端到端的通讯加密技术(End-to-End Encrypted)已经成为大势所趋,如国外流行的 WhatsApp, Telegram 等即时通讯APP都已经采用了E2EE技术,显然,正确的使用 E2EE 技术能够更好的保护用户的隐私安全和数据安全。这主要是因为,在E2EE 技术之前, 很多提供即时通讯服务的厂商所推出的应用中,用户所发送的消息对中心服务器而言都是透明的。这在一定程度上来说,与这几年提出的个人隐私安全保护是背道而驰的。然而如果采用 E2EE 技术,那又将会给内容审核造成阻碍。如何在端到端加密通信的环境下做好内容审核成为了各个大公司的挑战。本文首先介绍端到端加密技术,再总结 E2EE 环境下的内容审核技术进展。
一、什么是E2EE
最基本的 E2EE 模型如图1所示,假设 Alice 与 Bob 正在通过第三方平台(如:Facebook, WhatsApp)进行端到端的通信,Alice 和 Bob 事先已经通过密钥协商建立了共享密钥。Alice 发送消息 "Hello" 至 Bob, 该消息首先会在 Alice 的客户端上进行加密再经过第三方平台转发至 Bob,Bob 接收到加密消息后,通过客户端解密,最终呈现消息 “Hello”。从E2EE模型可以看出,E2EE 保证了消息的保密性和完整性,只有拥有对称密钥的双方能够解密消息,即使是第三方平台也无法得知消息的具体内容。
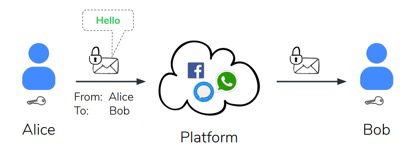
图1,E2EE 模型
当然,上述的E2EE模型为最基本的模型,部分厂商(如:Signal)还提供了匿名发送功能来防止元数据分析,如图2所示。
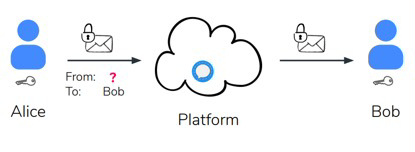
图2,E2EE 匿名发送模型
二、 E2EE环境下的内容审核技术
到目前为止,厂商采用的 E2EE 环境下的内容审核技术主要有:用户举报、可追踪技术、元数据分析、感知哈希算法、内容预测模型。
2.1 用户举报(User Reporting)
用户举报功能不仅仅在 E2EE 环境下会被厂商采用,实际上在各种传统的即时通讯和社交媒体网络中,用户举报功能都有很好的体现。用户举报功能一方面依赖于群体的力量,比如在一些社交媒体类的应用中(如:新浪微博)对于能够看到的内容,用户可以对一些违反社区规定的发文进行举报,提升用户的内容审核参与感;另一方面依赖于消息接收方的积极响应或维权(如:微信),在一些即时通讯的应用中,接收者对消息发起举报。平台接收到举报后,可以进一步的对消息进行处理。不过需要说明的是,在 E2EE 环境下,针对举报内容的审核并不是完全的明文审核,为了尽可能的保护发送者和接收者的隐私,内容审核遵循Message Franking模式,即对被举报内容进行元数据隐藏处理或仅现实部分内容。
2.2 可追踪技术(Traceability)
追踪技术的引入主要是为了满足违规消息的溯源需求,为了能够打击违法犯罪分子或惩戒发布违规内容的用户,需要能够追踪到消息的源头发送者。然而在 E2EE 环境下消息或许是匿名发送,则不能直接追踪到源发送者。目前存在两个方案可供选择:A) 在每一个消息的元数据方面增加源发送者的加密后的身份标识信息,如图3-A 所示。B)厂商维护一个消息摘要数据库。一旦违规消息的摘要确定,那么通过消息摘要数据库则可以找到消息的源发送者,如图3-B 所示。
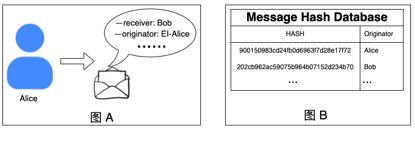
