
分享嘉宾:陈奕安 腾讯 TEG数据中心
编辑整理:Frank
出品平台:DataFunTalk
导读:大数据行业进入2010年以后,很多公司,很多行业都围绕一些独立开源的大数据组件在做各种开发,例如说spark、flink或者hbase等;但是当时间来到2020年以后,我们发现单纯的、单一的大数据组件已经很难满足腾讯、阿里、网易、滴滴等大型互联网公司对数据的需求;数据的分布也是非常讲究的,有私有云、公有云、还有一些与公网隔离的集群。那SuperSQL是怎么跨引擎、跨DC去计算这些复杂的数据?
本文将围绕以下几点进行展开:① 背景目标;② 业界竞品;③ 系统架构;④ 元数据管理;⑤ 跨源SQL算子下推;⑥ 分布式计算引擎;⑦ 跨DC查询优化;⑧ 性能评测;⑨ 未来规划。
01
背景目标
1. 问题与挑战
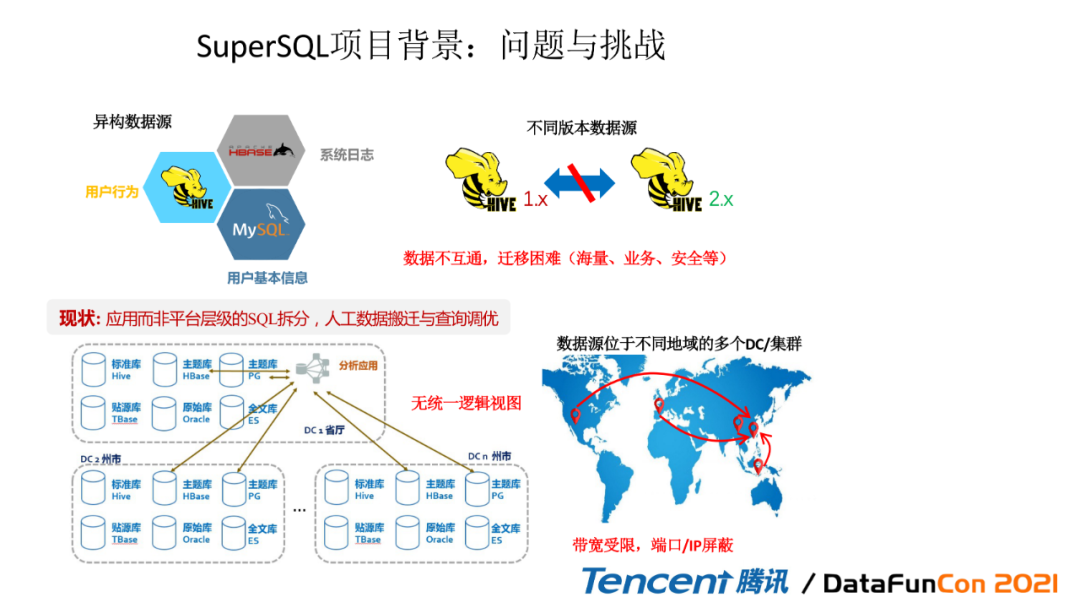
首先我们讲解一下整体的一个背景目标,就说SuperSQL,它在诞生的时候,它就面临着很多业务上的挑战。
异构的数据源
异构的数据源版本。比如说hive1.0跟2.0,那是不通的,同一套语言是不能用在两个不同版本的系统上
数据源位于不同的DC:假如说因为现在像GDPR(欧洲数据保护法)和中国数据法,美国的数据法都要求数据是不能离开本国,所以就诞生了这么一个新的需求:怎么去做一个能够满足不同数据中心,不同数据源的一个联合分析和即时查询?所以呢,在整个在腾讯整个天穹大数据的一个图谱中,SuperSQL是负责存储端和计算端的。
2. SuperSQL落地成果:支持跨业务平台(一)
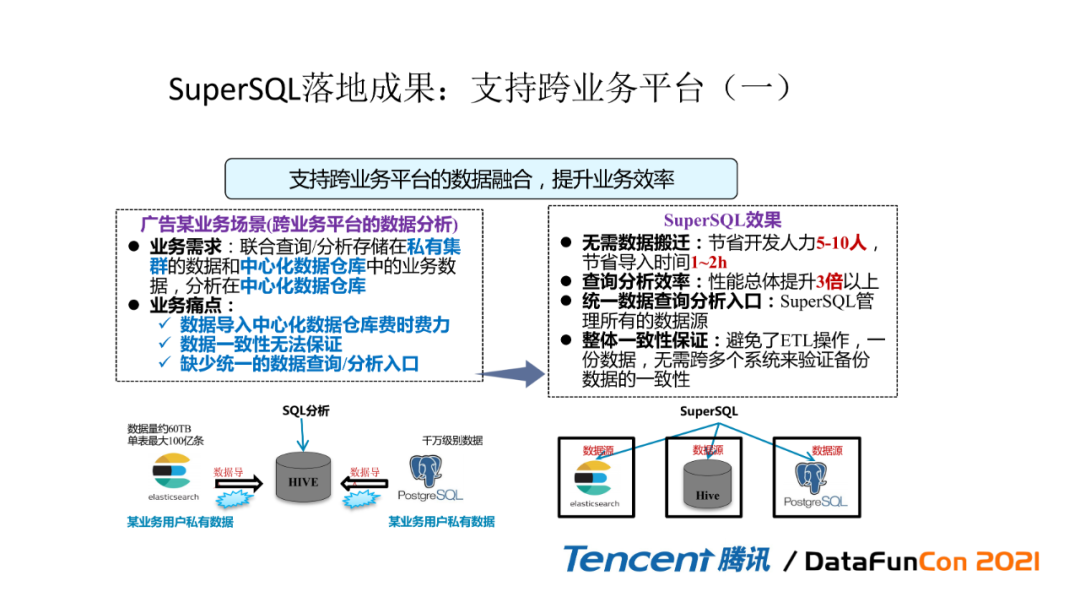
这里介绍一个具体业务的需求与成果:某广告业务他们的数据是存在一个私有的一个集群,包括一个中心化的一个数据仓库,就理解为hive,然后有另外一方他们的数据是存在他们自己的一个中心化仓库里面。那这样做查询或者做计算就有一个痛点,首先要把数据导入一个中心化的数据仓库中,然后没有办法保证数据的一致性,同时也缺少一个统一的查询分析入口。所以这些都是痛点。但是在我们SuperSQL推出以后可以提供以下能力:
节省数据迁移能力:节省开发人力5~10人,节省导入时间1~2h
提升查询分析效率:性能总体提升3倍以上
统一的数据查询分析入口:管理所有数据源
解决了数据一致性问题:避免ETL操作,一份数据,无需跨多个系统来验证备份数据的一致性
3. SuperSQL落地成果:支持跨业务平台(二)

