布系统的保护,这个层面的工作笔者一般不归入内容安全设计方案中,不是因为不相关,而是范围太大。保障发布系统安全几乎涉及到所有安全手段,懂技术到管理,再到意识。这里简单展开一下:
2.1 技术手段
笔者所在的体系是按照等级保护作为基础参照系,将发布系统单独划分出安全域,根据实际情况落地所有我们认为的技术手段。这个层面的工作的难点是:如何定义发布系统范围。听起来很奇葩,但是这确实是我们一度很难明确的一个问题。
2.2 管理手段
管理针对发布系统的安全管理,除了标准的安全管理体系外,还需要类似审发机制、发布系统操作流程等业务相关的管理规范。
2.3 安全意识
发布内容的最终是人,所以安全意识的灌输非常重要。笔者团队正在通过一系列对内运营的手段实现员工安全意识培养,这部分工作还不太完善,我会在后续文章中专门论述。
三、内容分析
① 图片识别
笔者在《方案篇》中提到过,需要特殊说明的是,目前商业产品中敏感人物接口普遍存在分类模糊的情况。目前比较理想的方案,一是由图片识别接口细化分类,至少要细化到正面人物和负面人物;二是接口识别出人名,再由使用方根据自身需要定义分类。
② 文字识别
笔者在《方案篇》中也提到过,比较普遍的方式是敏感词识别,包括识别各类变种。但这还不够现在很多内容安全提供上都提供了情感倾向分析的工具。通过测试来看,一些比较明确的倾向比较好判断,如果有意“调戏”AI接口还是很容易骗过去的,所以这需要定制化的训练过程。
③ 图文结果整合
由于新闻类平台报道类型十分多样,不能简单的只允许某类信息出现,或者不允许某类信息出现。最基础的可以做到页面中图片和文字内容相匹配。举个简单的例子:如果图片任务是正面人物的话,下方的文字就不能是负面情绪。这类策略可以根据需求组合,但基础还是图片的细化分类和语义的准确分析。
④ 自主训练
上文提到我们可以根据内容平台的具体情况,有针对性的训练算法,使系统能够与企业的情况匹配的越来越好。但这是个很有挑战的工作,机器学习技术在不断的普及中,很多定制化训练的服务都可以买得到,但一些比较复杂的逻辑还是需要大量专业人员、大量的计算资源和时间。目前比较容易实现的事对特定人物的识别。
⑤ 多厂商能力整合
从前期对市场了解的结果看,不同内容安全厂商的关注点不尽相同,有些厂商偏重图片识别,有些厂商的语义分析做的比较好,而且产品形态都是通过接口方式呈现。如此一来,甲方一方面要根据所选厂商接口开发相关内容获取系统;另一方面甲方如果只与一家厂商合作势必存在短板。我们希望通过一个统一的系统将不同的内容数据分配给各家不同的分析平台,其实逻辑很简单,就是整合不同的内容获取的方式之后,对各家接口完成翻译工作。这是笔者在内容安全方面最希望实现的结果,目前笔者团队正在开发这套系统,争取年内可以完成。
⑥ 视频分析
