互联网最激烈的对抗战场,除了安全专家与黑客之间,大概就是爬虫与反爬虫领域了。据统计,爬虫流量早已超过了人类真实访问请求流量。互联网充斥着形形色色的爬虫,云上、传统行业都有不同规模的用户被爬虫爱好者盯上,这些爬虫从哪里来?爬取了谁的数据?数据将被用于何处?
近日,腾讯云发布2018上半年安全专题系列研究报告,该系列报告围绕云上用户最常遭遇的安全威胁展开,用数据统计揭露攻击现状,通过溯源还原攻击者手法,让企业用户与其他用户在应对攻击时有迹可循,并为其提供可靠的安全指南。本篇报告中,云鼎实验室通过部署的威胁感知系统,捕获到大量爬虫请求流量以及真实来源 IP,且基于2018年上半年捕获的数亿次爬虫请求,对互联网爬虫行为进行分析。

一、基本概念
1. 爬虫是什么?
爬虫最早源于搜索引擎,它是一种按照一定的规则,自动从互联网上抓取信息的程序。
搜索引擎是善意的爬虫,它爬取网站的所有页面,提供给其他用户进行快速搜索和访问,给网站带来流量。为此,行业还达成了 Robots 君子协议,让互联网上的搜索与被搜索和谐相处。
原本双赢的局面,很快就被一些人破坏了,如同其他技术,爬虫也是一把双刃剑,变得不再「君子」。尤其是近年来「大数据」的概念,吸引了许多公司肆意爬取其他公司的数据,于是「恶意爬虫」开始充斥互联网。
本篇报告主要聚焦于「恶意爬虫」,不讨论搜索引擎爬虫及合法爬虫等。
2. 爬虫的分类
按爬虫功能,可以分为网页爬虫和接口爬虫。
网页爬虫:以搜索引擎爬虫为主,根据网页上的超链接进行遍历爬取。