第二个需求,是需要跨计算引擎进行计算,上面案例讲的是跨数据中心,假如说我们的数据是在历史的一个数据仓库里,比如是Hdfs,那现在我们需要把这个数据打到Clickhouse里面,Clickhouse是我们非常流行的Olap计算引擎,那么这里又有一个痛点,数据需要出库到一个业务平台,然后这里涉及到一系列的etl变换操作,需要依赖各种各样的工程师,同时你还要保障数据任务的运行质量,这里就面临着一个开发工作;SuperSQL上线以后,从数据到业务平台,只需要用SuperSql处理数据,中间无需落地,节约了导入时间,同时维护非常简单,还把各个系统解耦,不需要让他们把数据流转到一个中心化的数据仓库中。
02
业界竞品
1. 业界竞品分析:开源软件
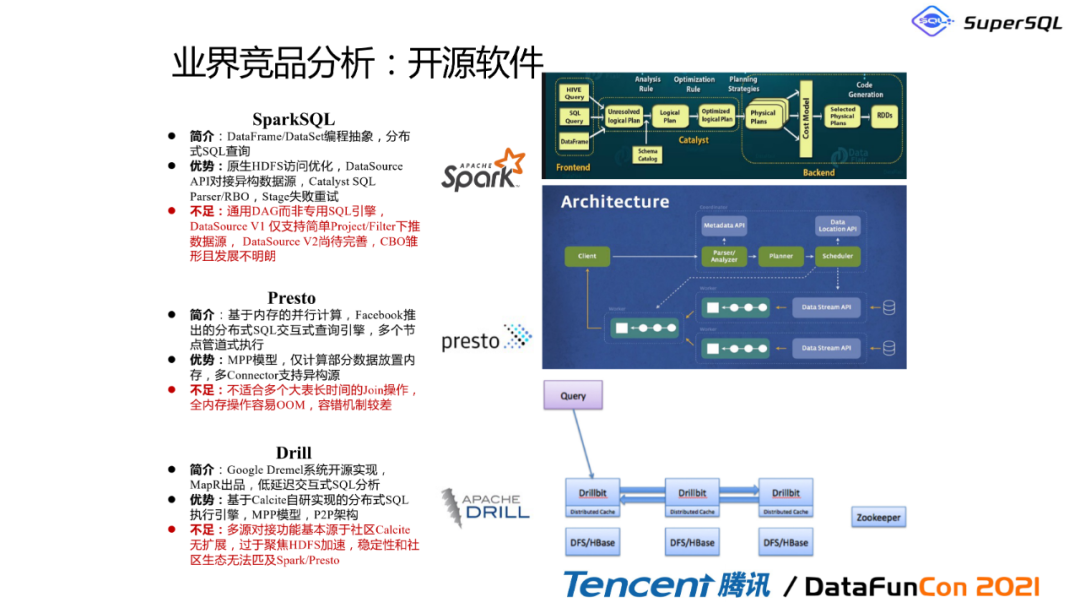
根据我们这边的调研,目前整个业界竞品比较类似的有那个SparkSQL\\Presto和Drill,但是这些引擎它们更多的是针对某一个计算范式而研发的:
Spark它有很多不足,那SparkSQL还有很多不足,因为它用的是DAG,它并非是专用的SQL引擎,所以它有非常多的api,但是那种标准SQL是不支持的
Presto是Facebook的一个分布式计算引擎,但它并不适合特别那种大的一个join查询,然后特别容易oom。这个在大公司经常做这种大型查询业务的话,是肯定有体验的
Drill其实是基于Calcite框架,但是它并没有直接对接那个不同引擎的一个功能,所以它的一个生态是又比不上Spark和Presto
2. 业界竞品分析:开源扩展
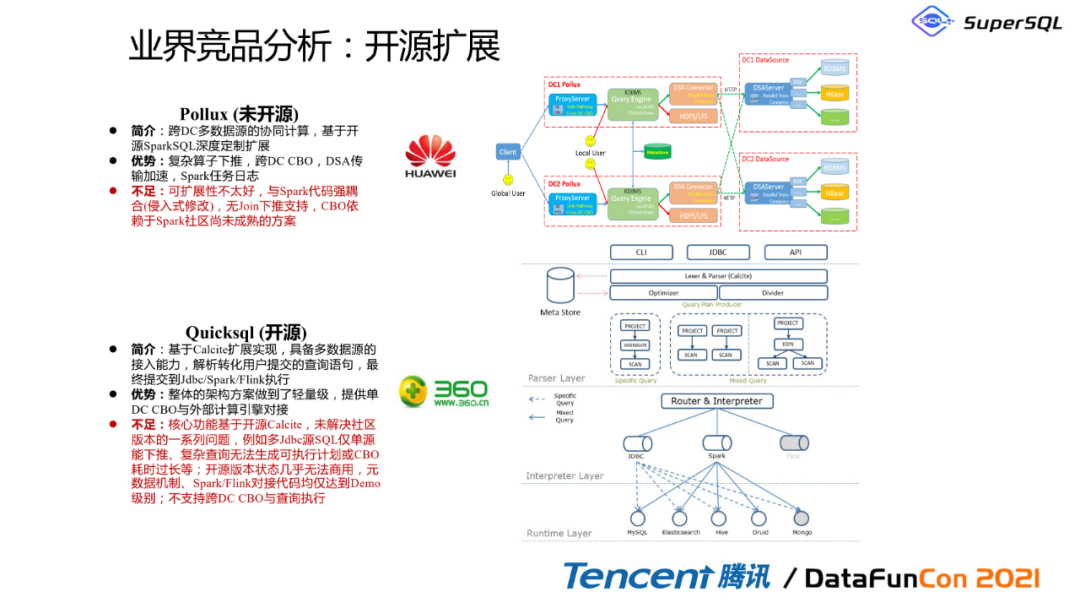
微软、华为、360公司也都有自己的一个产品:
华为Pollux的扩展性并不好,而且他其实还没有完全开源,所以我们对它的了解也并非常充分;
QuickSQL也是基于Calcite的计算框架,但是它目前仅支持那个Jdbc单源下推,没有办法做到一个联邦多元下推。
3. 业界竞品分析:私有系统

Google的F1-query是号称非常强大,但是它现在仅用于内部的Oltp场景,相关的文章并不多,也没有开源;阿里的Data Lake Analytics,但是阿里的DLA没有办法灵活的管理数据源之间的这么一个层级关系,下文会再提到,我们是如何利用这种一个Trie的树状结构去管理这么一个数据源的一个层级关系,这种结构对于跨引擎的联邦计算来说是非常重要的。
4. 业界竞品分析:华为河图

然后这里还有一个华为的河图,当时在调研的时候,没有开源非常多的内容,所以也没有性能数据测试等这些信息。
5. 业界竞品分析:Contiamo Workbench

其实国外也有竞品,比如说Contiamo是一个德国”Start-up“公司的,他们其实采用基本的技术方案,其实是跟我们SuperSQL都是比较类似的,包括前端也是有类似Webui的可视化组件,但他们这个公司也没有开源
6. SuperSQL vs. 商业竞品:更丰富完善的功能
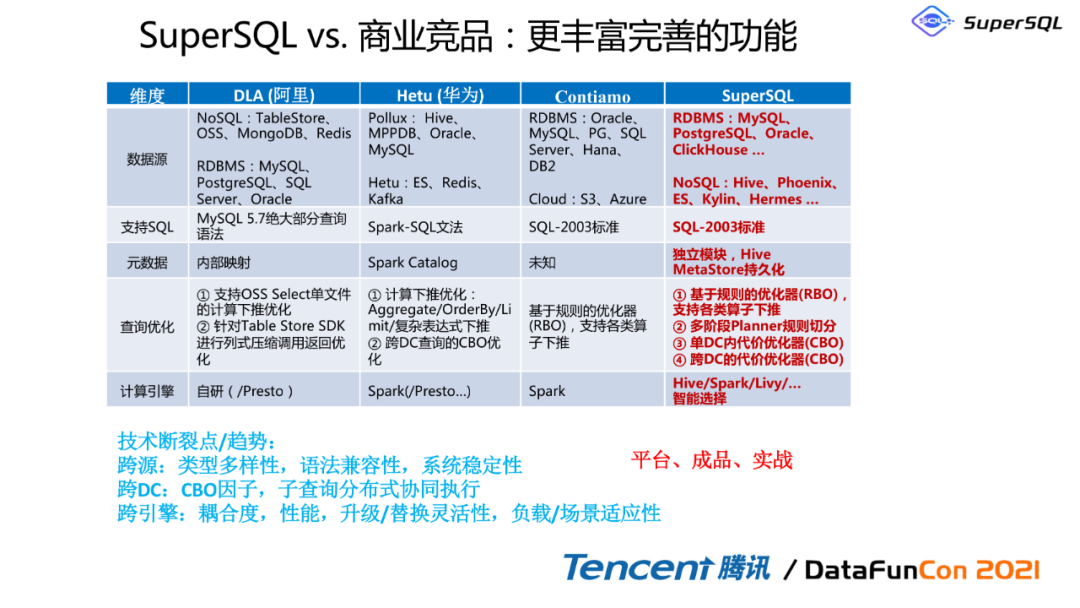
这边做一个表格对比,从这个表格里面来看,我们可以知道SuperSQL第一个亮点是可以基于这个规则的优化器,将各类计算下推,而不是把单源计算下推;第二个是可以基于CBO的优化,同时下面可以对接各种各样的SQL,只要它支持Jdbc协议;同时我们还有元数据模块,像有些竞品是并没有元数据模块的。
03
系统架构
1. SuperSQL内核:Apache Calcite数据管理框架

