我们生活在一个信息横流的时代,有时不免会受到网络上虚假信息的干扰。大多数时候,网民并不是假新闻的直接制造者,而更多是扮演传播者的角色。而散播谣言与捏造谣言一样,也会带来严重的后果,例如 2016 年美国大选期间在社交网络上疯传,被指左右了民意的假新闻,再比如今年通过 WhatsApp 平台传播,最终导致印度十余人因私刑而死亡的虚假流言。
据科技媒体 Science News 报道,全球多个科研团队已在研发可自动识别新闻真伪的程序。它们的主要功能是对新闻的可信度做一个初步的鉴定,并将结果传递给读者以供其参考。
印第安纳大学布鲁明顿分校的计算机科学家 Giovanni Luca Ciampaglia 表示,业内对这种鉴定算法的开发目前普遍处于起步阶段,对于一篇报道,选取哪些因素作为判定其可信度的方法也是五花八门。
不过这些程序对一则新闻的关注点大致可分为两类:报道的内容和叙述的口吻。
上文提到的 Ciampaglia 和他的科研团队就着眼于报道的主要观点,主语和宾语间的联系有无客观事实支撑。他们的算法收纳了大量 Wikipedia 词条页面的右侧信息栏(“Infobox”)中的信息,并将主词条与所有副词条配对,形成一个以名词及名词间联系为主的数据库。如果一篇报道的主要观点中,主语与后面的描述性名词之间的联系能在该数据库中以较短路径追溯到,那么这条新闻的主旨就相对可信。
比如“奥巴马是个穆斯林”这句话中,“奥巴马”和“穆斯林”之间存在 7 重联系,也就是说在数据库中需要跨越 7 组名词间的两两配对才能将这两个词扯在一起,这说明该言论是不太靠得住的。

图|奥巴马 wiki 页及右侧的 infobox(来源:Wikipedia)
但这种基于名词间关联强度的判定方法也有一定局限性。比如,它无法判定“George W. Bush(小布什)娶了 Barbara Bush(芭芭拉·布什,小布什老妈)”这句话的真伪,因为在数据库中这两个名词高度相关。因此 Ciampaglia 也正设法为他的算法添加其他参数以提升其合理性。

图|“奥巴马”与“穆斯林”间的 7 重联系(来源:Science News)
美国伦斯勒理工大学的计算机科学家 Benjamin Horne 和 Sibel Adali 则提出了另一个方法。他们分析了由 Business Insider 评定的最值得信赖媒体发布的 75 篇真实报道,以及网上公认的 75 篇伪新闻,随后总结出:假新闻通常篇幅比真的短,会重复性地出现许多副词,其中的引述和专业词汇也相对更少。
他们由此建立了一套以文章所含名词数量、引述数量、冗长度以及总字数为参数的评定算法。该算法曾在去年于加拿大蒙特利尔举行的网络与社会媒体国际研讨会(International Conference on Web and Social Media)上做现场演示,并在辨别假新闻时准确率达到了 71%。
密歇根大学安娜堡分校的计算机科学家 Verónica Pérez-Rosas 同样发现假新闻中的副词使用频次要高于真新闻。在 2017 年 8 月发布于科学文献数据库 arXiv.org 的研究报告中,Pérez-Rosas 也提出,假新闻会使用更多正面措辞,并且更喜欢下结论。
图|Pérez-Rosas 总结出的真(左半)假(右半)新闻分别惯用的词汇(来源:Science News)
由此可见,假新闻在写作手法上有共通之处。加州大学河滨分校的计算机科学家 Vagelis Papalexakis 就根据两篇报道间的行文相似度来判定它们的真伪。虽然他在研究报告中并未明确列出衡量相似度的具体参数,但在包含真假新闻各 32000 个的数据库中,他的算法能在预知其中 5% 的文章哪些是真哪些是假的情况下,以 69% 的准确率判定出其他文章的真伪。
社交网站可以用这些算法来给新闻做初步检查,并在用户打开一篇疑似假新闻时,给用户发一个预警提示。比如目前 Facebook 就会在后台监测哪些新闻下多了质疑性评论,然后专业人员会对这些新闻做出评定,并将评定结果录入 Facebook 原先的自动鉴别算法所用数据库中,从而实现算法的优化。
英国帝国理工学院的计算机科学家 Julio Amador Diaz Lopez 表示,即使目前这些鉴定算法演化得越来越“聪明”,但面对背景较抽象,如宗教、哲学等方面的报道,程序可能还是无法像人类一样会意,或辨识其可信度。同时,如果从写作风格着手的鉴伪程序被广泛采用,那原先假新闻的作者也会适当地改变自己的写作手法以图蒙混过关。
幸好,目前业内已出现了不只关注文字本身的算法。中国科学院计算技术研究所的曹娟提出的算法就着眼于读者的反馈模式。她将微博上用户对新闻的观点分为支持和反对两类。比如对于一条地方新闻,地理位置更接近事发地点的用户做出的评论就比相距较远的读者的反馈更具可信度。再比如一个隐身很久但突然冒出来给一条新闻评论的用户,他的言论可信度也就较低。
曹娟的团队选取了微博上传播的真伪新闻各 73 条,他们的算法通过分析这些新闻下共约 5 万条持支持或反对意见的评论,最终以 84% 的正确率识别出了假新闻。该研究成果也曾在的美国人工智能进步协会(Association for the Advancement of Artificial Intelligence)2016 年大会上展出。
同样,来自北京航空航天大学的网络专家李大庆教授也未把内容作为鉴伪程序的重心,而是把新闻的传播形式当作主要评判依据。他收集了微博上 1700 条假新闻、500 条真新闻,以及推特上真假新闻各 30 条,分析了它们的扩散特征后发现,真新闻的传播主要是靠用户从单个可靠消息源的直接分享,而假新闻的传播则主要依托用户间的分享。
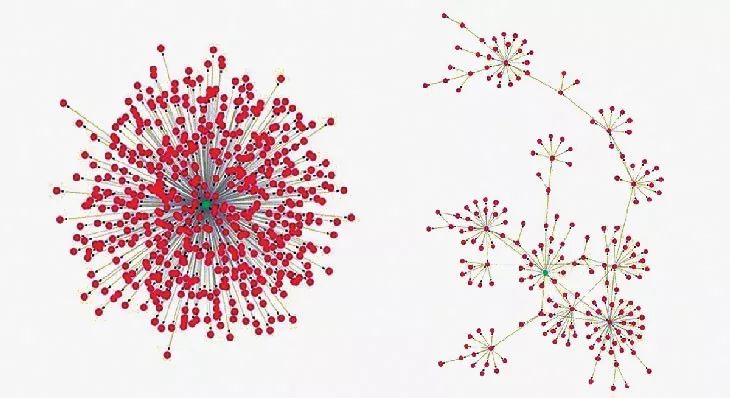
图|李大庆教授发现的真(左)假(右)新闻主要传播形式(来源:Science News)
再回到这些算法的实际应用——社交网站现阶段还不宜单单依据算法判断的结果,将所有疑似假新闻一律屏蔽,这样相当于以极权主义干涉了用户自主选择浏览信息的权利。Facebook 目前的做法是将系统鉴定出的低可信度报道自动置于推送栏底部,据公司发言人 Svensson 表示,这样可以将虚假新闻的阅读量减少约 80%。另外,前文提到的根据初步鉴定结果给用户发警示消息,也可能成为未来社交网站上对此类算法的应用形式之一。
声明:本文来自DeepTech深科技,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