接口爬虫:通过精准构造特定 API 接口的请求数据,而获得大量数据信息。
按授权情况,可以分为合法爬虫和恶意爬虫。
合法爬虫:以符合 Robots 协议规范的行为爬取网页,或爬取网络公开接口,或购买接口授权进行爬取,均为合法爬虫,该类爬虫通常不用考虑反爬虫等对抗性工作。
恶意爬虫:通过分析并自行构造参数对非公开接口进行数据爬取或提交,获取对方本不愿意被大量获取的数据,并有可能给对方服务器性能造成极大损耗。此处通常存在爬虫和反爬虫的激烈交锋。
3. 数据从哪来?
爬虫不生产数据,它们只是数据的搬运工。要研究爬虫,就得先研究数据的来源。尤其是对小型公司来说,往往需要更多外部数据辅助商业决策。如何在广袤的互联网中获取对自己有价值的数据,是许多公司一直考虑的问题。通常来说,存在以下几大数据来源:
➢ 企业产生的用户数据
如 BAT 等公司,拥有大量用户,每天用户都会产生海量的原始数据。
另外还包括 PGC (专业生产内容)和 UGC (用户生产内容)数据,如新闻、自媒体、微博、短视频等等。
➢ 政府、机构的公开数据
如统计局、工商行政、知识产权、银行证券等公开信息和数据。
➢ 第三方数据库购买
市场上有很多产品化的数据库,包括商业类和学术类,如 Bloomberg、 CSMAR、 Wind、知网等等,一般以公司的名义购买数据查询权限,比如咨询公司、高等院校、研究机构都会购买。
➢ 爬虫获取网络数据
使用爬虫技术,进行网页爬取,或通过公开和非公开的接口调用,获得数据。
➢ 公司间进行数据交换
不同公司间进行数据交换,彼此进行数据补全。
