随着互联网的发展,数据已经成为人类现在最重要的虚拟资产。数据资产的整个生命周期包括采集、传输、存储、处理、交换、销毁等6个阶段。为了保护数据的安全,人们已经提出并实践了针对每个阶段的保护措施。如下图所示:

我们重点关注数据交换这个阶段。数据交换指的是组织之间发生的数据流入流出过程,包括单方面提供数据文件、查询数据、联合建模等。可以看到,在这个阶段,我们可以将数据脱敏后再进行交换,交换的过程中,必须有相应的管控流程,避免发生违规违法的交换;事后要有审计,以便追溯。
有了以上的保护措施,数据交换就一定安全了吗?事实并不一定。我们来看几个场景,并分析其中存在的风险点。
一、场景风险分析
场景1.数据查询

A公司要向B公司查询数据,提供待查询的ID,B公司则返回这些ID对应的信息。为了保护原始ID,AB会使用相同的方法将ID进行加密(比如使用HASH函数处理)。这个过程是否能够保证数据的安全呢?经过分析,我们认为其中至少存在如下3个风险点:
ID被破解:
由于ID的范围是固定的(如手机号、身份证、常见姓名等),可以通过暴力破解的方式碰撞出原始ID
ID沉淀:
B可以沉淀A提供的所有数据,暴力破解后用于其他用途
数据伪造:
B可能返回其并不真实存在的数据
场景2.跨平台会员营销
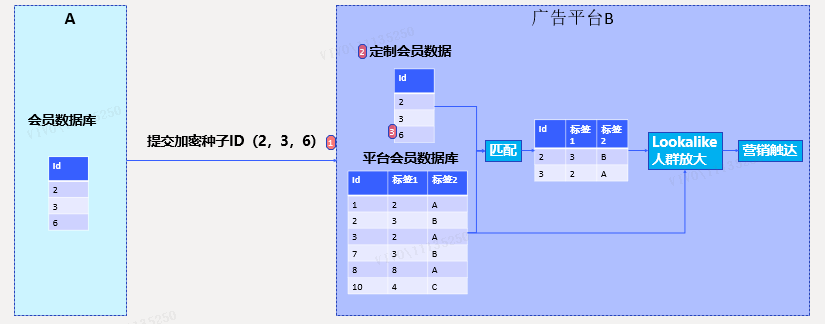
A公司要在广告平台B上进行会员营销,通常会提交A公司自身的会员包作为种子,在B平台上面通过匹配平台会员数据后进行lookalike放大,得到目标人群后再进行触达。种子会员包,广告平台一般都支持手机号、IMEI,以及经过HASH(如MD5/SHA)处理后的手机号、IMEI。即使A公司提交的是HASH后的ID,仍然存在如下风险:
ID被破解:
由于ID的范围是固定的(如手机号、IMEI等),可以通过暴力破解的方式碰撞出原始ID
ID沉淀:
B可以沉淀A提供的所有数据
数据超范围提供:
A流失了所有种子ID,其中某些ID由于B并不拥有,其实不应该向B提供这些ID
场景3.联合建模
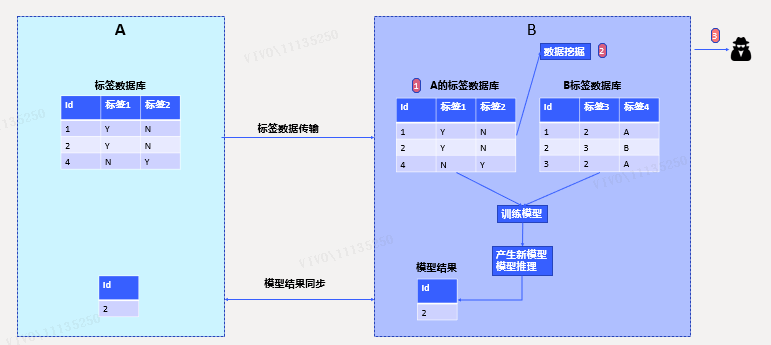
除了查询场景外,一种比较常见的数据交换场景是两方联合建模。这种场景下,一般都是某一方将数据提供给另外一方进行模型分析,或者在第三方提供的空间内进行模型分析。对于数据的保护,依赖对方/第三方数据保护能力,以及法律合同。
由于数据事实上已经脱离了A的掌握,可以看到至少存在3点风险:
数据脱离掌控:
数据传递到B,只能靠签订相关合同,由法律保证不被滥用
数据他用难查证:
B可以沉淀A提供的所有数据并自用,A难以发现并查证
数据安全事故连带负面影响:
由于B导致的数据泄露,仍然会给A造成负面影响
二、风险解决方案
综合上面的3个场景,我们可以看到,数据交换在目前的保护措施下,仍然存在一定的风险。因此我们有必要讨论如何进行安全的数据交换。
那么,数据安全交换到底是什么呢?