这里介绍一下这个SuperSQL的整体框架,在讲SuperSQL内核之前再提一下,Apache Calcite框架其实是工业级的SQL Parser和Validator,通过它做一系列核心计算变化,首先是把SQL变为关系代数,然后再将关系代数进行优化还有验证同时改写,最后再改写成为SQL,然后我们把这个SQL下推到我们对应的计算引擎,这就是总体的框架。SQL改写和优化的时候,其实是用到了比较熟悉的火山模型,通过火山模型去对计算成本进行总的控制,从中选出最优的一个计算框架;接下来会讲解为什么我们需要这种CBO和HBO,CBO和HBO在计算框架里起到决定性的作用。因为不同的计算框架出来的计算效果是天差地别,同时这个Calcite还是一个多类数据源的连接器,支持我们可以连接不同的数据源,像spark\\mangodb\\elasticsearch各种各样的引擎,只要能支持jdbc协议都可以把计算下推。同时这里强调一下Calcite是一个框架,并非是一个平台,所以需要给在这个框架里面提供实现,这个会对开发量上有一定的要求,所以它并不像一个成品,像直接拿hbase来,这个特别好用,上手拿过来改一改,然后就可以上线了。Calcite并不是这样,它就是一个框架,有一定的这么一个学习成本。
2. SuperSQL整体架构:漂移计算
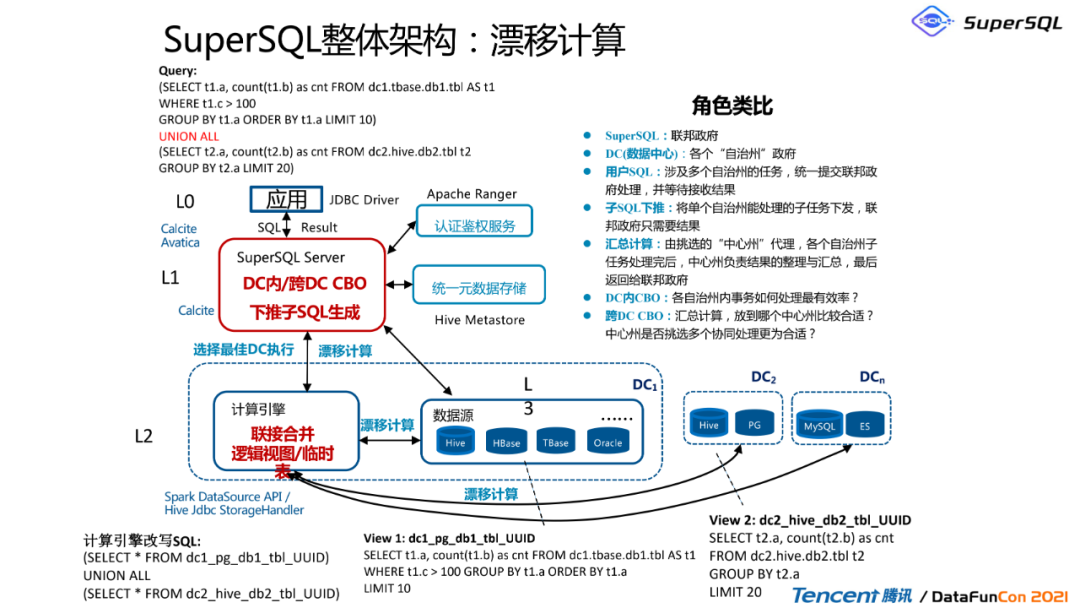
这里先从一个大图去介绍,SuperSQL整体框架涉及到漂移计算,打一个类比,SuperSQL计算引擎是一个核心,它的地位好比是一个联邦政府,当SuperSQL接收到了一个query的时候,他就会把这个用户的query下推到各个州政府,也就是我们的DC数据中心,也可以理解成为是不同的集群,这个集群可以是Spark的集群,也可以是Presto集群;可以是在北京的集群,也可以是在美国的集群,也可以是在深圳的集群;然后把这个计算SQL下推的时候,它其实是相当于是联邦政府把这个任务给下推到这个自治州,因为联邦政府其实只关心这个结果和这个任务怎么分配,它在怎么分配的时候,其实是通过了一系列鉴权和统一元数据计算引擎的优化。然后把任务下推到这个州政府的时候,也就是我们各个引擎的时候,由这个计算集群去负责决定怎么去计算。最后我们把这个结果由挑选的这些州政府处理完之后,再把这个数据合并回联邦政府这一边,所以它是这么一个下推模型。
这里可以看到第一层是L0,也就是应用把计算下推到L1,也就是我们的联邦政府,然后再通过联邦政府选择最优的DC去执行漂移计算,然后到我们的L2这边,L2也就是我们的各个州政府,然后L2有决定权去决定数据到底要从哪个DC集群里面获取,还是说用哪个计算引擎?所以我们是相当于把计算解耦。
这里举个非常简单的例子,假如有这么一个query,这个query是select表from DC1,在union all 一个select表from DC2,然后这时候我们就会产生两个view1和view2,分别把刚刚的两个查询下推下去,然后再去做一个合并,大概过程就是这样。
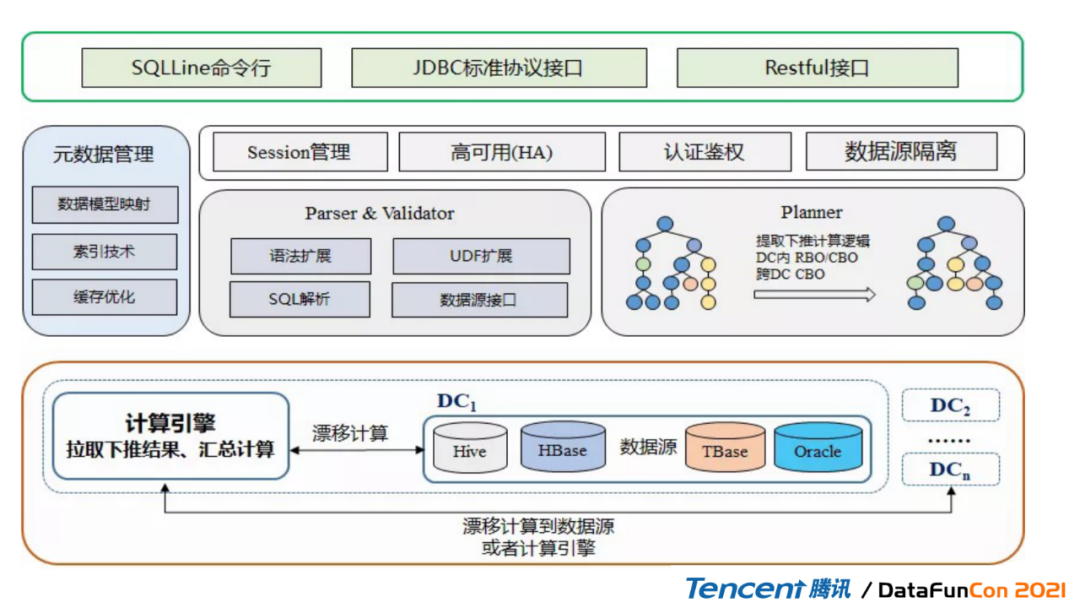
通过Calcite的Parser和Validator产生一个火山模型,火山模型会做一个CBO,然后把一个不平衡的树变成更加平衡。
04
元数据管理
1. 数据源元数据模型

讲一下SuperSQL的元数据管理,首先想强调一个元数据的设计模型是基于一个特殊的Trie格式,好比说上面这个图,最顶就是一个虚拟的节点,叶子就是具体的一个table,然后经过一系列定义,假如说是从dc1,然后到这个数据库,然后再到这个数据库的一个子数据库,然后再到一个叫test这么一个数据库,最后到一个某张表,就通过这种Trie的树状结构,我们可以无限的扩展,然后也可以精准定义我们的数据源,因为我们的数据源里面可能也有重复的表名,但是通过这种结构的话,我们把数据源、数据表的这些差别全部都考虑进来。
2. SuperSQL元数据管理I:层级数据源表征