➢ 商业间谍或黑客窃取数据
通过内鬼渠道获取其他公司用户数据,或者利用黑客等非常规手段,通过定制入侵获取数据或地下黑市购买其他公司数据。此处内鬼泄漏远多于黑客窃取。
二、恶意爬虫的目标
从前面总结的数据来源看,第三方数据库购买或数据窃取的渠道都不涉及爬虫,真正属于恶意爬虫目标的,主要是互联网公司和政府相关部门的数据。
行业总体分布
通过对捕获的海量恶意爬虫流量进行标注,整理出恶意爬虫流量最大的行业 TOP 10 排行,详情如下:
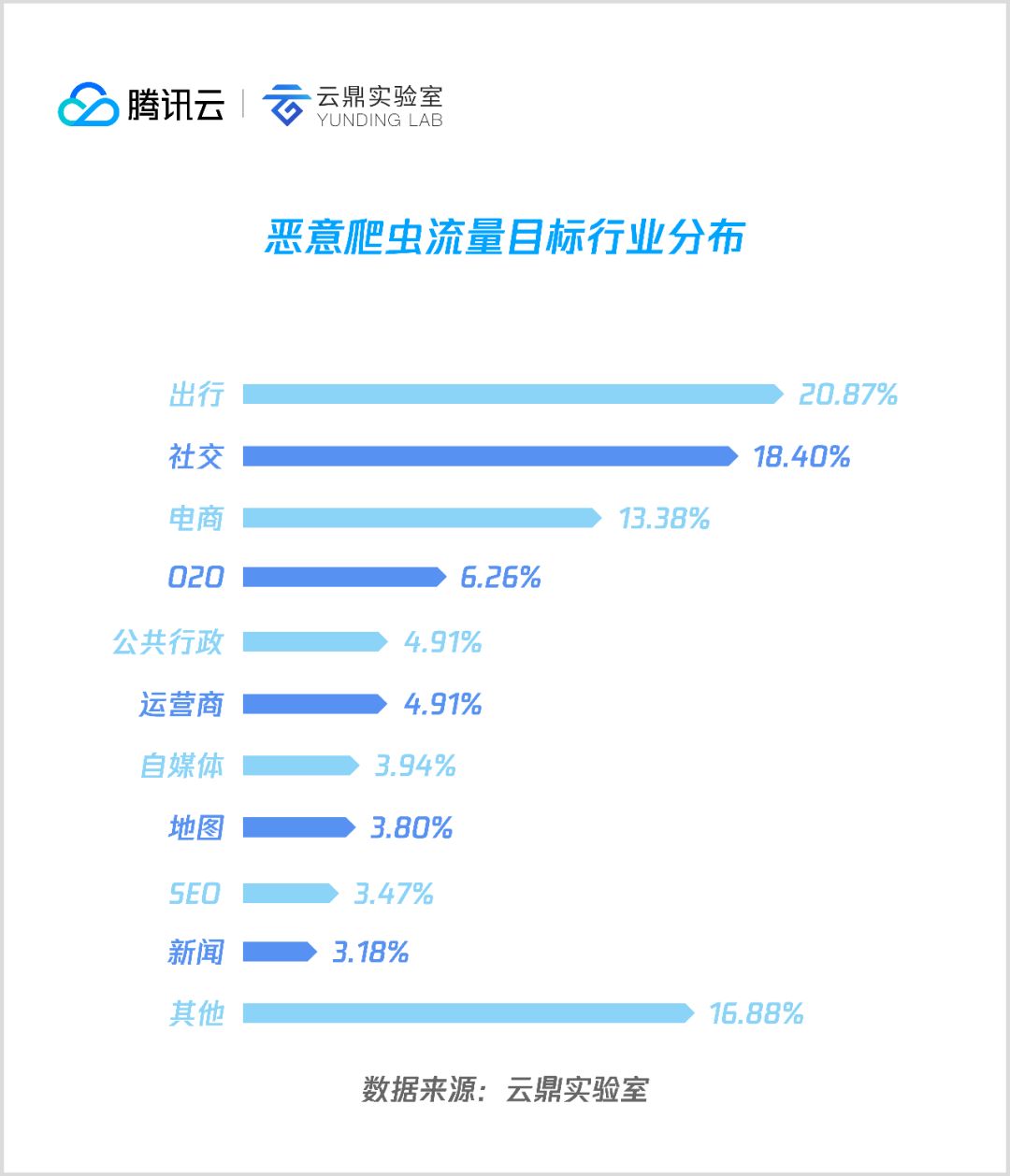
由统计可见,出行类恶意爬虫流量占比高于电商与社交行业,居首位,其次是点评、运营商、公共行政等。接下来逐个行业进行分析:
1. 出行
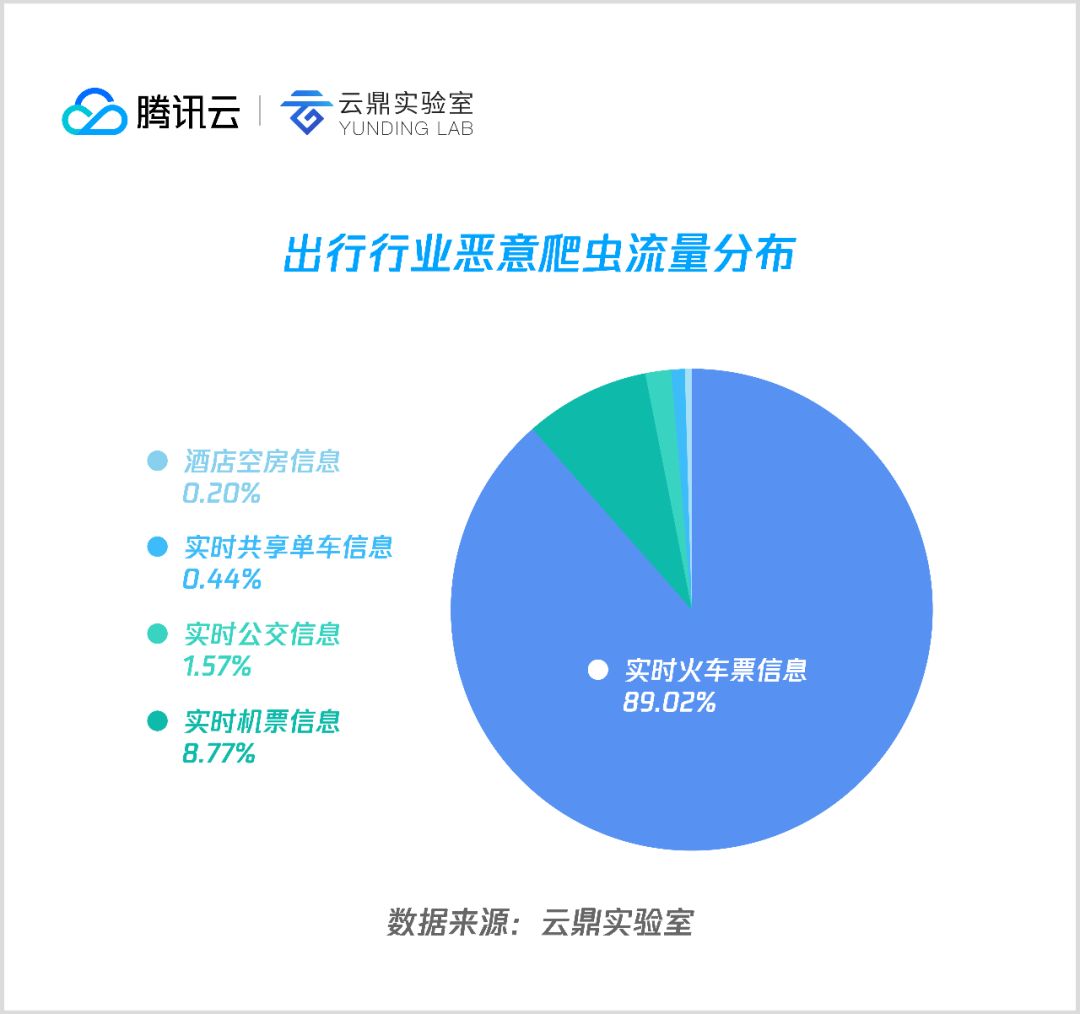
➢ 实时火车票信息
对火车购票平台的恶意爬虫访问占据了出行行业近90%的流量,浅析可知其实比较合理,几百个城市,几千趟列车构成国内铁路网,火车站与车次排列组合后是一个非常大的数据集,随着人工购票快速向互联网购票过渡,第三方代购和抢票服务商便越来越多,而任意一家要做到数据实时刷新,都需要不小的爬虫集群,因此导致火车票购买站点成为爬虫光顾最频繁的业务。
➢ 实时机票信息
机票类占据出行类8.77%的恶意爬虫流量,主要是爬取各大航空公司实时票价。
➢ 实时公交信息
主要爬取市内公交 GPS 信息。
➢ 实时共享单车信息
主要爬取特定区域周边的实时共享单车信息。