简单的说,就是“数据可用不可见”。使用数据的双方,相互间都不将原始数据提供给对方,同时又能够使用双方的数据进行模型分析。一句话,既要把数据留在本地,又要发挥数据的价值,还要用到别人数据的价值。
目前,业界为了实现数据安全交换,已经发展出来3种技术,包括多方安全计算、联邦学习、可信计算。
多方安全计算主要利用底层密码学协议来进行,包括有秘密分享、混淆电路、遗忘传输等等技术,主要特点是利用各种密码学协议来实现数据可用不可见。其最大的问题是效率不够高,难以支持大数据建模。
可信计算则通过构建可信的硬件计算环境来支持数据安全交换,使用芯片提供的独立安全环境,比如Intel的SGX,ARM的TEE等,将加密数据传递到芯片安全环境中进行解密计算,非安全环境的硬件、软件都无法访问。
联邦学习技术[2,3]则是一种更容易实现的联合建模方法,最大特点就是能够面向大数据进行联合建模,且效率较高,应用也最为广泛。联邦学习又可分为横向、纵向、迁移联邦学习,在实际应用中纵向联邦学习更为常见。
下面我们来看看,如何使用以上的技术,来解决上面我们提到的数据交换问题。
技术方案1. 安全求交集
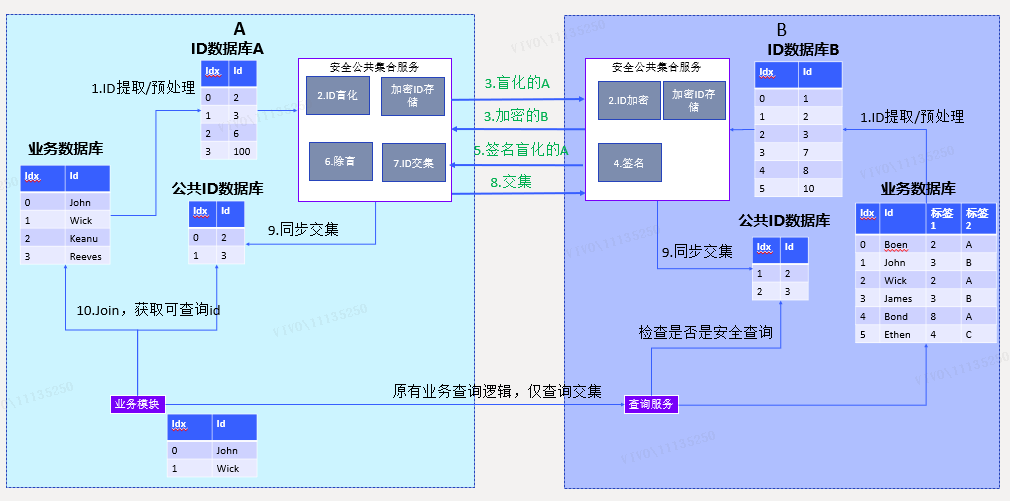
方案效果:A只向B查询双方业务数据库中都有的ID
方案说明:
(1) 将业务数据库中的ID预处理后加入到ID数据库中,预处理方式可以由业务方自行定义,只需保证一一对应即可。安全公共集合服务无需了解预处理方式,因此不会获取业务的任何ID信息。B产生一对RSA公私钥,将公钥发送给A。双方均使用相同的HASH函数;
(2) A将ID数据库中的数据进行盲化(盲化的定义请参考文献[1])处理,得到A_blind。同时,将自身的ID数据库中的数据用私钥加密并HASH处理,得到B_enc;
(3) A将A_blind传输给B,B将B_enc传输给A
盲化的A_blind技术保证B无法还原出原始的ID;
B_enc经过私钥加密并HASH,也能保证A无法解密出原始ID;
(4) B用自己的私钥,给A_blind签名,得到A_blind_sig;
(5) B将A_blind_sig传输给A;
(6) A将A_blind_sig除盲,然后HASH处理,得到 A_enc;
(7) A计算A_enc和B_enc的交集A_B;
(8) A将交集A_B传递给B;
