原文标题:The Many-faced God: Attacking Face Verification System with Embedding and Image Recovery
原文作者:Mingtian Tan, Zhe Zhou, Zhou Li原文链接:https://dl.acm.org/doi/10.1145/3485832.3485840原文来源:ACSAC 2021笔记作者:HowieHwong文章小编:ourren@SecQuan
Overview
人脸验证系统(FVS)可以核验一个人的身份,已经广泛应用于现实生活中。其使用了人脸嵌入技术,这种技术可以通过深度神经网络检测出同一个人的相似照片。
项目团队发现,与核验结果一起显示的分数可以被攻击者用来“伪造”目标人脸从而通过核验。即攻击者可以通过反向嵌入的方式来获取较高的核验分数。项目团队发明了一种新的机器学习技术,这项技术用于进一步学习核验目标人脸的外观特征,称之为反向嵌入式GAN。
结果显示,当攻击者对FVS进行2次查询,对手可以以40%的成功率通过人脸核验。当查询数增加到20时,几乎每次都可以通过核验。除此之外,用该技术复原的图像也和目标对象的人脸相似。
Main ideas
项目团队研究的攻击背景是基于三种关于FVS和人脸嵌入的见解:
FVS信息泄露
对于某些FVS,每次验证结果(“成功”或“失败”)显示给被验证者时,分数也会显示出来,该分数反映此人的图像与被验证者的图像有多接近/多远。该得分与嵌入空间的距离有直接关系,而系统就会通过该分数泄露一小部分用户的面部信息。一旦收集到足够的信息,这种相似性可以帮助攻击者复原人脸图像。
从泄漏中嵌入回收。
攻击者探测不同图像的FVS的过程可以积累大量信息。团队发现,当查询图像的数量与嵌入模型的维数相等时,目标对象的嵌入可以无错误地恢复。这主要是因为嵌入是一个高维向量,仍然服从代数几何定理,通过在欧几里德空间上用方程表示嵌入距离,可以求得方程的根。此外,团队发现通过基于PCA(主成分分析)的降维方法,攻击者可以大幅度减少查询的次数。
基于嵌入的图像恢复。
通过嵌入,攻击者可以重建目标对象的人脸。然而,人脸嵌入是一种复杂的、非线性的、有损的映射。反转这样的映射是相当具有挑战性的。为此,团队提出了一种基于生成式对抗网络(GAN)的方法。经典的GAN模型基于噪声输入或预定义的标签重建图像,但没有一种模型可以处理不可见的输入。因此,团队设计了一种新的反向嵌入GAN (erGAN),其发生器和损耗函数专门用于嵌入输入。