➢ 酒店空房信息
酒店爬取占比较少,主要是刷酒店房价,与交通类比较可忽略不计
2. 社交
由于国内的社交平台多数以纯 APP 为主,部分社交平台并不支持网页功能,因此捕获到的社交类爬虫主要集中在微博类平台,以爬取用户信息和所发布的内容为主。
3. 电商
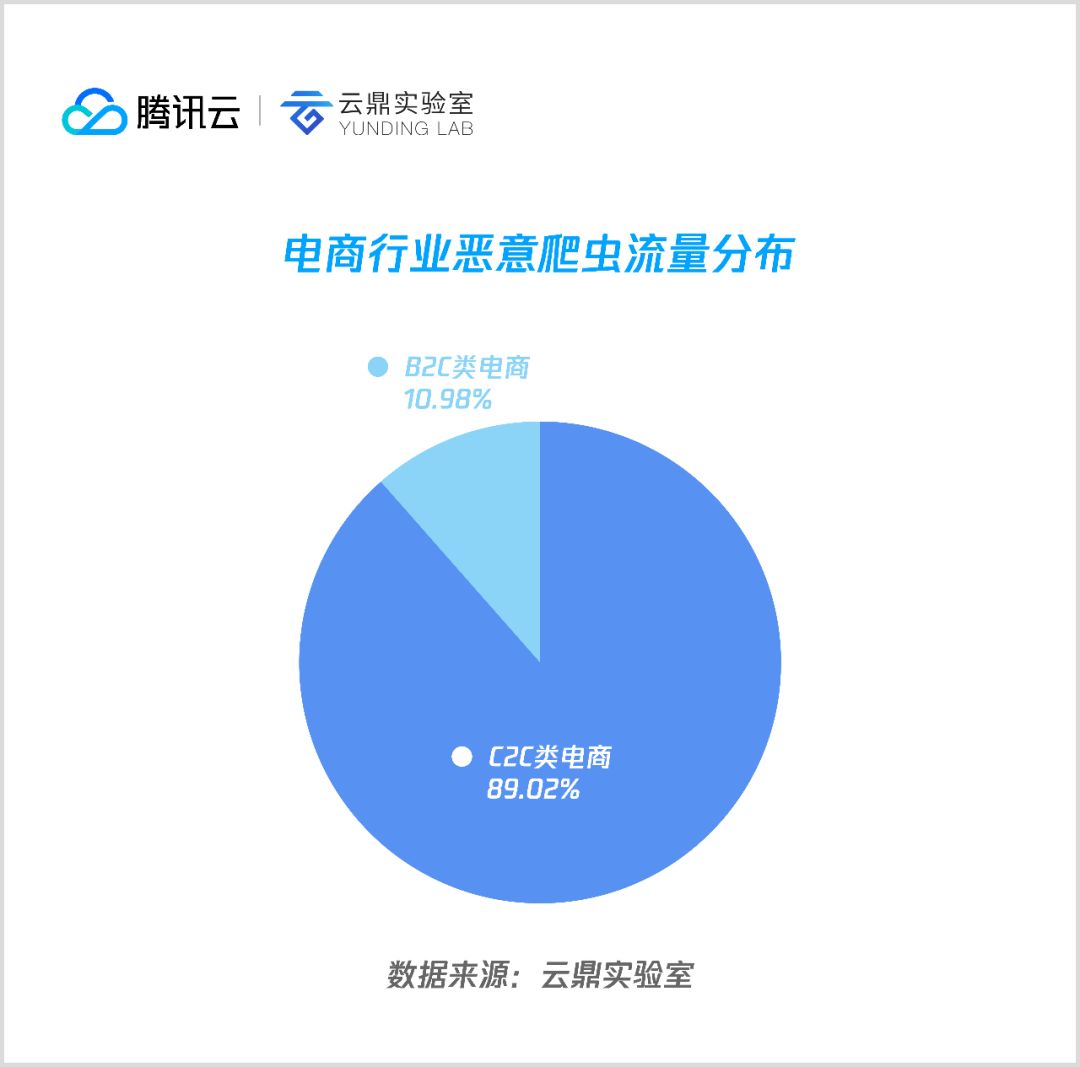
电商行业爬虫主要是爬取商品信息和价格等数据,由于商业模式的差异,C2C 类电商由于中小卖家众多,商品数量远多于 B2C 类电商,支撑了电商类恶意爬虫近90%流量, B2C 类电商加起来占一成左右。
4. O2O
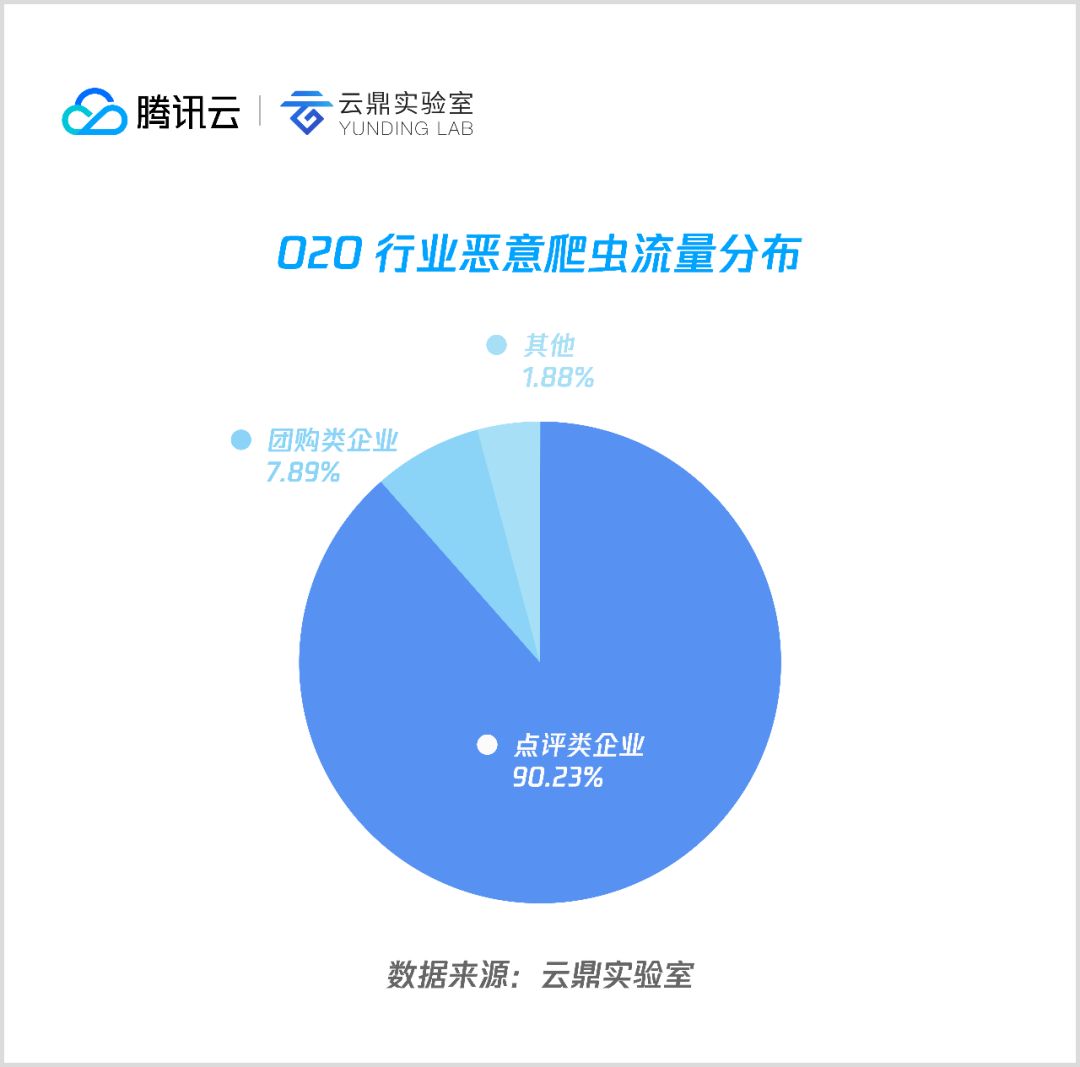
O2O 行业恶意爬虫主要集中在点评类和团购类公司,其中以爬取商铺动态信息和星级评分信息的点评类数据为主,占总数的90%以上。
5. 公共行政
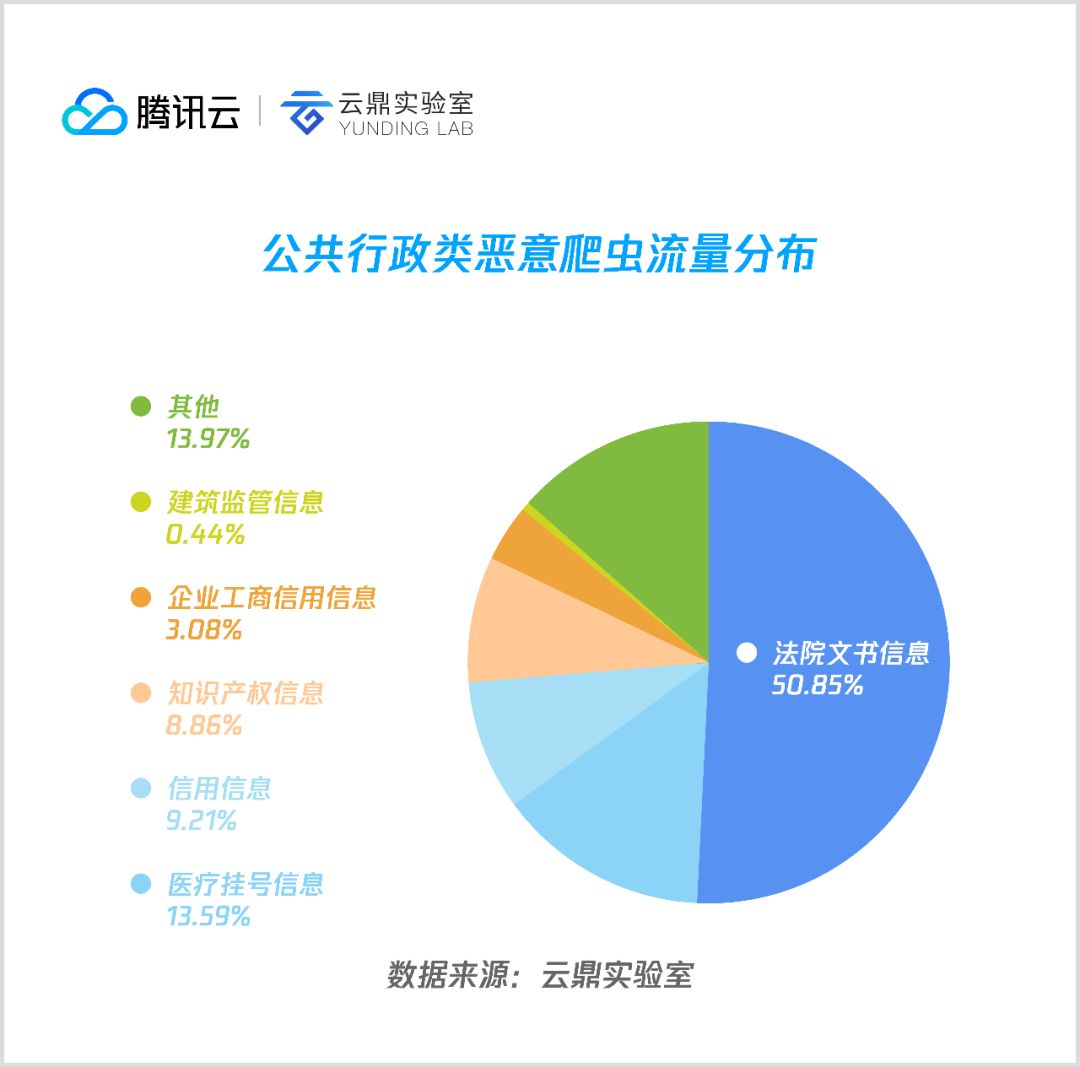
公共行政类恶意爬虫主要集中在法院文书、知识产权、企业信息、信用信息等常规商业信息领域,而另一个受爬虫青睐的是挂号类平台,从数据来看应该是一些代挂号平台提供的抢号服务。
6. 运营商
运营商的恶意爬虫流量主要集中在运营商各种互联网套餐手机卡的查询。由于互联网套餐手机卡存在较高的性价比,因此网络上形成了相关的刷靓号、抢号、代购等产业链。
网络上存在多种通过爬虫技术进行靓号手机号搜索的工具,选择手机卡类型,再不断爬取待售手机号,寻找到符合理想靓号规则的号码。下图为某扫号工具截图,可选择数十种不同的互联网套餐卡:
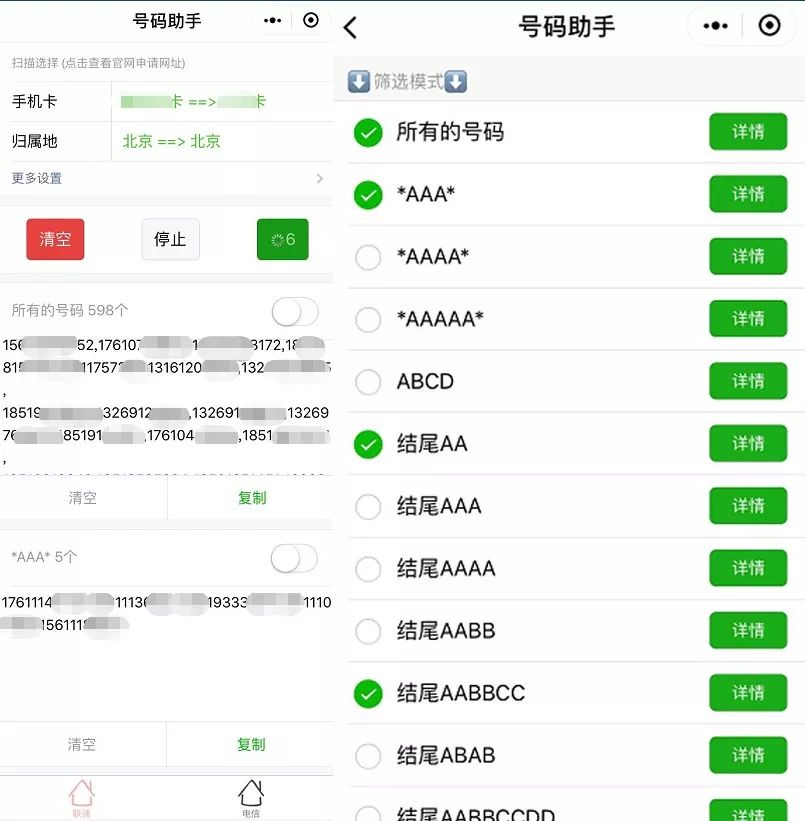
(某手机靓号扫号工具截图)
7. 自媒体
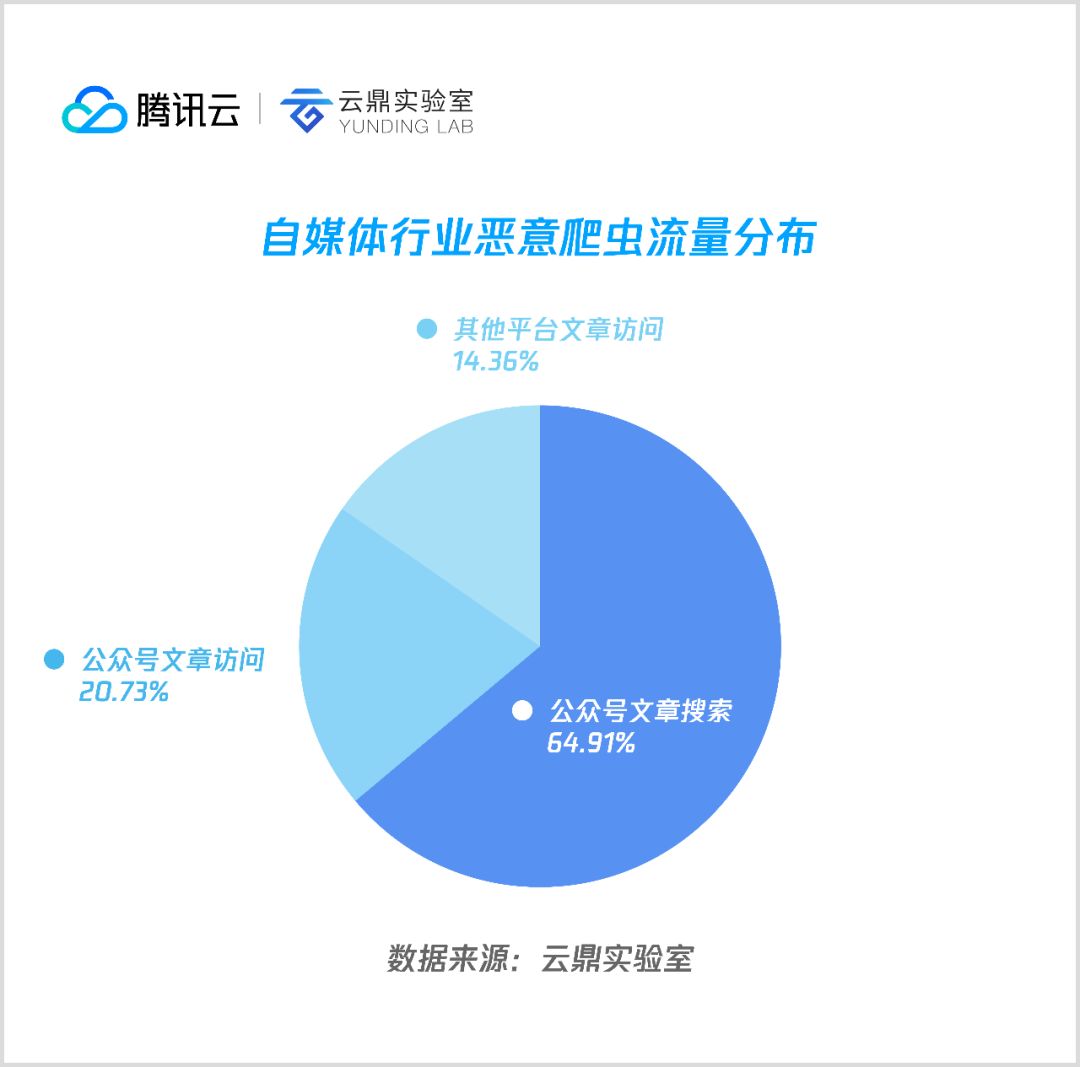
根据本次统计,自媒体类爬虫主要集中于微信订阅号关键词搜索和文章访问,分别占总量的64.91%和20.73%,其他自媒体平台约占14.36%。
8. 地图
地图类爬虫比较常规,主要是爬取地理位置周边商户详细信息为主。
9. SEO
SEO 类恶意爬虫通常是频繁搜索相关词汇,来影响搜索引擎的排名。
10. 新闻
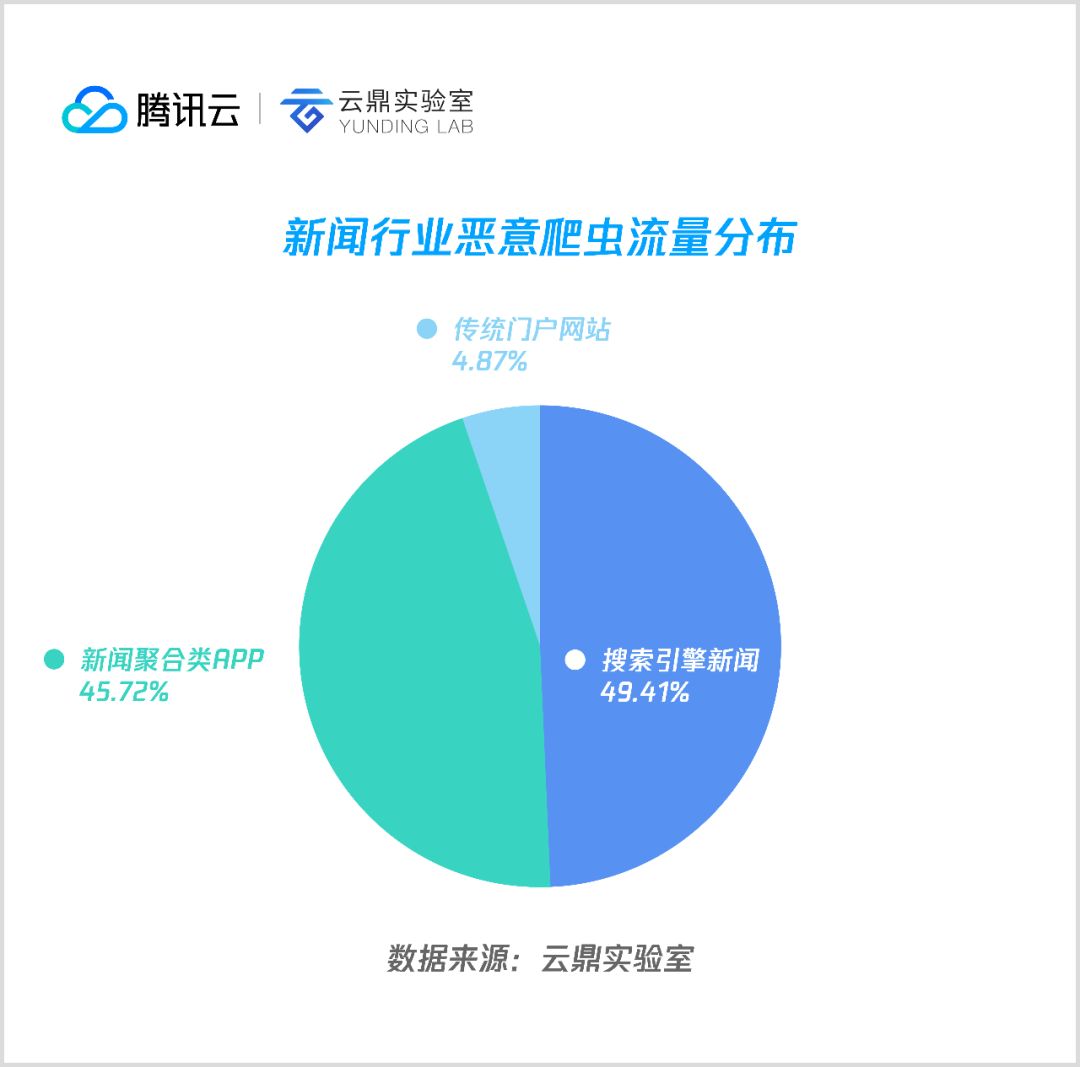
新闻类恶意爬虫主要用于爬取聚合类新闻 APP 及各大门户的新闻信息。以搜索引擎的新闻平台和聚合类APP的数据为主,传统门户类爬虫较少光顾。
11. 其他
其他主要被爬虫光顾的领域还有新闻、招聘、问答、百科、物流、分类信息、小说等,不进行一一列举。
三、爬虫来源 IP 分布
1. 国家分布
从本次半年度统计捕获到的爬虫流量源 IP 来看,大部分都来自国内,超过90%,其次主要来自美国、德国、日本等国家。
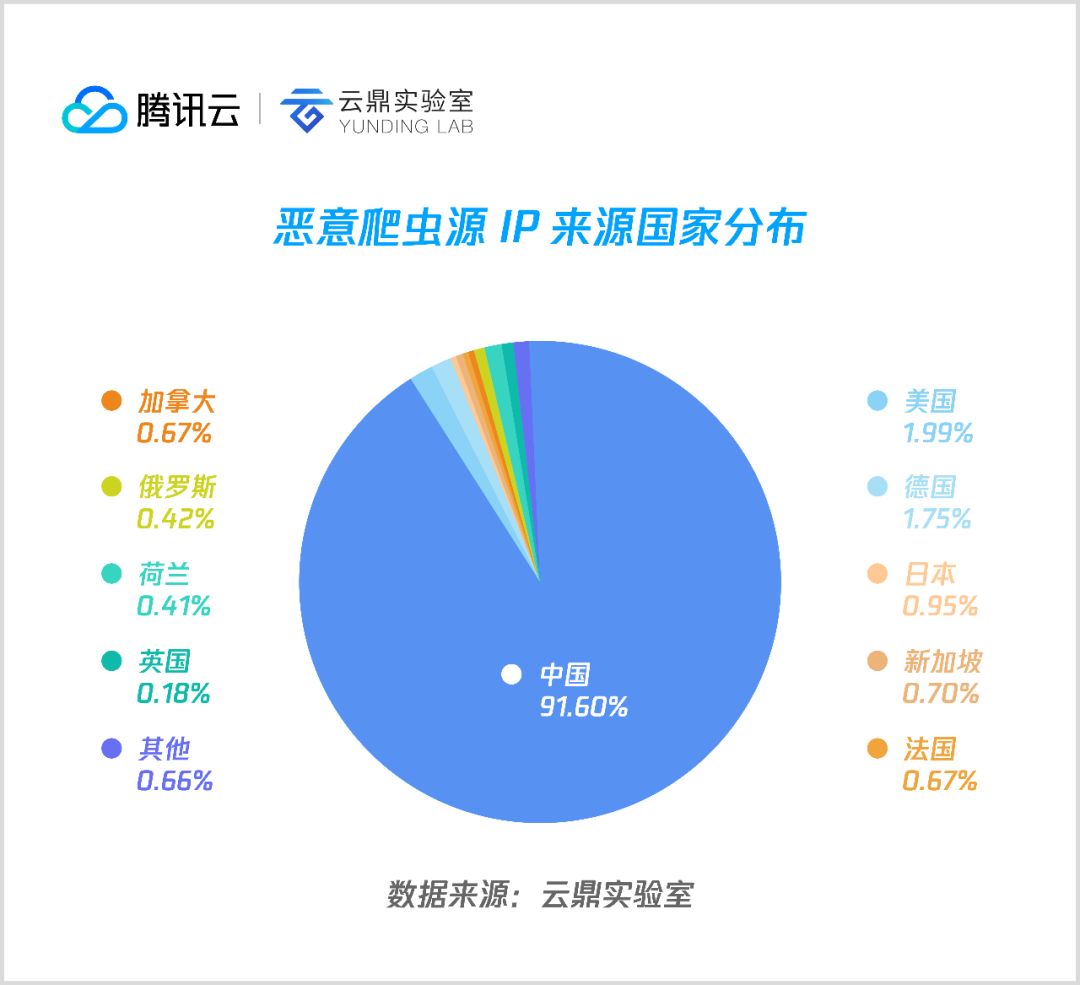
2. 国内分布
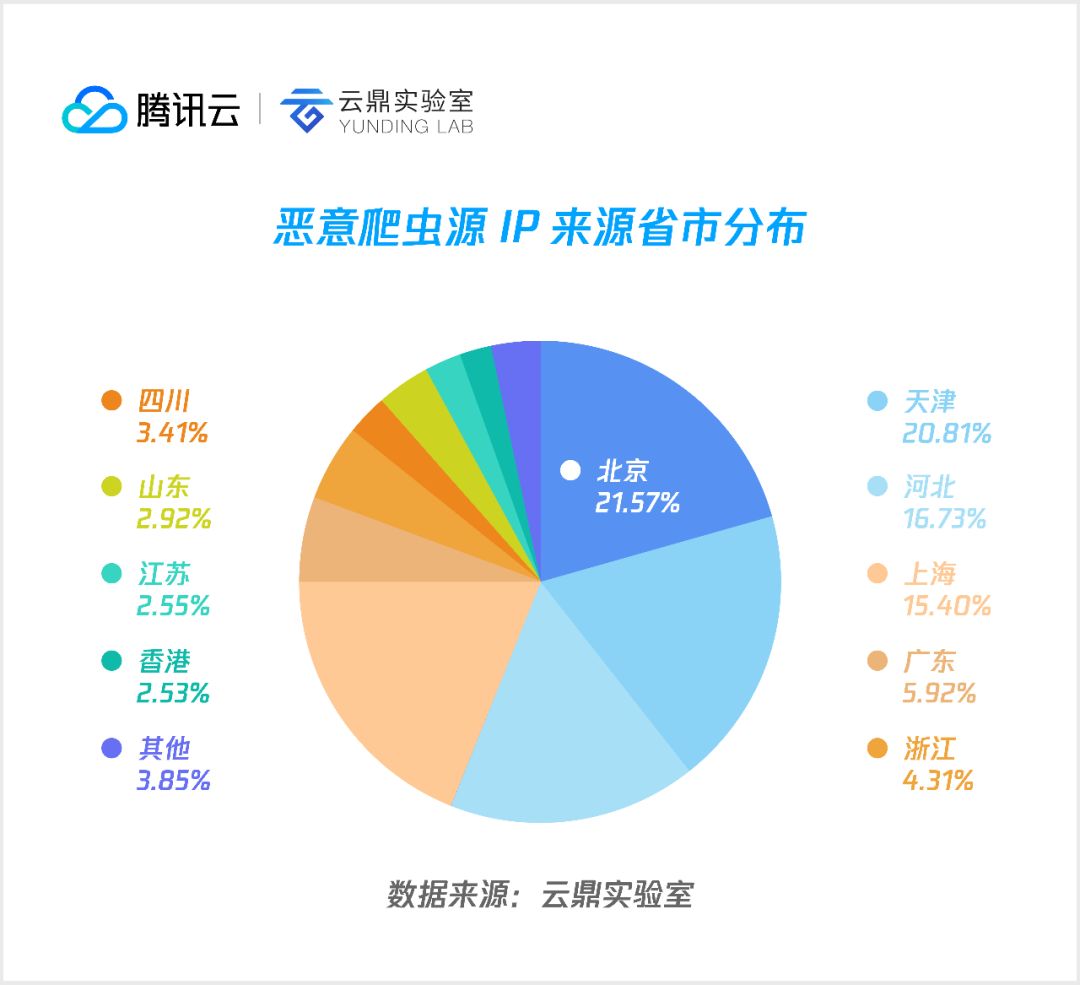