目前笔者了解到是视频分析策略都是将视频抽帧,然后针对抽帧后的图片进行处理。但想象一个场景,如果有五个字的反动标语分别出现在五个不同帧的不同位置,人脑很容易的将其拼接到一起,机器就要解决精确抽帧和上下文关联的难题,目前笔者尚未找到可行的解决方案。所幸,在实际情况中视频内容篡改的情况目前还没出现过,我们只能继续观望。
上述内容就是笔者团队设计的内容安全整体分析逻辑,但这还不够,对这类内容分析平台的使用策略也是值得研究的,下面列举两个笔者想到的应用场景。
⑦ JS分析
从笔者经历的各类内容安全事件看,JS篡改的占比非常高。JS的调用逻辑复杂,再加上经常会有域外的调用(比如广告),这造成了内容展现极大的不确定性。我们目前采用两种方法解决此类问题:一是将JS当做资产进行管理,通过爬虫将全网JS文件和所牵涉的页面进行全面统计,再由业务部门领用,并清理没人维护的JS链接(尤其是外站的);二是通过分析引擎完成JS的加载过程,并将加载后的最终结果交给内容分析系统进行综合判断。
四、使用策略
4.1 辅助审核
目前能买到的产品基本都从辅助审核的角度出发帮甲方解决问题。但如果平台发布的内容非常敏感的话,至少实现下面两个条件之一,才有可能将机器审核放到人工审核的前面:
漏报率趋近于0
误报率小于人审
如果上述两个都不能实现,机器审核最多和人审平行,这一点很重要。
4.2 安全发布
笔者所在企业的发布渠道非常复杂,同时目前机器也无法满足上述两个条件。所以我们选择不改变现有审核流程,而从内容发布到公网前的最后一个环节将内容取出进行审核。一方面作为人审的保底策略,另一方面审核一些非正常渠道(可能是特例,可能是黑客)发布的内容。我们通过两个阶段来完成:
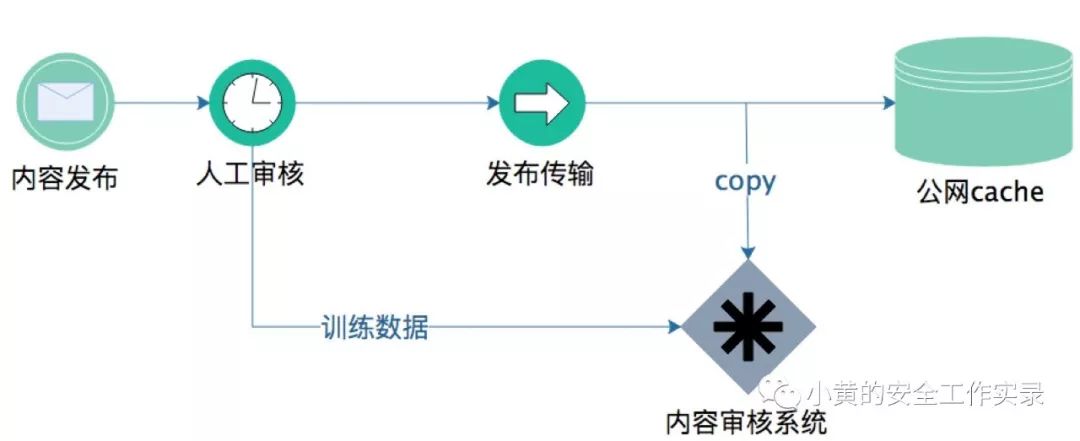
第一阶段-旁路审核:不影响现有发布逻辑,将内容copy出一份用于审核,发现问题报警,后续由人工干预。同时,人工审核的结果同步到内容审核系统,作为训练数据,以进一步提升审核能力。如下图:
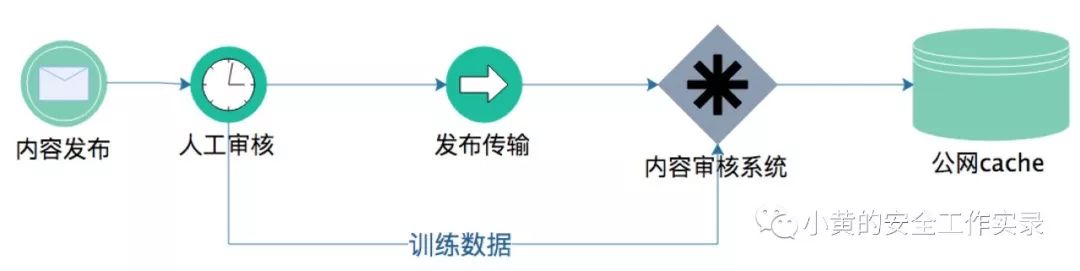
第二阶段-嵌入审核:如果系统分析能力符合预期,第二阶段将审核系统嵌入到整体发布流程中,审核系统可以直接拒绝部分内容的发布。如下图:
写在最后
内容安全是媒体的命脉,一旦出现大的问题将决定一个企业的存亡。随着机器学习技术的兴起内容安全分析多了一个非常重要的工具,但如何用好这类工具为企业服务是很值得思考的问题。笔者前后用三篇文章分析内容安全体系的建设,但这恐怕还是不够,整个体系从设计到实现还需要走很远的路。本文下笔之前希望全面分析内容安全体系建设的每一个细节,但现在看来有些问题还是不能详细阐述,有的是因为企业架构不能透露(如审核系统接收数据选点问题),有的是因为没有最终实践不能乱写(如定制化训练的具体方法)。本文就作为设计阶段的一个终结,等到这个体系建设完成之后再来跟大家分享。
声明:本文来自小黄的安全工作实录,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
