复旦大学CodeWisdom团队研究论文《Predicting Change Propagation between Code Clone Instances by Graph-based Deep Learning》获得CCF推荐的B类国际会议International Conference on Program Comprehension (ICPC 2022)的ACM SIGSOFT Distinguished Paper Award。
复旦大学软件工程实验室(CodeWisdom团队)在与多个企业的代码克隆检测和管理的技术合作中,针对企业开发人员在克隆代码一致性维护中遇到的实际困难,设计了一套基于图神经网络的模型,针对克隆代码的文本和结构信息以及克隆代码修改的上下文进行大规模训练,从而能够针对克隆代码的修改来预测哪些克隆代码副本(或克隆实例)需要发生相同的修改。
相关研究论文《Predicting Change Propagation between Code Clone Instances by Graph-based Deep Learning》近日在在线举办的ICPC 2022中获得ACM SIGSOFT Distinguished Paper Award。
作者包括博士生胡彬、硕士生王晓晨、硕士生傅百强,以及吴毅坚、彭鑫、沙朝锋、赵文耘老师。
如何确定代码克隆的多个实例是否需要进行相同的修改,一直以来困扰着程序员。特别是面对相似但不完全相同的克隆代码,上下文存在差异的情况下,程序员往往需要仔细阅读相关代码,才能判断是否要将其他克隆实例的修改应用到当前的代码克隆实例上。本项研究通过对51个开源项目中提取的6万余代码克隆修改情况进行分析,采用基于图神经网络的深度学习方法训练了一套预测模型,从而辅助开发人员进行克隆代码修改传播的决策。
代码克隆的修改传播现状摸底
论文首先选取了5个开源项目(Maven, Ant, DBeaver, Tomcat, Camel)开展了代码克隆的修改传播现状摸底。通过从代码版本历史中提取代码克隆对的修改情况,识别出“匹配修改”和“非匹配修改”,从而发现一个克隆对中可能会同时存在“匹配修改”和“非匹配修改”。这表明,对一个克隆代码片段的有些修改需要传播到另一个实例,而有些修改则不需要传播。
图2给出了一个克隆代码对在两次不同的提交中,分别进行了一次不需要传播的修改和一次需要传播的修改。而且,在需要传播的修改中,存在相当一部分并不是在同一个提交(commit)中修改的,而是延迟了一段时间、在另一个提交中才发生的。而这种延迟一致性修改并不罕见(Tomcat项目中有38.2%的相同修改为延迟修改),因此需要纳入考虑范围。

图2 修改传播实例
在第一次提交中,实例1的if条件判断中增加了dir.isFile(),而实例2没有增加该条件。我们在实例1的第12行发现了dir变量的声明,而实例2中对应位置声明的是contentXml,因此本次修改不需要传播到实例2中。在第二次提交中,虽然两个实例中的if表达式内容不相同,但是由于都包含toLowerCase方法,因此同时都增加了参数Locale.ENGLISH,从而使得代码符合规定字符集的要求。由此可见,对克隆代码实例的修改是否需要传播到另一个实例,是与克隆代码修改的内容本身以及修改点的上下文紧密相关的。