将源自国内的数据抽出来进行细分,可以看到,主要来自北京、天津、河北、上海等省市,以上4个地区所占国内恶意爬虫流量超70%。这并不是因为爬虫作者都来自这些地区,而是因为大量的爬虫部署在租用的 IDC 机房,这些机房大多在发达省市。
3. 网络分布
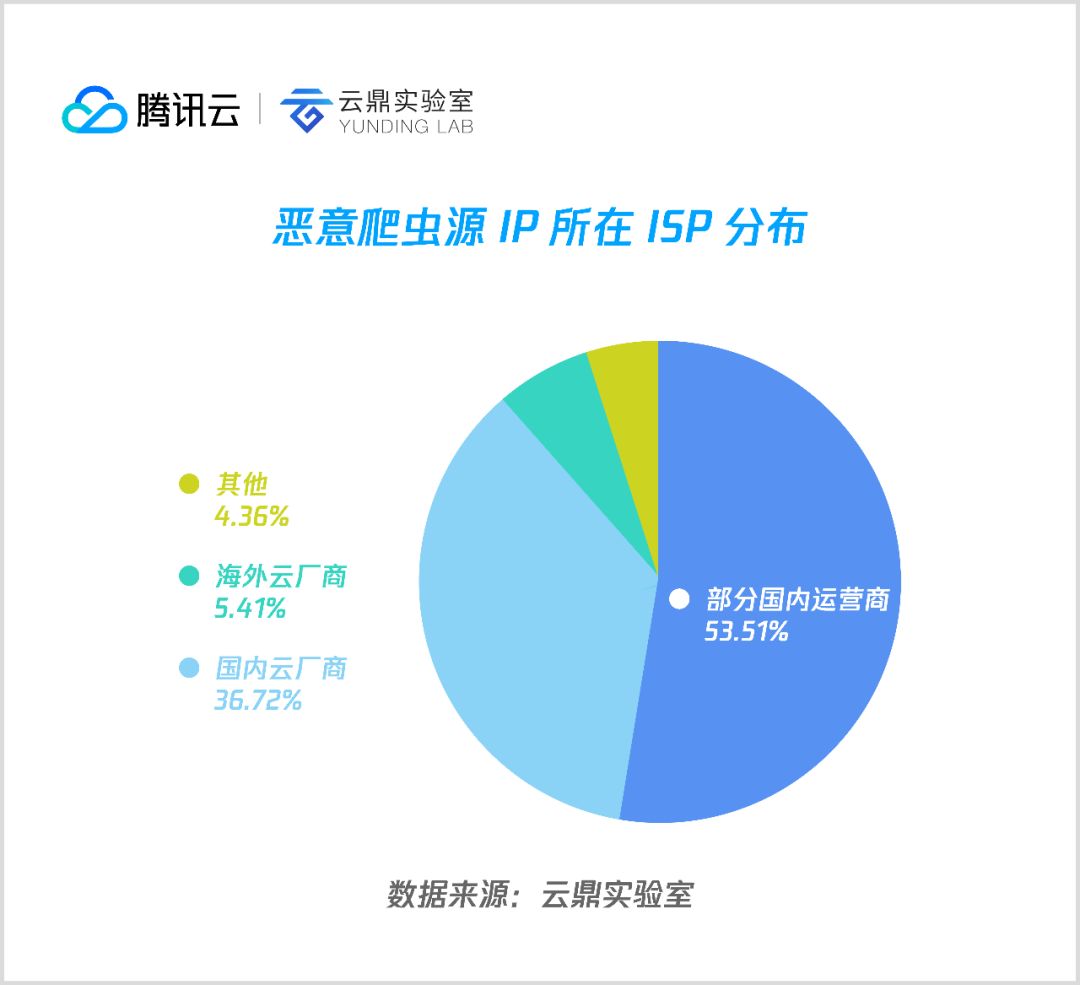
该图是恶意爬虫源 IP 的网络分布,可以看到,超过一半来自国内运营商网络,而这其中大比例是源自运营商的 IDC 机房。云计算厂商方面,国内主要云厂商都有上榜。
整体数据来看,恶意爬虫绝大部分都是来自 IDC 机房,随着恶意程序云端化,云计算厂商应当对云资源被滥用的情况进行及时了解和处理。
四、爬虫与反爬虫的对抗
作为互联网对抗最激烈的战场之一,说到爬虫,就不能不提反爬虫。当反爬虫工程师对爬虫进行了反杀,爬虫工程师也不会任人宰割,很快又研究出了各种反对抗技术。
1. 对手是谁
爬虫和反爬虫的斗争由来已久,要想做好反爬虫,先要知道对手有哪些,才好制定相应的策略。反爬虫工程师的对手通常来自以下几类:
➢ 应届毕业生
每年三月份左右通常会有一波爬虫高峰,和应届毕业生(本科、硕士、博士)有关,为了让论文有数据支撑,他们的爬虫简单粗暴,忽略了服务器压力,且人数不可预测。
➢ 创业小公司
初创公司缺少数据支撑,为了公司生存问题,爬取别家数据,不过通常持续不久,较易被反爬虫手段逼退。
➢ 成型的商业对手
反爬虫工作最大的对手,有钱有人有技术,如果需要,会通过分布式、跨省机房、ADSL 等种种手段进行长期爬取。如果双方持续对抗,最终的结果可能会是彼此找到平衡点。