这个数据库的这种元数据管理层有三个优势:通用性、灵活性、轻量级。
3. SuperSQL元数据管理II:CBO统计信息采集
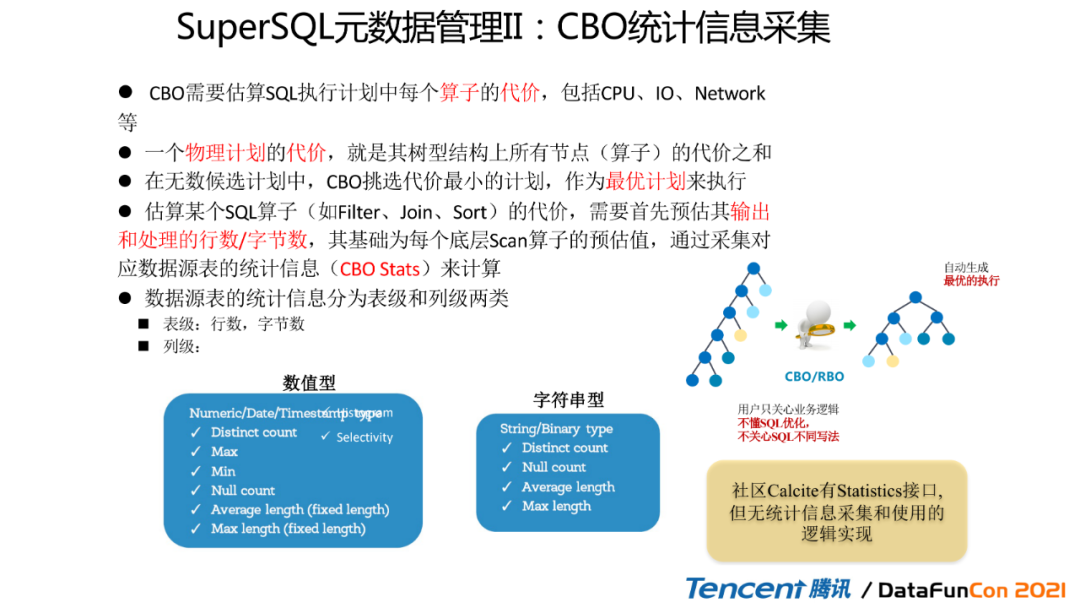
讲一下SuperSQL元数据管理的第二大特点:
我们是运用了CBO的一个统计信息采集,这CBO是什么呢?它是基于成本的这么一个优化模型,我们会把所有计算的代价,像CPU\\IO和Network都考虑进去,这个时候这些信息是子系统提供的。就说一个物理计划的一个代价,其实从图计算的一个角度来说,它其实就是这个树形结构上所有节点的一个代价算子的和。所以我们在做CBO的时候,其实SuperSQL的引擎端是对那个各个候选方案的所有计划成本来做一个统计,然后最后我们会选出一个最优计划,也就是代价最小的计划来做选择。所以在估算某个算子的时候,要假如说filter\\join\\sort来讲,我们首先是需要获取这个输出与处理行数的这么一个字节数作为一个预估值。那这个预估值是怎么来的?它其实是我们需要对下面的数据源,它在注册这个数据源的说,我们会采集它下面的一个信息,在我们这里也就是简称那个CBO那这个信息它是来自于哪里呢?它是来自于这个表的这个字段的类型。目前来说像我们这边的话有数值型、日期型,它包括那个Max value,Min value,Null count,还有平均长度,还有最大长度;字符串的话就要考虑distinct count,然后还有那个平均长度跟Max长度。所以其实从用户的角度来说,用户其实他并不关心底下的这个引擎是怎么执行,也不关心你这个SQL能改写成为什么样的一个代价,他希望把这个工作交给我们这个数据引擎,让这个数据引擎来决定。这个SQL到底怎么执行,怎么改写最优?所以是相当于SuperSQL把这个责任给接过来了,由SuperSQL来做SQL优化这个操作。
4. 统计信息使用样例:Filter输出估算
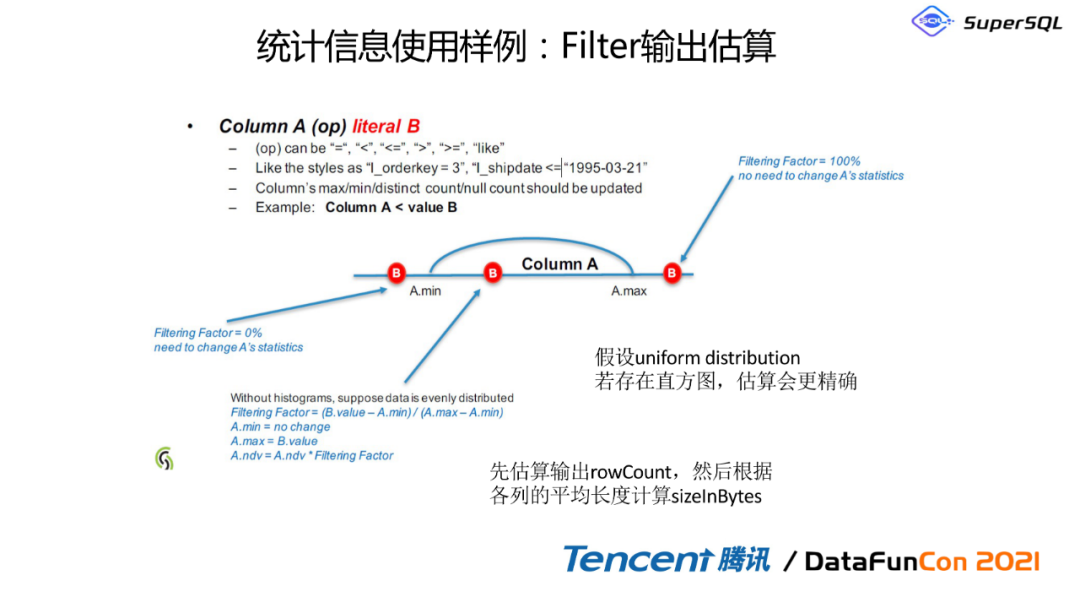
这里有一个例子,我们可以非常简单的看一下,如果是像这种一个B经过三次改写,有了不同的数据以后,我们会能改写到更优,假如它存在一个直方图,那我这个估算能够更加准确。
5. 统计信息持久化:Hive MetaStore

这里再讲一下元数据存储:
我们用hive metastore去存储元数据,假如你每注册一个数据源到这个下面的时候,它就会有一个新的datasource,也就是对应数据库中的一个虚拟表,然后我们在这个虚拟表上可以插入不同的hive metstore的属性;所以我们就是通过这种格式,superSQL.cbo.table.sourcetable.segment.数据库这么一个维度去定义它的一个参数。
6. 统计信息采集:Analyze 命令

具体我们再往下挖一下,我们怎么去挖这个数据呢?其实我们用到了一个命令叫Analyze命令,每当我们注册一个数据表的时候,我们通过这个命令把这个查询,把这个分析命令下推到数据源,然后让数据源返回这些表级别和列级别的统计信息。当然我们还有一些别的参数,像指定你这个sample size,同一个表的模式同时多次执行的话是怎么样?这些都是一些比较细节的配置模式,我们就不过多重复了。
7. 列统计信息采样与合并逻辑

最后我们可以看一下这个列统计信息的采样和合并逻辑:
假如我们经过多次的采集信息,它是怎么合并?举个例子说叫max,我们对这一列进行一个取max的时候,假如它是数值型,那么这个max假如是100,然后下次我再采样,两次采样的话,我们会取两次最大的值。所以这个是我们的一个逻辑,包括直方图、还有平均长度,我们会通过这种方式去不停地更新我们的元数据
05
跨源SQL算子下推
1. SuperSQL:一站式高性能大数据SQL中间件