用图来表示代码克隆的修改
对于一个代码克隆对(S1,S2),如果对S1做了一些修改(代码修改集记为D)变为代码片段S1",那么我们可以把这种修改表示为三元组(S1,S1",S2)。这个修改集D是否需要传播到,可表示为代码克隆的修改传播需求RD :
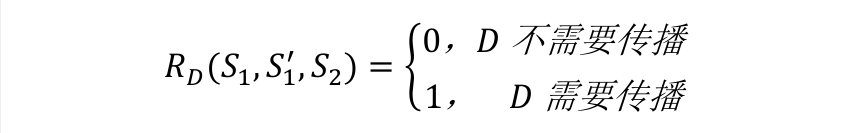
于是,我们可以将克隆代码的修改传播需求预测转化一个二分类问题。通过结合大规模的代码克隆实例的训练,将一次克隆代码的修改(S1,S1",S2)判定为是否需要传播的二值结果。
然而,这样的模型需要充分提取代码克隆的文本、结构特征以及克隆修改的内容和上下文,而且在我们的摸底研究中也发现,这种特征是非常复杂的,因此,我们选择了深度学习的方法,并将克隆代码及其修改建模为图,并采用图卷积网络进行训练。
01 图构建
首先,针对克隆代码修改(S1,S1",S2),我们对S1,S1",S2三片代码各自的程序依赖图(PDG)(图3(a))。同时我们对每个节点赋值一个存在性向量来标记该节点的存在位置,S1,S1",S2三片代码中的节点的存在性向量分别为(1,0,0),(0,1,0),(0,0,1)。然后我们利用现有的差异比较算法建立PDG节点之间的映射关系(图3(b))。最后,我们将节点映射后的PDG中具有相同代码内容的节点进行合并,并将存在性向量进行按位或计算,从而得到简化的图结构(图3(c))。我们将这种新的图结构称作融合克隆程序依赖图(Fused Clone PDG,FC-PDG)。这种图既能减少克隆代码中重复部分的表示,又保留了克隆实例之间的差异以及实例修改前后的情况,因此很好地表示了代码克隆对以及克隆实例修改的信息。

图3. 融合的克隆代码程序依赖图生成流程
02 模型训练
FC-PDG是一个异构图(因为存在不同类型的边)。为了处理该异构图,我们设计了一种基于关系图卷积神经网络(R-GCN)的模型。如图4所示。首先,采用CodeBert生成FC-PDG中每个节点对应代码的768维向量表示。再接上3维的存在性向量,从而得到一个771维的节点向量表示。然后将该图输入R-GCN,通过两个卷积层得到400维内部表示,最后通过一个全连接层转化成一个二维的向量表示,并通过softmax输出最终的修改传播需求概率分布。该模型的细节可以查阅论文。
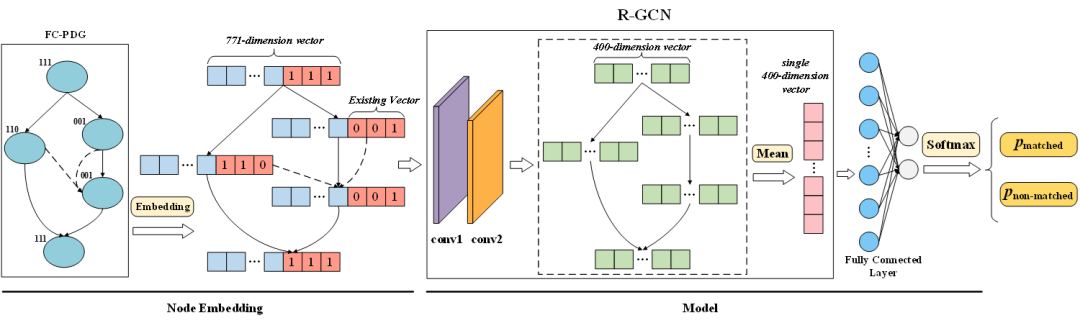
图4. FC-PDG节点表征及图模型结构
方法评估
为了训练修改传播预测模型,我们首先需要构建一个高质量的数据集。数据集中要包含有传播需求的修改,也要包含没有传播需求的修改,同时还要保证数据的多样性,避免单一类型的数据带来的过拟合,以此提高模型的泛化能力。基于51个Github开源项目,我们构建了克隆代码修改传播数据集,共包含24,672对已经传播的修改(包括一致性修改和延迟修改),以及38,041个未发生传播的修改。
基于构建的数据集,我们尝试回答了以下三个研究问题,以此验证和评估本文提出方法的有效性、泛化能力以及模型参数的效果。
RQ1:基于FC-PDG的深度学习模型在预测克隆代码修改传播需求方面的有效性如何?
RQ2:基于FC-PDG的深度学习模型的泛化能力如何?
RQ3:基于FC-PDG的深度学习模型超参数配置对预测结果有何影响?