➢ 失控爬虫
许多爬虫放于服务器运行后,就被程序员忘了,它们或许早已爬不到数据了,但依然会孜孜不倦地消耗服务器资源,直到爬虫所在服务器到期。
2. 技术对抗
犹如安全专家和黑客之争,爬虫工程师和反爬虫工程师也是相爱相杀、你来我往、螺旋上升。经过几番的技术升级,常用的反爬虫及对应的反反爬虫方案如下:
➢ 验证码
验证码是最常用的反爬虫措施,但简单验证码通过机器学习自动识别,通常正确率能达到50%以上甚至更高。
复杂验证码通过提交到专门的打码平台进行人工打码,依据验证码的复杂度,打码工人平均每码收1-2分钱。也同样容易被绕过,使得数据容易被爬取。
➢ 封 IP —— 最有效也最容易误杀的方案
这是最有效也最容易误杀的方案。该策略建立在 IP 稀有的前提下,目前通过代理池购买或者拨号 VPS 等方式,可以低成本获取数十万的 IP 池,导致单纯的封IP策略效果越来越差。
➢ 滑块验证
滑块验证结合了机器学习技术,只需要滑动滑块,而不用看那些复杂到有时人眼也无法分辨的字母。但由于部分厂商实现时校验算法较为简单,导致经常只需要相对简单的模拟滑动操作就能绕过,从而使得数据被恶意爬取。
➢ 关联请求上下文
反爬虫可以通过 Token 或网络请求上下文是否进行了完整流程的方式来判断是否真人访问。但对具有协议分析能力的技术人员来说进行全量模拟并没有太大困难。
➢ javascript 参与运算
简单的爬虫无法进行 js 运算,如果部分中间结果需要 js 引擎对 js 进行解析和运算,那么就可以让攻击者无法简单进行爬取。但爬虫开发者依然可以通过自带 js 引擎模块或直接使用 phantomjs 等无端浏览器进行自动化解析。
