原文标题:CoaCor: Code Annotation for Code Retrieval with Reinforcement Learning
原文作者:Ziyu Yao, Jayavardhan Reddy Peddamail, Huan Sun发表会议:The World Wide Web Conference原文链接:https://dl.acm.org/doi/abs/10.1145/3308558.3313632笔记作者:zhanS@SecQuan文章小编:cherry@SecQuan
代码检索的目的是从代码库中检索与给定的自然语言查询相关的代码片段。代码注释的目的是为代码生成自然语言注释。这两项任务是分开实现的。在这篇文章中,作者将这两项任务相结合,代码注释模型用来生成代码对应的自然语言注释,表示目标代码的语义,进而被检索模型查找。这样一来,生成的代码注释可以认为是代码的语义表示。文章所提系统框架如图1所示。在模型训练阶段,首先训练一个基于QC对(<自然语言查询,代码片段>对)的代码检索模型;接着,给定一个代码片段,使用代码注释模型生成一系列自然语言token作为注释,并从代码检索模型中接收奖励,注释模型评估如何生成注释以有效地将目标代码片段和其他代码片段区分开。代码注释模型训练好后,对于每一个QC对,能够为其生成对应的QN对(<自然语言查询,自然语言注释>对)。利用生成的注释作为代码的语义表示来匹配自然语言查询,基于导出的QN对训练另一个代码检索模型,称为:基于QN的代码检索模型。在测试阶段,给定一个自然语言查询,通过结合基于QC的代码检索模型和基于QN的代码检索模型的得分对代码片段进行排序。
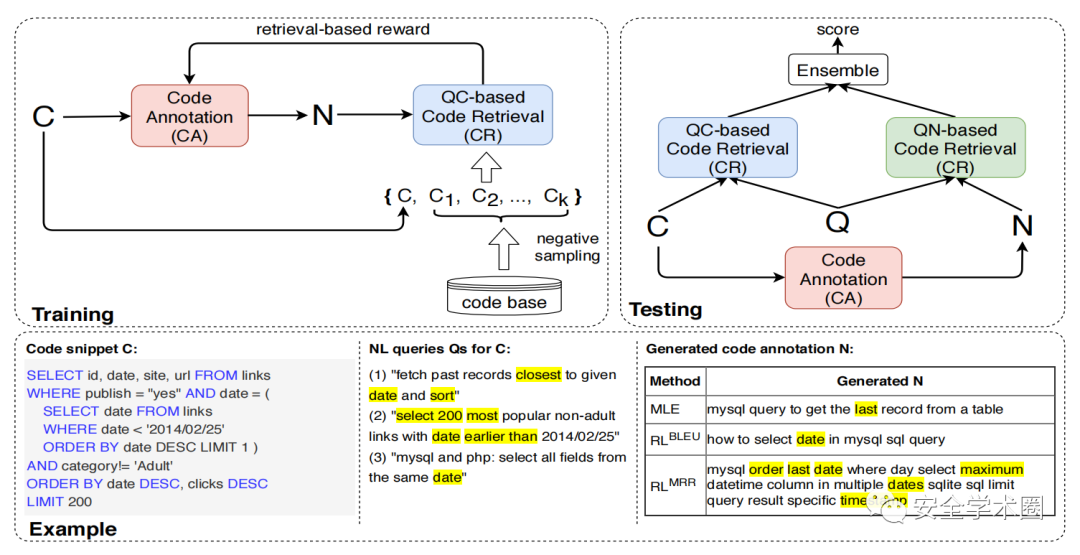
Fig. 1 系统框架
模型中使用的强化学习机制可以概括为一个马尔科夫决策过程:给定代码片段C,代码注释模型生成自然语言单词序列作为其注释。在注释序列的末尾,让基于QC的代码检索模型使用生成的注释在代码库中检索相关的代码片段。软件检索到的代码片段能排在Top N中,则说明生成的注释很好,应该得到积极的奖励;否则获得消极的奖励。文章使用优化的Actor-Critic算法训练代码注释模型以最大化它从基于QC的代码检索模型中接收的奖励。如图2所示,给定自然语言查询 ,代码片段 ,通过Bi-LSTM+maxpooling+tanh结构获得嵌入向量 和 ,使用余弦相似性度量查询和代码片段之间的相关性。
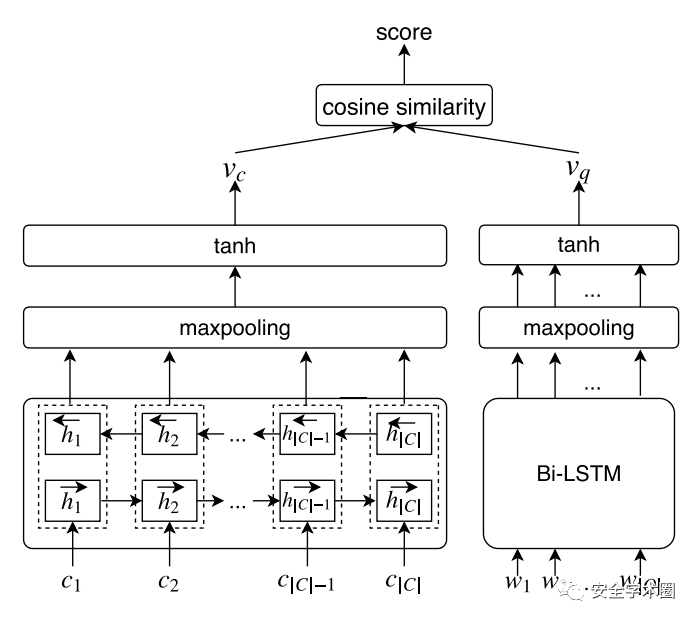
Fig. 2 基本代码检索模型
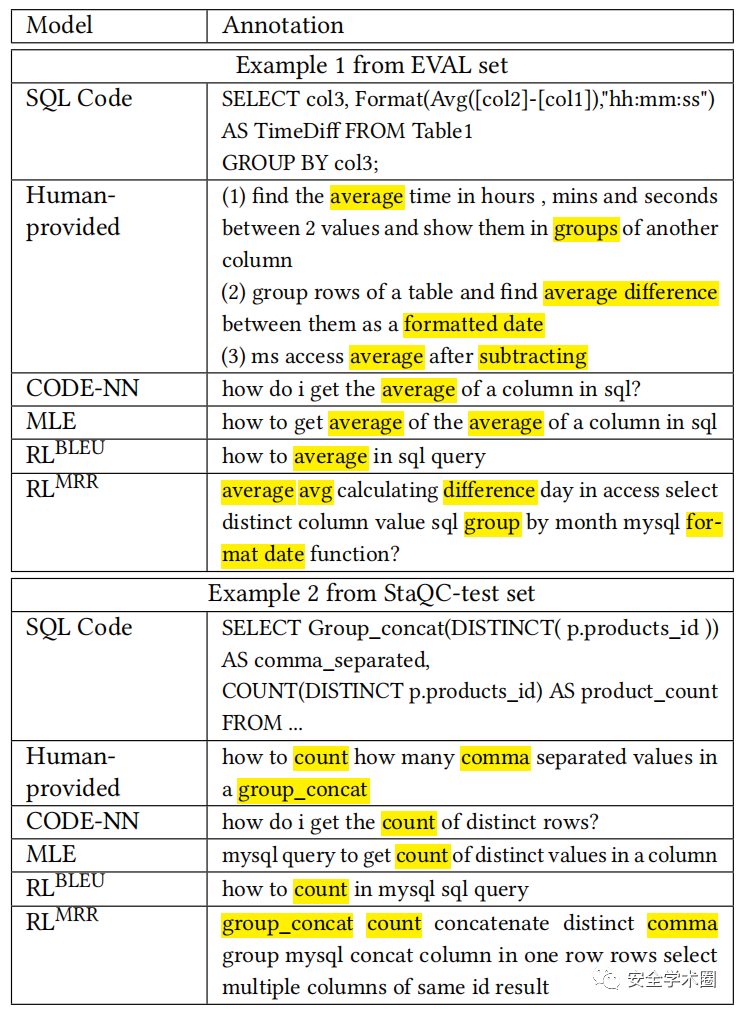
Fig. 3 代码注释模型对比
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