这边讲一下SuperSQL的一个核心是跨源SQL算子下推,它本质定义是一站式的高性能大数据SQL中间件。能支持的数据源非常多,那个像 Hive / SparkSQL / PG / TBase / MySQL / Oracle 等,包括计算引擎也是能支持非常多的分布式计算引擎,例如说 Hive / Flink / Spark / Presto 这些现在都已经能够支持,能满足不同的计算时效的需求。同时还支持跨数据中心和集群的SQL优化和执行,主要是通过CBO/RBO这方面体现出来。所以从SuperSQL视角的话是可以解决内外部需求,假如产品化的需求,像历史包袱,包括现网业务的支持,还有融合其他开源的数据工厂,可以实现开源协同的功能。
2. 计算下推:支持常用复杂SQL算子
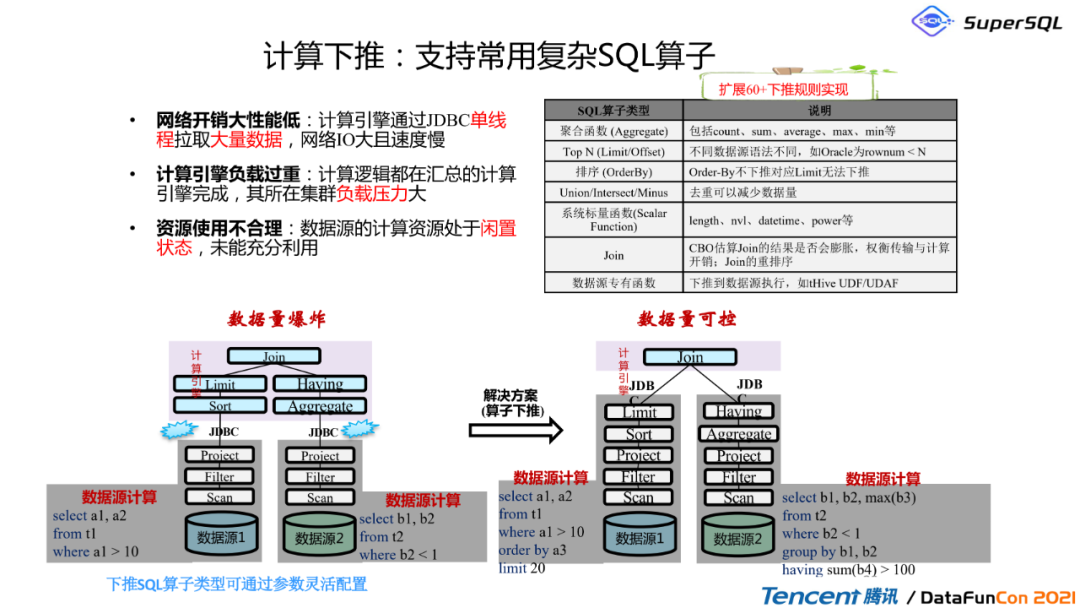
这里具体可以看一下我们为什么要把计算下推?计算下推其实有三大好处:
第一个是能大大减少网络开销,因为我们知道如果我们把所有计算都拉到联邦计算引擎来做的话,那么这个网络IO开销是非常大的。而我们都知道,其实在计算机里边计算传输是比计算本身的代价要大得多的。所以我们是希望把计算放到离存储最近的地方。
第二个是计算引擎负载过重,因为所有汇总计算都在单一联邦计算引擎中完成,计算复杂会压力非常大。同时我们考虑到计算资源的使用合理性,如果联邦计算集群做了所有工作,那么其他集群的计算资源就会处于闲置状态,并没有把削峰填谷和资源利用率考虑进去。
第三个是目前能够针对60多个下推规则,这么多比较核心的算子可以实现下推,像 average \\ max \\ min \\ 排序 \\ union all \\ join 这些都是把这些计算式给下推。这里我们可以看到普通的例子,就是刚刚讲的把所有计算都放到联邦引擎这边去处理,跟我们把算子下推的对比;前者的话,像很多计算,我们把这个 sort \\ limit 这些都得放在联邦计算引擎上去计算。那如果能把这个计算下推的话,我们其实是可以通过对SQL改写,加上limit,同时也加上order by,把计算下推到两个数据源,然后在核心的联邦引擎中只做join操作就可以。
3. Join下推示例
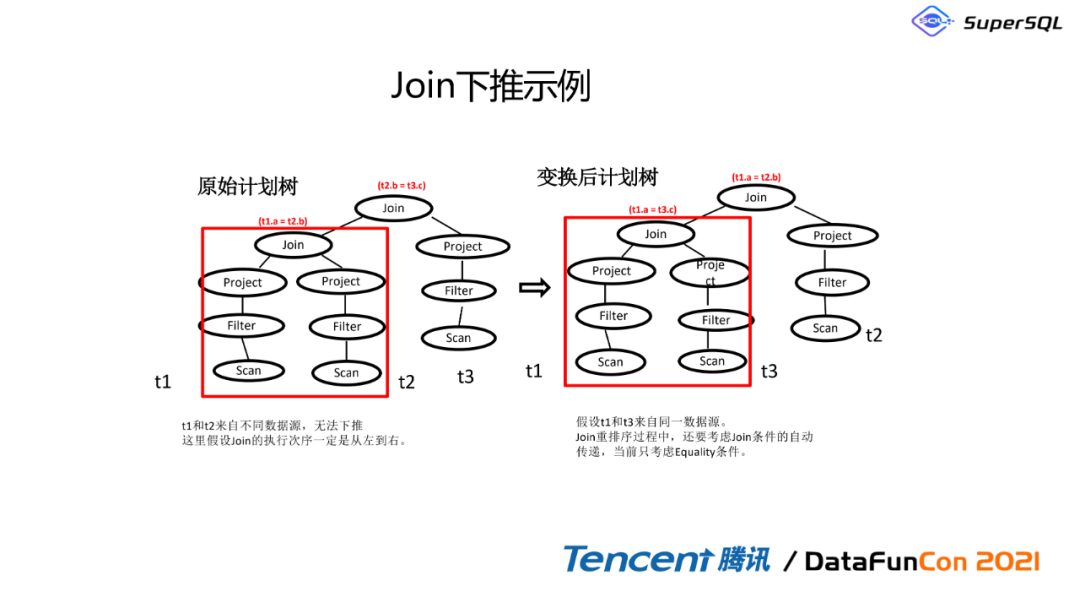
这有个非常典型的执行计划优化变化。我们看原始计划树,其实它是需要做非常多的操作,假如说我们Trie这里是来自于两个不同的数据源,是没有办法下推的,这里的join操作是从左到右的;但是如果我们能把它进行改写,其实这里也有个假设, t3也是来自于同一个数据源,那我们就把对同一个数据源的操作先合并到一个query里面,然后进行下推。相当于说把这个耗时的操作,先让这两个操作先合并在一起,然后再对接另外一个数据源。那这样我们就可以把这个操作给平均一下,让它能达到更加节省时间的操作。不然的话这里它得做两次Join,首先t1.d Join t2,然后这个结果再Join t3,然后这边的话其实只有一个操作,因为这里的操作t1跟t3是在同一个数据源,所以的话它是当前一个操作,我们把三次的计算变成了两次的计算。
4. Aggregate下推Union All(1/2)