➢ 提高数据获取成本
当面对的是职业选手时,只能通过提升对方人力成本来实现,比如代码混淆、动态加密方案、假数据等方式,利用开发速度大于分析速度的优势,来拖垮对方的意志。如果对方咬定不放松,那只能持续对抗,直到一方由于机器成本或人力成本放弃。
当对抗到了这个阶段,与安全对抗一样,技术之争就进入了鏖战的「平衡期」,此时反爬虫工程师对抗掉了大部分的低级玩家,剩下的高级爬虫工程师也默契的保持一个不给服务器太大压力的爬取速度,双方犹如太极推手,那下一步如何打破这个平衡?
五、对抗新思路:云端 AI 反爬虫
爬虫和反爬虫的对抗,在云计算成为趋势后,逐渐加入了第三方势力,云计算厂商可直接为企业提供云端反爬能力,将战局从反爬虫与爬虫的 1v1 变成了企业+云厂商与爬虫 的 2v1,助力企业的反爬能力。
尤其是近年来 AI 技术不断突破,为解决许多问题提供了全新思路。基于这个角度,云鼎实验室通过深度学习技术对海量真实恶意爬虫流量进行分析,认为将 AI 技术引入反爬虫领域能起到极好的补充效果,将是未来此类对抗领域的趋势所在。
为此,腾讯云网站管家 (WAF) 联合云鼎实验室基于海量真实爬虫流量建立更为通用的爬虫识别模型,已卓有成效,后续将致力于把最强的识别能力开放给各企业。
声明:本文来自云鼎实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
