Hadoop的发展很快,目前很多企业都在用了。而在整个Hadoop安全上,据我了解国内企业一般都是采用置于内网的安全防护方式,但这显然不够,为什么不够:
第一是随着业务数据增多,在生产集群上包含着大量用户敏感数据,各类证件号银行卡号地址等数据。这些数据就算是内部使用流转,也具有很大的风险。
第二是随着国家相关法规的出台,对这些敏感数据的合规保护也绝非放在内网、设置权限就足够的。
第三从业务角度来说,一个大型互联网公司,必然存在着多个BU的数据交互,如果不能从使用、加工、分发等环节上保障安全,就会梗塞数据的流通价值。更何况很多互联网企业都在开展数据赋能、数据生态,数据涉及到投资公司、合作公司,甚至部分对社会公开,这时候原来的架构就需要对外开放。
第四,Hadoop自身漏洞并不少,我在官网搜了一下Hadoop漏洞相关内容,可以看到近年来漏洞讨论topic明显增多,其中包括若干CVE漏洞。但由于整个Hadoop生态的复杂性,涉及到上下游无数开源工具,很多漏洞常年得不到修复。换句话说,不存在一个标准化的Hadoop平台,都是根据实际需求各种“拼凑”出来,出现这种情况也就不足为奇。
一、大数据平台威胁
一般而言,大数据区域和数据流向见下图:

从完整的视角来看,大数据平台有这些方面的威胁:
1、未授权访问
攻击者/内部用户/外包用户/合作用户试图获取权限,老实说,面对大数据平台上这么大的数据诱惑,很多人(比如我)会像看到金子一样,这时候如果平台管控粒度不够,就会出很多问题。
对这类问题,首先是身份验证,集成Kerberos。如果是SSO集成也可以考虑使用Hue这种图形化接口。身份验证解决了能不能进入系统的问题。
其次要考虑权限,对HDFS中的文件和目录进行授权,也就是说你可以访问哪些资源。可以考虑Sentry这种组件,细粒度基于角色的安全控制。
最后就是审计,发现账户被盗或是内部攻击。
2、网络攻击
Hadoop上的问题主要在于数据被监听,这就需要在网络层面做加密。而Hadoop上的流量会比较错综复杂,有各种交互渠道,比如客户端常用的就有十多种,每种都有自己的通信协议。又很难一刀切的说,只允许用哪几种,每种客户端都有自己的业务特性,一刀切会给业务带来使用不便。
这个问题只有一个解,就是传输加密。Hadoop提供了SASL加密机制,但貌似和TLS结合有些问题,成熟度还不够,别问我怎么知道的。
3、静态数据获取
攻击的终极目标是数据,因此对磁盘上的数据加密很重要。而且Kerberos keytab文件也是存在磁盘上的,如果被人拿到,就可以伪装成各种身份进入。
解法有两种,一是应用级保护,可以通过加密、屏蔽、token化来保护。二是HDFS加密,数据在HDFS内本地加密。当然也可以做文件系统级加密,不过一般企业并无必要,前面两个做好足以应付绝大多数威胁情况了。
4、基础设施安全
涉及各种组件的漏洞修补,以及恶意节点加入。这就考验运维水平了,DevOps会减轻部署负担。
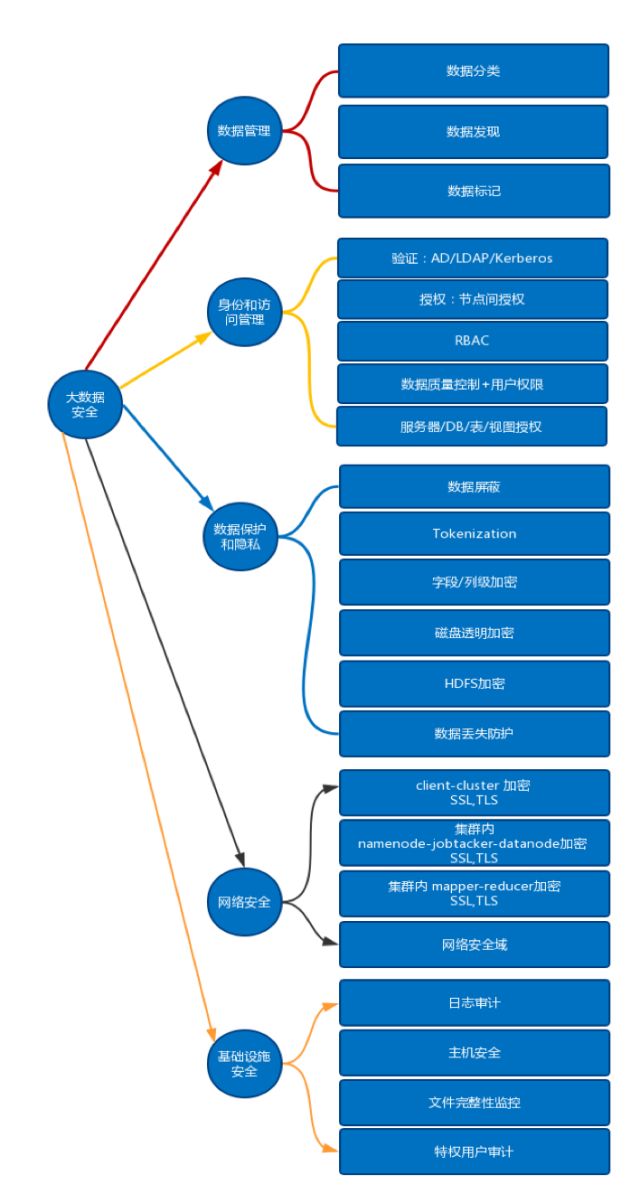
二、大数据安全视图
整个大数据安全可以分为五大类22个子项目:
三、数据管理
数据管理分解为3个核心组件:数据分类、数据发现、数据标记。