(9) A将A_B里面的值,对应到A_enc的索引位置,然后将索引位置记录到ID数据库,有索引的位置即为公共ID;
(10) A将公共ID提供给业务,业务方根据预处理记录的对应关系,找到原始的公共ID;
(11) A向B查询原始公共ID。
技术方案2.安全种子营销
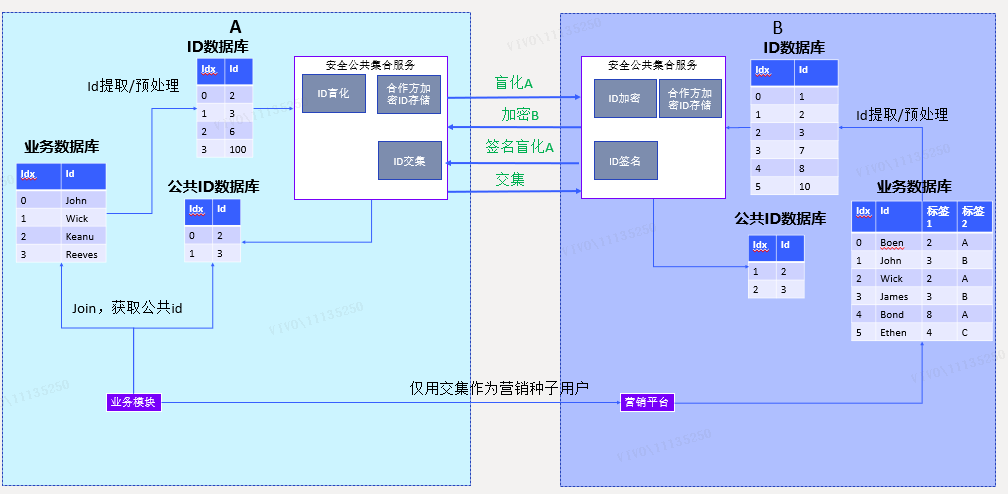
方案效果:A仅提供双方共有的用户作为营销种子包,不泄露任何B平台没有的用户
方案说明:
(1) 业务方A确定种子包,将ID预处理后加入到ID数据库;
(2) 经过与方案1中相同的过程,获得种子包中双方都有的公共ID;
(3) 将公共ID作为新的种子包,提交到营销平台进行营销。
技术方案3.纵向联邦学习
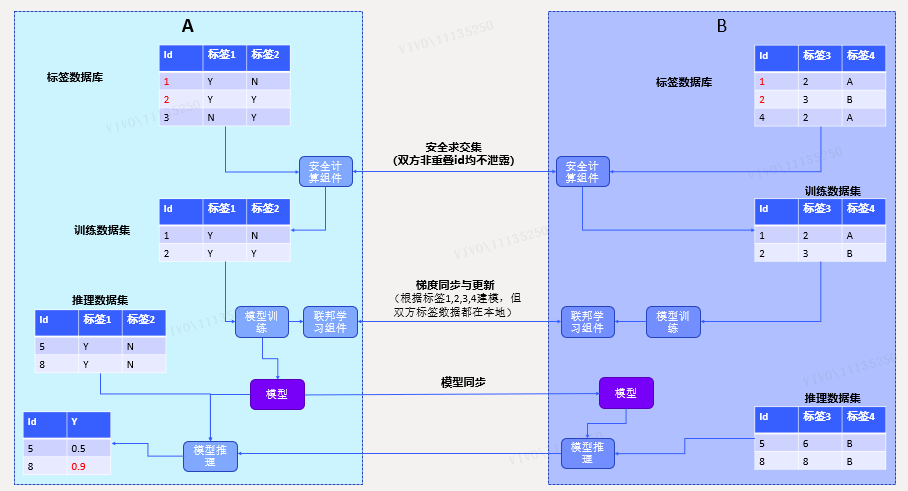
方案效果:联合建模双方保留原始数据在本地,仅交换建模过程中的梯度信息,实现“数据可用不可见”
方案说明:
(1) 通过安全求交集方法(参考方案1),获得双方的公共ID,后续的建模都基于这些公共ID;
(2) 将公共ID集合划分训练集和验证集;
(3) 使用联邦学习的方法[2],交换建模过程中的梯度数据,将原始数据保留在本地。
具体的梯度数据计算和迭代过程,和使用的算法相关。在实际应用中,需要对算法进行改造以适应联邦学习的运行模式。
(4) 联邦学习完成,得到模型,模型可能分为两部分,双方各持有一部分;
(5) 推理时,双方将各自的数据输入模型,得到模型部分结果后,将结果汇集到一方,得到最终推理结果。
三、总结
作为数据安全的从业人员,对数据安全的追求永无止境。本文从数据安全交换的角度,提出了几个方案,以实现在安全合规的前提下,最大限度的发挥数据流通的价值,减少数据孤岛的出现。其中肯定有我们所未能识别出的问题或风险,欢迎大家在评论区留言探讨,感谢大家。
文章引用
[1] https://en.wikipedia.org/wiki/Blind_signature
[2] https://en.wikipedia.org/wiki/Federated_learning
[3] https://zhuanlan.zhihu.com/p/94105330
声明:本文来自vivo千镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