Contributions
团队的贡献如下:
团队发现,当攻击者用不同的图像探测FVS的结果时,FVS的安全性受到威胁。
团队提出了一种新的攻击人脸嵌入的方法。该攻击能够仅进行少量的FVS结果试探来复原目标人脸。
团队发明了一种新的基于GAN的DNN模型,它能够从恢复的嵌入中重建一个接近受害者的图像。
团队使用最先进的嵌入模型和真实世界的人脸数据集来评估我们的攻击。
团队的进攻包括五个步骤:
假定受害人的身份已被获取,例如通过搜索公共身份数据库。对攻击者来到FVS,输入目标受害者的ID,并启动人脸验证过程。
显示验证结果(应为“失败”)和评分,从而泄露受害者信息。为了获得更多的信息,通过不同的尝试收集多个分数,这可以通过展示不同的人脸图像来完成。
攻击者用测试人脸及其分数重建受害者的嵌入。
通过模型复原受害者面部图像。
攻击者打印出生成的人脸图像(例如,作为一个面具)并佩戴它以绕过FVS。
Embedding Recovery
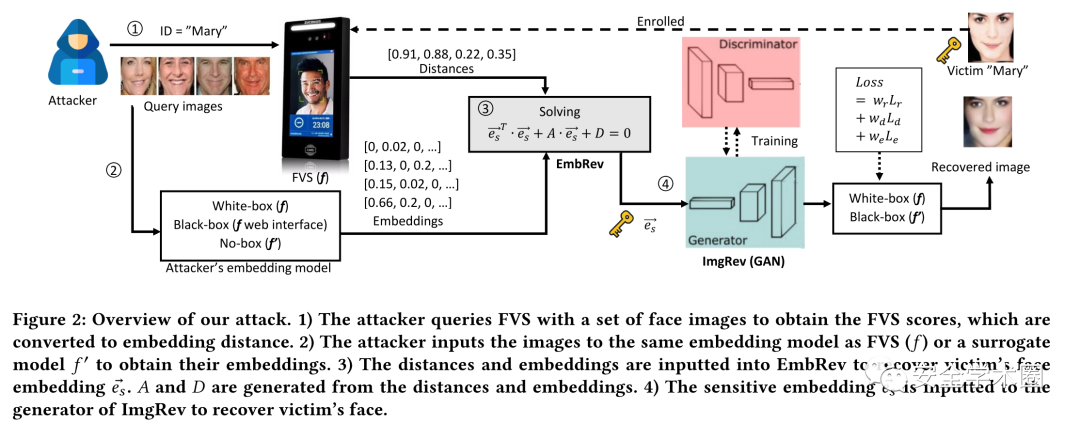
尽管EmbRev很有效,但是运行EmbRev的代价很高,因为需要进行多次尝试查询。在某些场景下,比如边境的自助FVS,攻击者可能不可能获得数百个距离。
为了避免过度拟合,开发人员在训练迭代期间有意关闭一些神经元,这将推动不同的神经元生成类似的输出,并向层的输出引入高信息冗余。进一步了解信息存储在嵌入,团队利用奇异值分解(SVD)提取每个嵌入的关键成分。发现当rank达到33位及以上时,平均距离将低于0.1。距离0.1表示两张脸非常相似,换句话说,可以使用33维的嵌入来近似128维的嵌入。
EmbRev under No-box Setting
在这种情况下,对手不能了解FVS的内部模型 。但是这种限制可以通过攻击另一个嵌入模型 来解决。假设 , ,是嵌入模型的函数空间, 和 的精度相似。当攻击现实世界的FVS时,对手可以通过显示的相似分数来调整 。
Image Recovery