3.1 数据分类
数据分类有助于确定什么数据很重要,什么需要加密保护,优先保护什么数据。因此需要:
与知识产权、法务、财务、信息安全、HR等部门合作确认重要数据。
确定这些数据的位置,有权访问的用户和系统数量,确认安全控制手段。
对攻击者的价值,数据是否很容易在黑市交易?有没有很宝贵的知识资产(比如你有一份核反应堆蓝图)。
对合规和业务收入影响,包括银行卡数据这种特定数据泄漏会对业务产生影响,系统重构成本(例如采购新的安全产品),由于合规导致的罚款、法律诉讼费用。
对客户的影响,数据泄漏是否会导致钓鱼攻击?更新这些数据的成本?
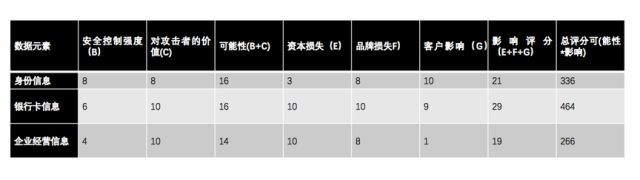
下面这个表格则是对风险评估的一个示例:
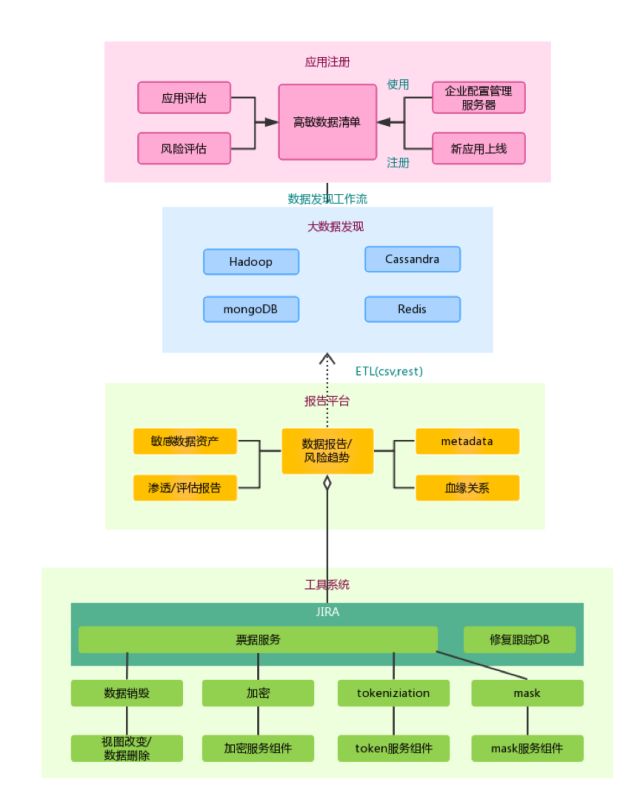
3.2数据发现
数据发现的目的是为了保护数据,数据都不知道在哪,就无从谈的上保护。对敏感数据进行mask、token化或加密。
对于结构化数据比较容易发现,也容易打标。但对非结构化数据就比较困难,需要一些机器学习和人工确认。
 3.3数据标记
3.3数据标记
掌握端到端的数据流,特别是整个大数据集群的入口和出口。
常见入口是这些,这些方法工具都会穿过meta层,具有copy、create和write能力。
1. CLI
2. Java API(+ Oozie)
3.pig
4. Datameer
5. Flume中的HDFS Sink
6. Impala ODBC / JDBC
7. Sqoop导入
8. SSH
9.批量ETL加载
而常见出口:
1. Hive查询(CLI,HUE,ODBC / JDBC,Oozie)
2. Impala查询(CLI,HUE,ODBC / JDBC,Oozie)
3. PIG作业(通过Hcatalog读取文件或Hive)-CLI,Hue,Oozie
4.MapReduce作业(Java MR,Streaming,Hive,pig)
5. Sqoop导出
6.文件copy(CLI,Java API,REST API,Oozie,Hue,Datameer)
7. Microstrategy - 连接到Hive&Impala
8. Tableau
9. HUE Web UI
跟踪数据,并使用发现功能进行标记,确保所有入口、出口都有RBAC 和审计,这些动作也有会对数据发现有新的帮助。
3.4数据管理总结
对敏感数据扫描,识别和分类。
收集指标,例如数量,UV,条件搜索(CC + zip)。
在Hadoop集群中记录数据结构,从序列和分隔文件转移到像Apache Parquet这样的列式存储格式。
数据保护(例如加密,token化等)。
数据压缩算法(例如压缩比较大,但较慢的I / O - gzip)。
了解端到端数据流,特别是入口和出口方法。
四、身份和访问管理
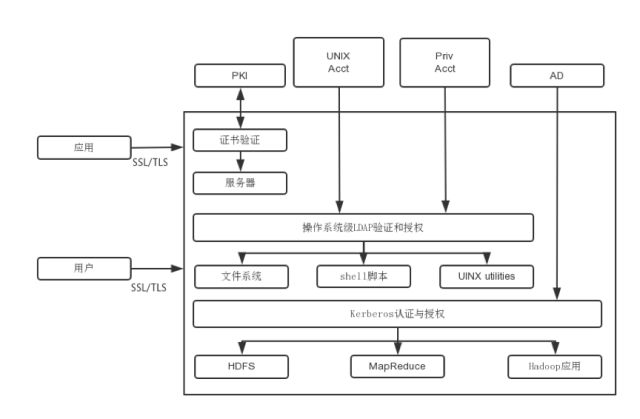
用户:
集中管理提供用户访问权限,权限策略是基于数据敏感级别的,而不是访问方法,从内网进入并不代表安全。