第二个就是Aggregate下推计算,我们可以考虑到把这两种union all的操作变成两个不同的下推操作,好处就是能最大量的减少数据传输,这也回到我们刚刚的第一个目标,减少网络io。
5. 下推SQL优化:并发子查询切分
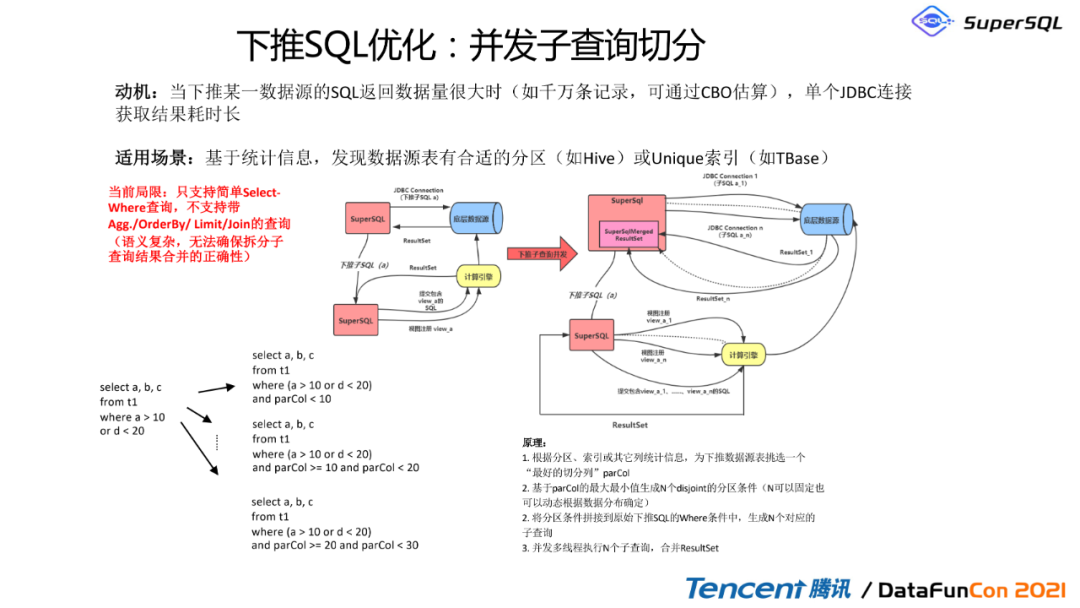
这里还有另外一个模式,不仅仅是可以把计算算子给下推,同时我们可以把并发子查询切割。我们发现在对某一数据源这个SQL的返回量非常大的时候,假如有千万条记录,上亿条;可以通过CBO用户上单个CBO去连接的时候自动获取,这个时间非常长。举个例子来说,基于CBO,我们发现数据源表有不同的分区,假如是那个2020年12月1号,2020年12月2号,这两个分区的数据非常大。那这个时候我们其实也可以通过SuperSQL按照规则,碰到跨时间的分区,就把它给切割。这里就有一个例子,像我们把这个查询从一个查询从a大于十和d小于20,把它切分成为a大于十,d小于十,同时这个parCol小于十,然后parCol大于十跟小于20,还有parCol大于20和小于30,我们就相当于把这个东西给切片了。这个其实也是分治法,就是divide&conquer\\分而治之。通过这种并发子查询的下推,然后我们实现查询的并发跟平行。
06
分布式计算引擎
1. SuperSQL分布式计算引擎需求