ImgRev主要由一个新型的嵌入图像发生器、一个鉴别器和损耗函数组成。与现存的GAN相比,ImgRev有一个不同之处,即团队使用的是嵌入的方法,而不是随机产生的噪声作为发生器的输入,这种方法被称为嵌入-反向GAN(或erGAN)。在训练之前,需要收集一组真实的人脸图像来生成erGAN的嵌入。
Generator
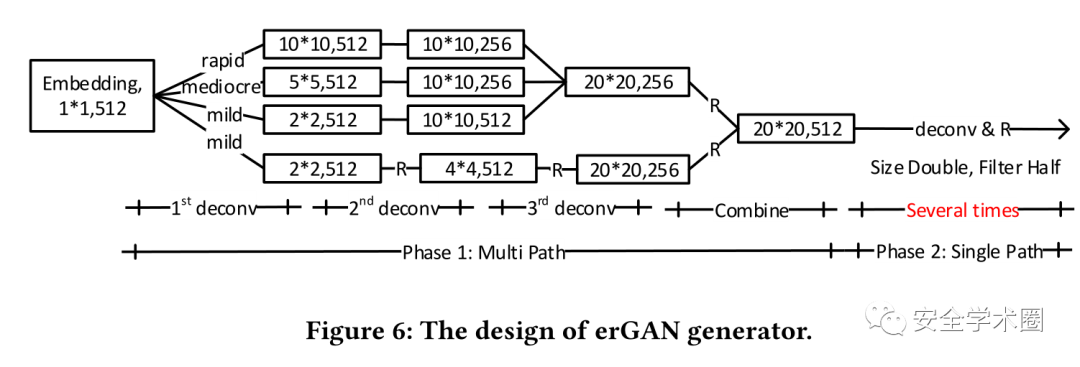
普通GAN在噪声场上具有泛化能力。它可以生成逼真的图像,但它不能控制图像属性。项目团队需要将生成的图像与它们的输入嵌入绑定在一起。条件GAN (cGAN)在标签约束下对噪声场具有泛化能力。如果把embeddings看作标签,那么cGAN确实可以使输出图像对应于embeddings。但是,cGAN在标签上没有通用性,只能生成带有可见标签的图像,这并不满足相应的要求。与普通GAN和cGAN相比,erGAN具有泛化能力,即使是对未知的嵌入,即EmbRev恢复的嵌入也具有泛化能力。
Discriminator
鉴别器试图将生成的图像与真实的人脸图像区分开来,以帮助生成器提高图像质量。鉴别器遵循了WGAN-GP的设计,解决了GAN在生成高质量图像时训练不稳定的问题。鉴别器去掉了所有的批处理归一化层(BN),并且在每次卷积操作后,添加一个小的残差块,以避免生成器主导整个过程。最后,鉴别器的输出将是一个标量值,该值是鉴别器认为 在 范围内的置信级别。
Evaluation
团队的测试结果如下:
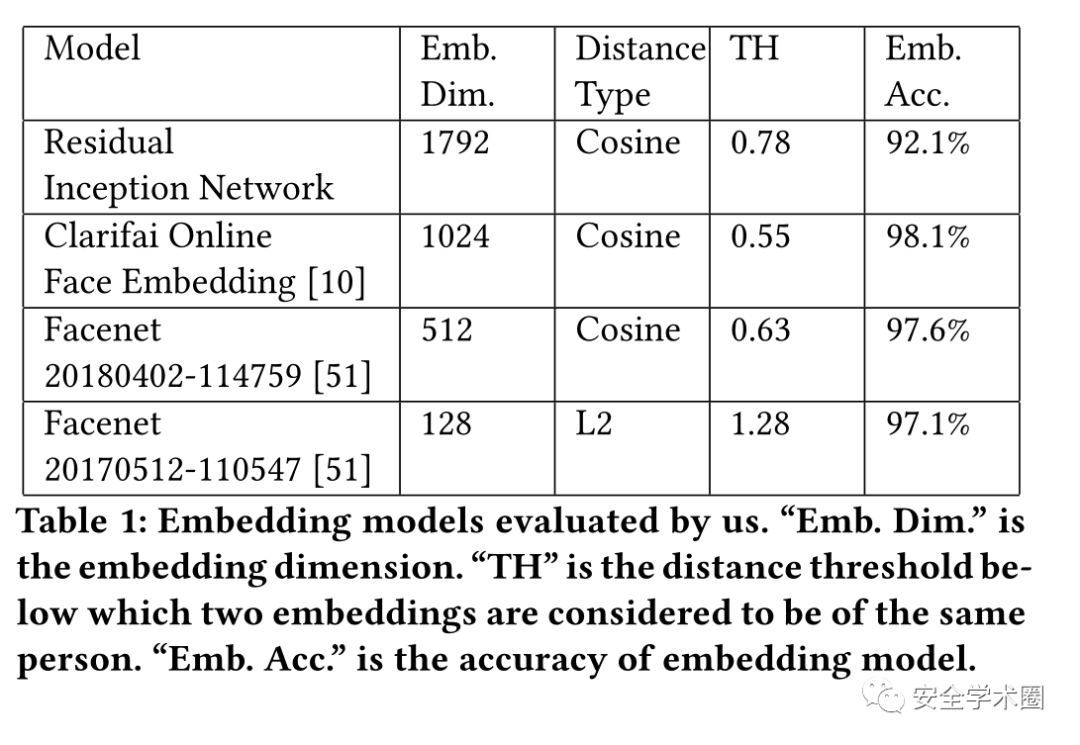
可以发现该攻击方法对于现有的流行FVS效果良好。
Liminations
(1)在未知模型的条件下,EmbRev的噪声较大。虽然从嵌入中恢复的图像仍然能够绕过FVS,但是可以发现图像与受害者的照片存在明显差异。
(2)可以进一步改善ImgRev生成的图像的纹理。从实验结果可以看出,虽然该模型可以很好地恢复粗糙获得的受害者面部特征,如轮廓、眼睛和鼻子的位置等,但像皮肤纹理这样粒度较细的特征并没有被很好地描述出来,这主要是因为这些信息没有存储在嵌入中。
(3)出于道德等现实因素的考虑,团队没有在真实世界的FVS上测试该方法。
(4)团队使用的数据集较小。当数据集较大时(例如,包含数亿幅图像),结果可能会有所不同。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