RBAC授权:基于角色授权(而不是用户)。
授权:
基于属性的访问控制和血缘关系的数据保护, 权限决定可以结合用户、环境(例如位置)和数据属性。
使用多因素认证进行管理访问,不同角色之间职责的分离。
使用工具:
禁止终端用户直连nodes,只允许命名nodes(可以使用Apache Knox)-Apache Sentry是一个管理RBAC不错的工具很,它可以利用AD来自动确定用户的组分配,并保持权限实时更新。
保护Kerberos群集中的keytab。
keytab(密钥表的缩写)包含服务用于向KDC进行身份验证的凭据(服务密钥),攻击可以通过复制keytab来模拟根或应用程序ID,可以理解为类似于用户名密码一类的关键信息。因此,keytab只允许被root(root要受控)读取,对keytab进行监控,keytab的传输必须在加密网络中进行,磁盘需要进行加密。
基于行为识别:例如根据用户行为、应用行为来限制数据的查询量。
五、数据保护和隐私
Hadoop发行版现在都提供了块或者文件级加密,但对应用级别的加密目前并非默认。
1、静态数据的保护
在应用层,如果不能加密的话,则要控制好验证、授权机制或使用tokenization。读取期间、批量使用时均需保护数据,并使用HSM管理加密密钥。
在HDFS层进行透明加密,保证在读取和写入的时候都是加密的,这种方法适合于全新的环境下开始。防止文件系统和操作系统攻击,使用外部密钥管理。如果性能要求较高,则考虑AES-NI硬件加速。
全磁盘级加密可以防止对磁盘的未授权访问,也可以防止特权用户在操作系统级别的访问,例如从集群中更换硬盘就是一个场景。全盘透明加密可以保证数据非人类可读。磁盘位于应用和文件系统中间层,是已有数据加密的最佳选择,同时也要进行基于流程的访问控制,磁盘加密也可以保护元数据、日志和配置文件。同样建议使用外部密钥管理。
2、隐私
要根据不同的威胁模型来考虑,数据中心、云、外部、内部大数据平台有不同的威胁。
需要保护所有数据(结构化,非结构化,元数据,文件)。
隐私需要考虑不同类型的用户、不同类型的数据、不同的敏感级别。
注意加密对下游数据调用的影响。
对隐私数据的处理可以使用mask、token化,确保在使用中没人能接触到敏感数据,最佳的隐私保护方法建议Tokenization。
隐私保护目前的集中加密算法都还在完善成熟中,FPE是一种保留格式的加密,也就是原来是8位,加密后也还是8位,算法上将其分割为密钥空间和消息空间,适合于类似于手机号、身份证这种标准化的整数数据加密,VOITAGE在其产品上使用了这种算法。而NIST则推荐了FFX算法,适用范围更广。
字段加密可以提供更细的安全粒度和审计跟踪,但需要人工干预以确定敏感字段。
3、加密
中央密钥管理,服务器管理加密密钥,密钥与数据分开。除了加密密钥,还包括SSL证书,SSH密钥,密码和Kerbero keytab文件。
使用标准加密技术,不要自己造轮子。尽可能利用硬件级别的加密, 例如英特尔优化的AES NI。
根据加密完成的位置确定瓶颈(本地,远程)。
对于加密,根据加密完成的位置确定瓶颈(本地,远程)。支持不同类型数据的个人加密密钥(例如PCI,PII)。