接下来我们再讲一下分布式计算引擎核心模块,这里其实考虑到现在很多的互联网公司并不希望重复造轮子,希望尽量用Spark、Flink、Presto等。通过这种分布式的中间件,我们可以把这个计算不依赖于某个特定框架,基本上不用做任何侵入性的修改,或者做一些非常少的分布式修改,就能把多套大数据计算引擎给联合起来,然后同时SuperSQL可以根据SQL的特征,智能地挑选主流的计算引擎。所以我们这个设计就是解耦方能专注,解耦就体现在这一方面。
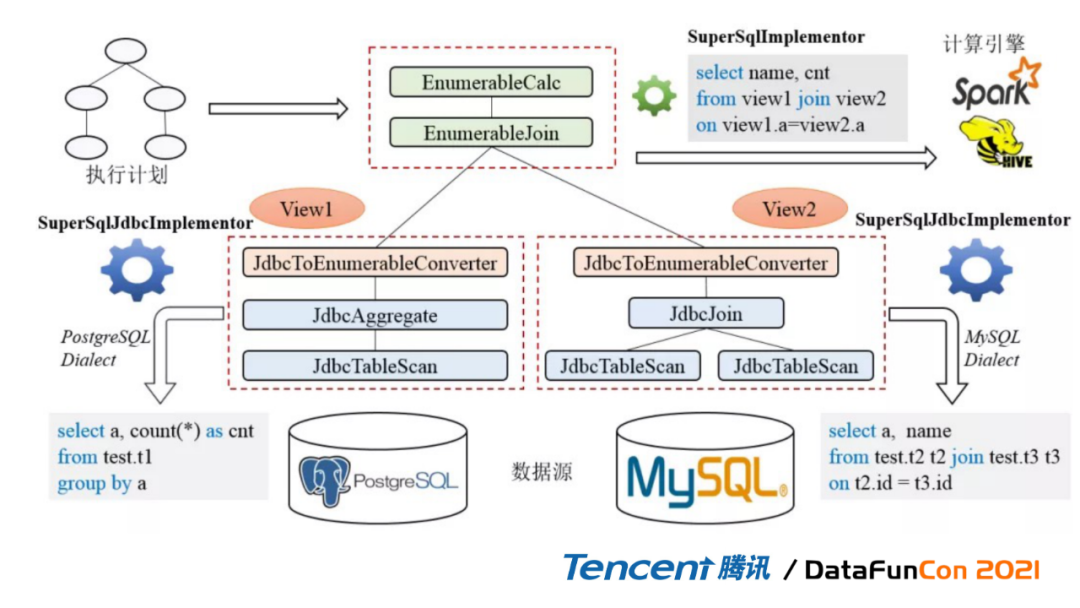
2. 计算引擎处理流程:数据源下推子计划 ->临时表映射
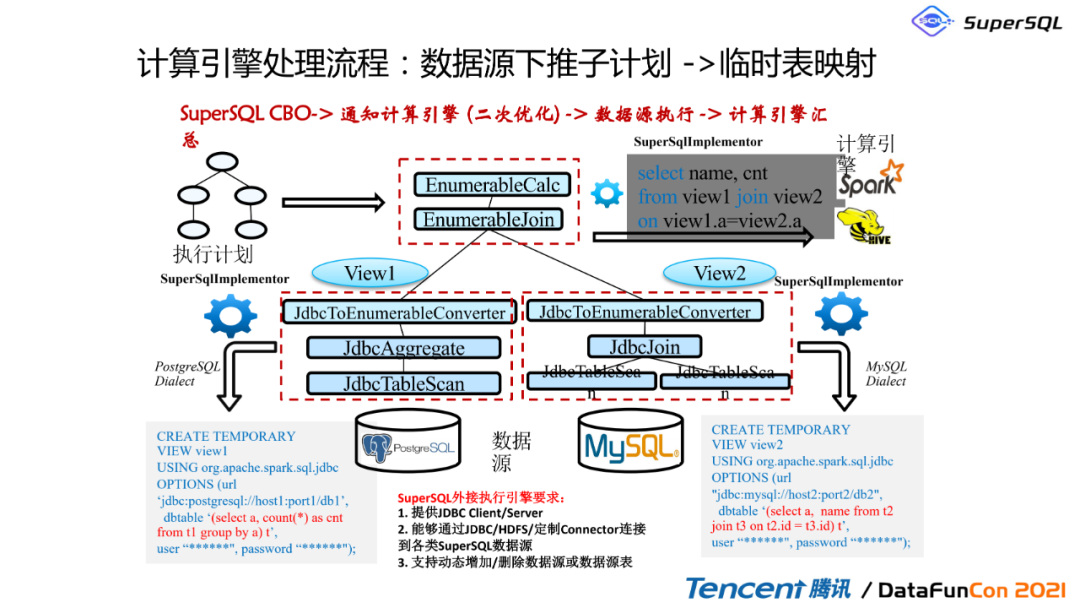
这里可以看一下,它是我们整个执行计划的变换图,总体来说,假如说以Spark为例,SuperSQL接Spark引擎来查询的整体流程是一方面先将数据源下推的SQL映射为视图,另一方面是执行合并的SQL返回结果。以这个图为例,这个SQL经过优化之后,它有对应的执行计划,首先对Postgre数据源的数据表进行聚合操作,也就是我们左边这一块;然后对Mysql的数据源,也进行相同的操作,最后进行join操作,我们对join操作进行一个汇总。这个时候SuperSQL会将整个执行计划转化成为三部分,三条SQL,其中View One对应的是下推给Postgre,View Two是对应下推给Mysql执行,然后在spark执行引擎中,我们做这个合并操作的时候用的是spark,它会注册这两个视图,然后再将两个视图汇总,所以它整体的算法逻辑实现采用的是visitor设计模式,它最核心的现在是这个SuperSQL Implementor和JDBC Implementor,这两个是我们的核心连接模块。所以我们通过这种下推模式就可以把计算汇总到最后的Spark引擎中。
07
跨DC查询优化
1. SuperSQL CBO概览
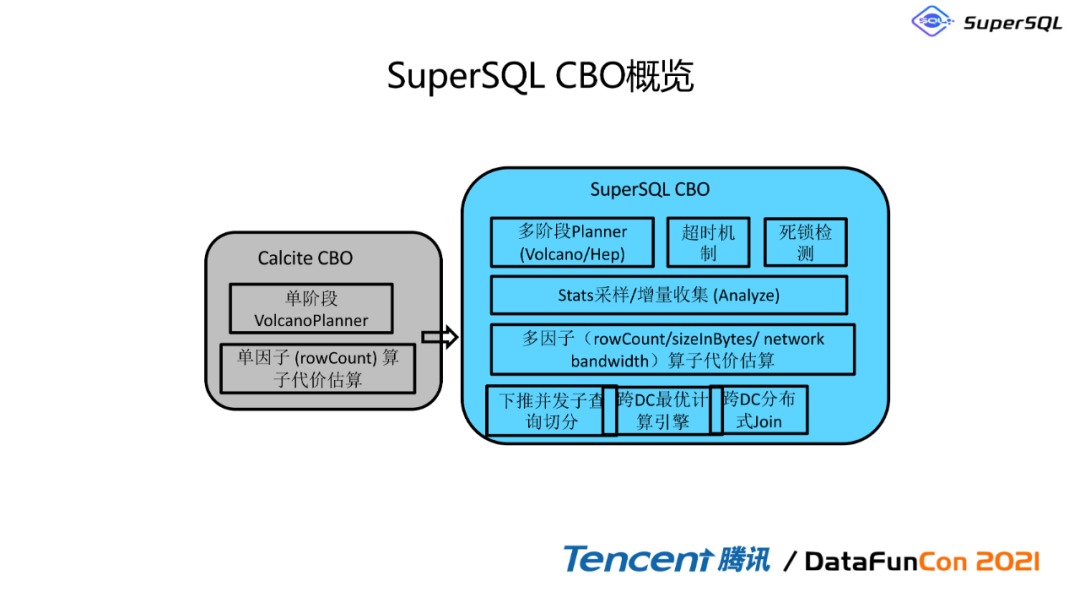
这里讲一下这个跨dc查询优化,跨计算引擎的一个优化,其实这块我们是做了比较多的文章,这里要涉及到单阶段Volcano Planner和多阶段Volcano Planner的说法,单阶段Volcano Planner相当于是只有一个阶段的火山模型优化,而SuperSQL是基于多阶段的火山模型的优化,这里包括了非常多额外的检测,例如说我把这个计算下推到下面的引擎的时候,有超时检测,死锁检测还有各种各样多因子的检测,比如说计算中心的那个地理位置特别远。举个例子,假如说他是在非洲,网络带宽也非常小, SuperSQL在做CBO的时候,就会把这些因素给考虑进去,然后把总的计算成本给计算出来。
2. DC内CBO:多阶段Planner
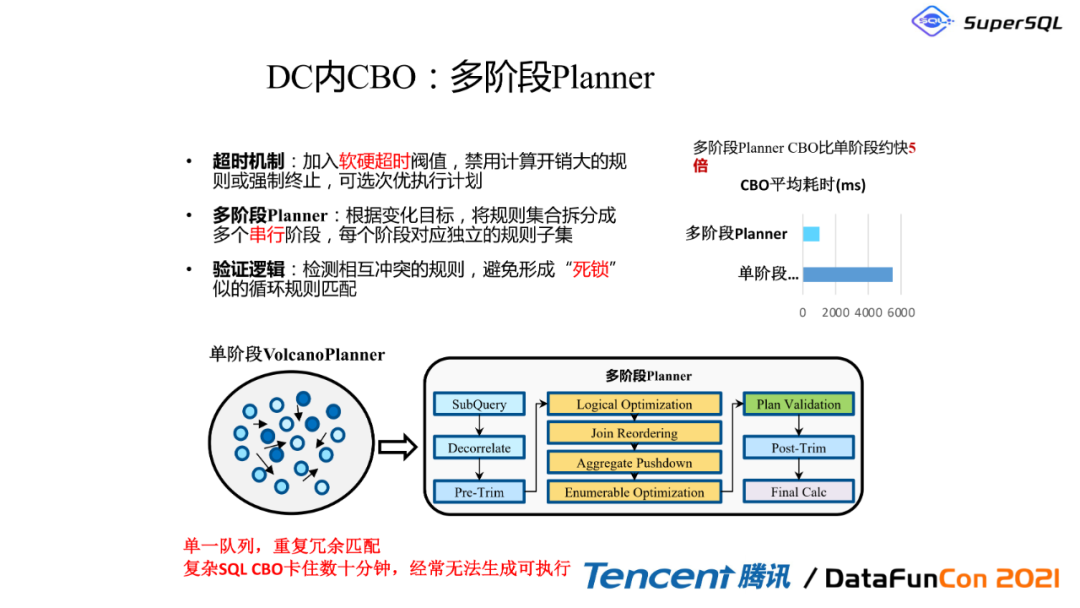
先讲一下多阶段的planner,第一个是超时机制,加入超时阈值,禁用那些计算开销特别大的查询,而我们选择比较次优的执行计划。我们这边有一个统计,就说CBO平均耗时,如果只用单阶段的火山模型,假如我只计算这些每个表的统计信息,而不考虑哪个dc、每个地域具体这些集群信息的话,他的那个耗时是非常长的,可能多阶段能够优化80%左右的性能,这个是秒的单位。所以如果是单一的,我们在内部也已经实践过,性能可以有很大的提升空间。
3. 跨DC CBO:数据源间网络带宽
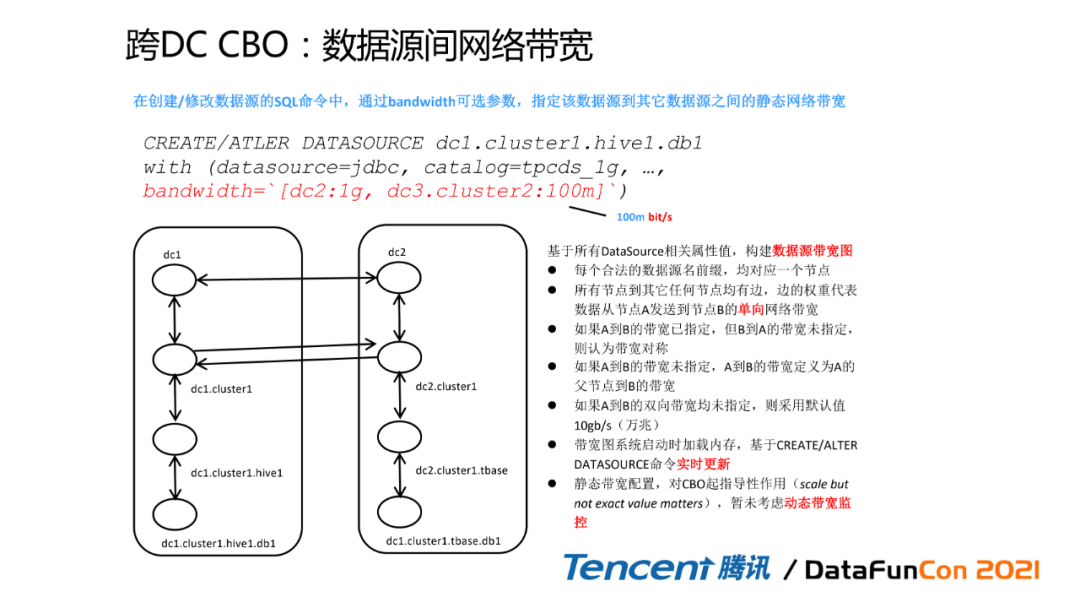
这里有一个具体的例子,在跨dc执行CBO的时候,其实是考虑到了网络带宽的差异。所以我们在对下推计算的时候,会自动的把这个query添加一个参数叫bandwidth,然后这里会把我们的带宽引擎给写上去,像dc2是一个非常闲的,而且带宽非常宽的计算资源,但是dc3只有100M bit每秒的带宽;一对比,我们就知道dc3的计算带宽是非常小的,所以很多时候哪怕这些数据在dc3上,可能是它的执行计划会更优,如果不考虑这么带宽的话;综合考虑之后,我们会发现其实全局最优的计划是从dc2这边去获取一些数据,所以我们也会把这个数据把这个query打到dc2下面去,然后同时这些带宽信息也会实时更新,包括假如说每五秒每十秒,我们能做到一个动态的带宽监控。
4. 跨DC CBO:计算引擎到数据源的网络带宽