01 有效性
通过文献调研,我们发现目前没有相关的方法是从克隆代码的变化出发来预测代码的变化传播需求的。为了做对比实验,我们从本文模型出发,设计了几个变体模型,以此来验证模型的有效性。变体模型如下:
Statement-Mapping模型:本方法依据克隆对中的两个实例中的表达式的对应关系来预测修改的传播需求,如果修改发生在两个实例中相对应的表达式上,则判定为有传播需求,反之,则没有。
CodeBert模型:给方法将修改对应的三元组中的S1,S1",S2三个代码片段串联成一个连续的字符串,并将该字符串作为CodeBert的输入,输出为二维向量,并基于输出来判定修改传播需求。
FC-PDG w/o EV模型:该模型将FC-PDG中的存在性向量移除,以此来验证存在性向量对于最终预测效果的提升作用。
MC-PDG模型:该模型直接以映射的PDG图作为输入,每个节点都维持原样,节点的向量表示中不引入存在性向量。

表1. 修改传播预测的召回率和精确率
表1显示了每个预测模型的精确度、召回率和F1评分。我们还分别列出了本文模型在标准模式和保守模式(即将“有传播需求”的概率阈值设到0.9,提升预测为需要传播的准确性)下工作的效果。总体来说,我们在标准模式下的方法优于其他模型,F1评分为0.821。保守模式下的精确度较高,这是一个预期的结果,因为在实践中我们希望使用保守模式实现较少的错误预测。
02 泛化性
在实际使用中,训练好的模型会被用于不同领域,不同维护时长的项目的克隆代码修改传播预测。为了验证本模型的泛化能力,我们选取了三个没有纳入模型训练数据集中的开源项目Neo4J、AnkiDroid、KubernetesClient,采用我们已经训练好的模型对这几个项目中的克隆代码修改传播情况进行预测,并与实际的代码克隆修改传播情况进行对比。我们发现,这些项目都体现出较好的效果。对有传播需要的预测召回率总体略高于精确率,表明在实际代码中,我们的预测结果与这些项目的代码克隆实际维护情况有较高的匹配度。而其中存在与实际维护不一致的情况,也进行了进一步的案例分析。

表2. 修改传播预测的实际预测效果
03 超参数选择
表3所示为隐藏层数量对预测效果的影响。我们发现,当隐藏层数大于2时,准确率、召回率和F1评分并没有提高。这说明我们选择两层隐藏层是合理的,这种设置在保证有效性的同时简化了模型结构,提高了训练效率。
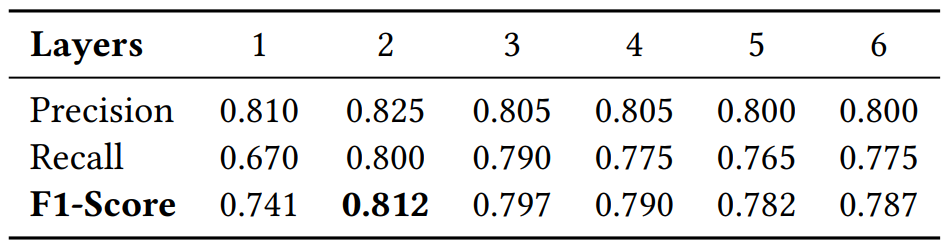
表3. 不同隐藏层数的R-GCN模型的预测效果
表4给出了R-GCN的隐藏层维度发生变化时的预测结果。当隐藏层维度设置为400时,F1评分达到最大值。根据这个结果,我们的模型中隐藏层维度也设为400,从而最大化模型的预测效果。
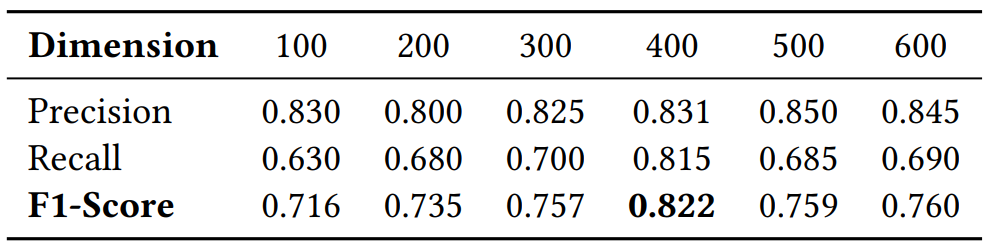
表4. 不同隐藏层维度的R-GCN模型的预测效果
04 案例讨论
本文研究还深入探讨了一些特殊情况。例如,由于本模型的数据来自开源项目的真实克隆代码维护情况,因此不可排除有些代码克隆的修改本身就在其他克隆实例上遗漏了。对于这些修改,我们的模型的预测结果如果提示需要进行修改传播,那么由于实际代码未修改而被判为“假阳性”(即修改未发生传播,但预测为有修改传播的需求)。
但通过仔细阅读这些案例,我们发现,部分所谓的“假阳性”正是我们发现的可能遗漏了所需修改的克隆实例。这对于发现代码克隆的遗漏修改,具有重要的价值。同样,也有一些“假阴性”(即修改已经传播,但被预测为不需要传播修改)的案例,我们发现这些案例恰恰是由于修改代码的上下文在两个不同的实例中存在较大差异,因此也说明了我们的模型达到了预期的捕捉代码克隆修改上下文的目的。后续可以通过进一步程序分析技术,来提升预测的效果。
结束语
软件项目中的克隆代码给开发人员带来了不少维护的困难。哪些克隆代码的修改需要传播到哪些克隆代码副本中,困扰着众多程序员们。相似但不完全相同的克隆代码,考验着程序员们的勇气和耐心。通过基于图神经网络的深度学习方法对大量克隆代码的一致性维护情况进行分析,能够为开发人员的克隆代码一致性维护决策提供一些帮助,也为进一步有效管理和重构消除克隆代码提供了可能的途径。
声明:本文来自CodeWisdom,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