图3,内容追踪技术
2.3 元数据分析(Metadata Analysis)
在内容审核范围内的元数据分析一般是指针对发送消息的元数据分析,主要包括对消息的发送时间、发送对象、发送者、发送频率等相关相关数据进行分析,分析过程中还会结合机器学习等人工智能模型。近几年,基于机器学习的元数据分析在内容审核方面大放异彩,在2021年,WhatsApp 厂商在其用户设备上的客户端内就集成了机器学习框架用于元数据分析,通过该方案,WhatsApp 声称封锁了约30万个涉嫌传播 CSAM(儿童性虐待内容)的账号。可以看出元数据分析一般都是在用户设备的客户端上进行的, 通常来说,**只要元数据分析是发生在用户设备上并且只要在分析过程中不存储、使用和发送未加密的消息,则认为是保证了用户的个人隐私的。
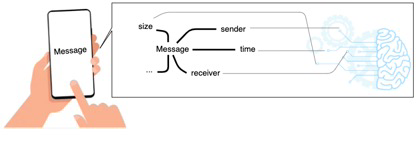
图3,元数据分析
2.4 感知哈希算法(Perceptual Hashing)
在内容审核和分析中,主要存在两种类别的机器学习,分别是匹配模型和预测模型。匹配模型旨在识别出相似或相近的媒体文件,使用的关键技术是感知哈希。感知哈希算法(Perceptual hash algorithm)是一种指纹算法,能够针对多媒体文件产生指纹。感知哈希是一种局部敏感哈希算法,即只要多媒体文件中的性状相似,则认为该媒体文件是相似的。感知哈希和密码学哈希需要区分开,密码学上的哈希算法具有“雪崩效应”,只要两个文件中存在极小的差异,而得到的密码学哈希也将完全不同。感知哈希则不同,只要两个文件越相似,则得到的指纹也越相近,反之则相差甚远。
感知哈希经常用在自动化的文本分析上,通过这种自动化的分析,可以鉴定用户所发送的内容是否为曾经被标识过的违规内容。在 E2EE 环境下,如果要对明文做感知哈希分析并且分析模型放置在服务器端则可能会违反用户的隐私保护政策。针对这种限制,有学者提出了在服务器端通过感知哈希算法来匹配加密文件与违规内容的相似度的方式来达到内容审核的目的,但是这种方案很容易出现误判,毕竟是对加密后的密文做分析。相反的,如果将匹配模型放置在用户客户端上,违规内容的指纹库存储在客户端中,并且指纹库匹配结果仅仅反馈给客户端本身则不会侵犯到用户的隐私。但如果将结果反馈给服务端则侵犯了用户的隐私,所以这也是在 E2EE 环境下,厂商需要考虑的实际问题。
感知哈希算法还存在一个现实问题,感知哈希匹配模型仅仅能匹配一些曾经出现过的类似的违规内容,对于未出现过的内容则无从下手。有研究显示,84%的 CSAM 内容仅仅上报过一次,也就是说这些内容在以前都从未出现过,那么感知哈希匹配模型则没有办法监测到这些违规内容。
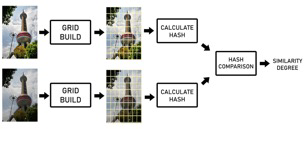
图4,感知哈希算法
2.5 内容预测模型 (Predictive Models)
内容预测模型和感知哈希匹配模型不同的是,感知哈希匹配模型通过对比待检测内容与以往违规内容的相似度来判定内容是否违规,而内容预测模型则基于机器学习的手段预测内容是否违规。内容预测模型不依赖于该内容是否曾经出现过或者有类似的内容存在,更多的是依赖大量的数据进行机器学习训练,最后得到预测模型,该预测模型可以对从未出现过的内容进行判定。
声明:本文来自山石网科安全技术研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