这里也是讲怎么去把这个带宽纳入到对多计算引擎的考虑。
5. 跨DC CBO:最优引擎挑选

这里有一个特别典型的跨dc的最优引擎选择:
如果我们只是普通的用这个SQL这个去做单引擎优化的话,那我们其实只能按部就班从dc3下推到dc2,dc2然后下推到两个引擎,假如是hive引擎,他的统计信息仅仅是基于这个输出行数和字节数,如果我们并没有对它的下推query的网络带宽进行统计,最终的性能其实是并不完善。而如果我们这个是对子查询进行切分,然后多引擎协同的话,我们会考虑更多的元数据,就包括它的那个,像数据量,用户响应时间,还有稳定性,它的火山模型会变成这样子的。这里的计算引擎大家可以想象成代表着不同的这些计算框架,像Presto\\Spark等。
08
性能评测
1. 测试环境

最后讲一下性能测评,评估我们做了这么多工作到底有没有用啊?可以看到这里,我们做的测试是基于六台服务器,128g内存,48核,然后我们有好几个计算引擎,像 Spark / Hive / Postgre / Hadoop;我们的对比基线是SparkSQL JDBC的。
2. TPC-DS性能测试结果
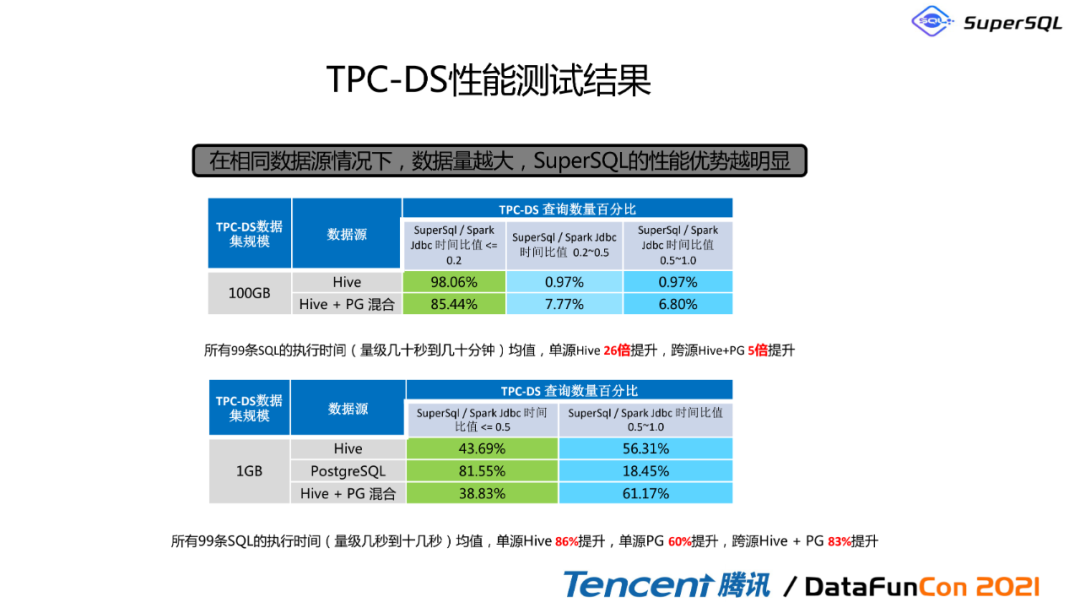
可以看到在数据量越大的时候,SuperSQL的性能优势是非常明显的。我们可以看到如果只是通过hive,SuperSQL占spark这个时间比大概是98%,但如果是联合查询的时候,我们就只占他的那个85%的时间; 然后还有SuperSQL占Spark Jdbc这个时间比甚至达到了低于1%。我们都可以看到, 对单源性能的话,有26倍的提升,对跨源的话大概有五倍的性能提升。同时我们对99条SQL的执行时间进行比对,我们发现单源还有86%的提升,对单源pg有60%的提升,对跨源有83%的提升。
3. 并发子查询性能测试结果
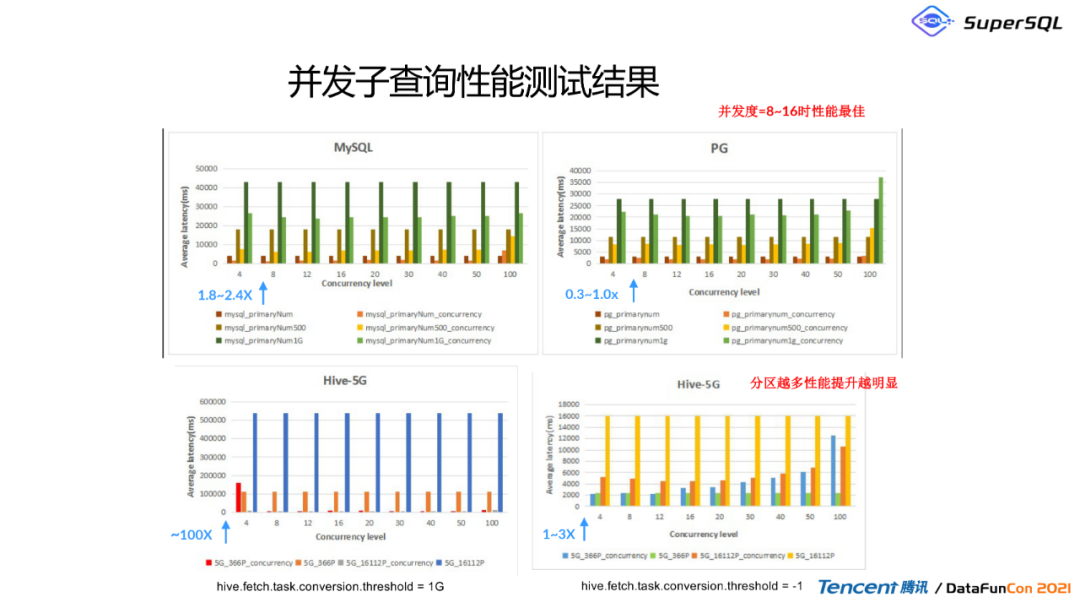
从图中可以看到通过Mysql\\PG\\Hive耗时最短的都是SuperSQL。
09
SuperSQL未来规划

最后讲一下SuperSQL的未来规划:
其实我们在最近大半年,我们是做了深度的升级,首先是包括HBO,其实它也是属于元数据升级的一个新领域,我们可以根据历史执行的SQL,假如说这个SQL它在某个引擎上,它执行了多少时间,或者说它抛出有什么问题,抛出了什么异常,把这些数据都收集起来,然后放到一个元数据的训练库里。下次遇到这种类似SQL的时候,这里运用了一个叫SQL指纹的概念。SQL指纹是我们通过对SQL进行识别,然后用模式识别的算法把它提取出来某些特定的特征,然后去匹配我们已有的这个HBO的历史库,通过历史库里面的这些query发现原来他用过Spark,用过Presto,用过Flink;假如说我们发现用Presto的性能最好,同时在这个dc1里面,查询时间是最短的,那么之后我们就会利用HBO的指导去从dc1用Presto去做查询,同时把它本身也当成是一个记录再重新去hbo,然后不断地迭代hbo的效果,我们目前发现能在现在的基础上又提升百分之三四十的效果。
第二个是元数据存储重构与迁移。我们是相当于把元数据服务重构给独立出来。因为未来我们希望把CBO\\RBO\\HBO还有机器学习算法都运用到执行计划的优化算法之中。
第三个方面是我们基于多代价因子的优化,其实就考虑到像这个执行计划的优化,它其实还有很多方面需要考虑,不仅仅是基于它本身表的执行计划,其实可能还有一些很多业务上的考虑,假如说这个集群的计算资源特别昂贵,这些我们都要考虑进去。
最后,我们现在也已经开始对接OLAP引擎,之前的话,SuperSQL更多的是针对离线和实时的计算,现在我们更多是把这个当成是一站式的智能大数据平台,我们可以通过离线执行完结果以后,然后把这个数据导入到我们的Olap引擎,比如说Elasticsearch,或者ck,通过这种构建的话,SuperSQL就能形成一站式服务,用户不需要再把这个数据倒腾来倒腾去,把这些数据通过etl的变换,不仅浪费资源,需要落盘,而且还耗时,这个也是我们最后讲到的智能选择框架。
今天的分享就到这里,谢谢大家。
分享嘉宾:

声明:本文来自DataFunTalk,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