六、网络安全
网络安全可以分为数据传输保护、分区保护:
6.1数据传输保护
数据传输过程中面临多重威胁,攻击者可以监听Hadoop控制台的数据,也可以监听NameNode、DataNode、客户端通信,再可以获取Kerberos令牌然后伪装成NameNode。因此需要使用TLS协议验证并保护。
所以在这里:
客户端到Hadoop集群间的加密,TLS。
集群内使用TLS ,也包括namemode到DataNode之间的加密。
mapper-reducer的TLS。
使用LDAP SSL(LDAPS)而不是LDAP,防止嗅探。
配置并启用HDFS,MapReduce,YARN,HBase UI的TLS / https。
6.2网络区域保护
使用网络分层的访问控制,限制流量。
最终用户不能直连datanode,但需要连接nameode。
Apache Knox是个网关,支持Hadoop的流量控制。用户只需要和NameNode或Knox网关通信,永远也不需要直接和datanode
虽然可以通过负载平衡、抗ddos缓解拒绝服务攻击,但Hadoop不提供本地防护措施。这里的拒绝服务攻击不仅限于网络层,也包括集群上作业洪泛,或耗费大量资源的作业。
七、基础安全
基础设施层有4个组件,日志/审计、SELinux、文件完整性监控、特权用户监测。
7.1日志审计
Hadoop是一个独有的系统,需要审计的内容:
添加/删除数据管理节点。
管理节点的变化,包括jobtracker node, namenode。
集群节点变化。
Hadoop的日志数据比较分散,碎片太多,因此导致了管理问题,几个工具:
Apache Falcon:侧重于数据管理,图形化的血缘关系管理来控制数据生命周期。
Cloudera Navigator:可以解决日志蔓延问题,元数据自动抽取、数据溯源。
Zettaset Orchestrator:支持多个Hadoop的分布。
7.2 SELinux
Linux的系统一般使用DAC(自主访问控制), 而SELinux更安全,是MAC(强制访问控制)机制。
即使用户更改目录中的任何设置,策略也会阻止其他用户或进程访问。
防止命令注入攻击:例如使用x但不包含w的lib文件,反之亦然。
写入/ tmp,但无法执行。
八、总结
一些关键的建议:
有经验的大数据供应商,并且对安全上有见解,在安全控制手段上有实际经验。
从以网络为中的安全转向以数据为中心的安全,至关重要。
以数据为中心的安全,敏感数据优先。安全控制深入数据或应用级,而不是事后管理。
利用数据掩码、屏蔽、标记化手段细粒度的控制数据。
日志和审计扩展,使用例如Apache Falcon,Cloudera Navigator 或Zettaset Orchestrator。
翻译自:https://www.blackhat.com/docs/us-15/materials/us-15-Gaddam-Securing-Your-Big-Data-Environment.pdf
声明:本文来自唯品会安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
