后门攻击通过在训练样本中添加恶意触发器,对模型安插后门并在测试阶段控制模型的预测结果。后门攻击无疑对深度模型的安全训练和部署提出了巨大挑战。针对上述问题,由西电网信院、迪肯大学,索尼AI,墨尔本大学和UIUC合作完成的Anti-Backdoor Learning: Training Clean Models on Poisoned Data的后门防御论文在NeurIPS2021上发表。本文首次提出了反后门学习理论和方法,它旨在有毒的后门数据上训练出一个干净的模型。
本文首先总结了现有后门攻击中固有的特征:1)模型学习后门数据比学习干净数据的速度要快得多,并且攻击越强,模型在后门数据上收敛越快;2)后门任务中,后门样本与后门目标类存在强相关性。基于这两个特征,作者提出了一种通用的反后门学习(ABL)方法,以在训练过程中加固模型安全。
ABL引入了两阶段的梯度上升机制。第一阶段利用后门攻击的第一个特征并结合局部梯度上升机制(LGA),用于隔离出训练数据中一小部分的后门样本。第二个阶段利用全局梯度上升机制(GGA)来打破后门样本与后门目标类的强相关性。具体公式如下:
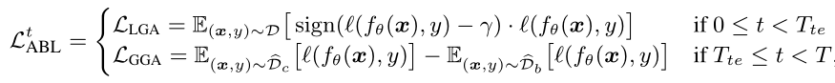
LGA能在一段时间内保留干净和后门样本之间的差异,进而达到筛选后门样本的目的。GGA则是将后门任务看作是一个双任务学习过程,最小化干净样本推理损失并最大化后门样本推理损失。
本文在3个基准数据集上对当前最先进的10种后门攻击进行了防御,并和3种防御方法进行了对比,实验结果如图1所示,结果表明本文提出的反后门学习方法能够取得模型层面后门防御的平均最佳效果。
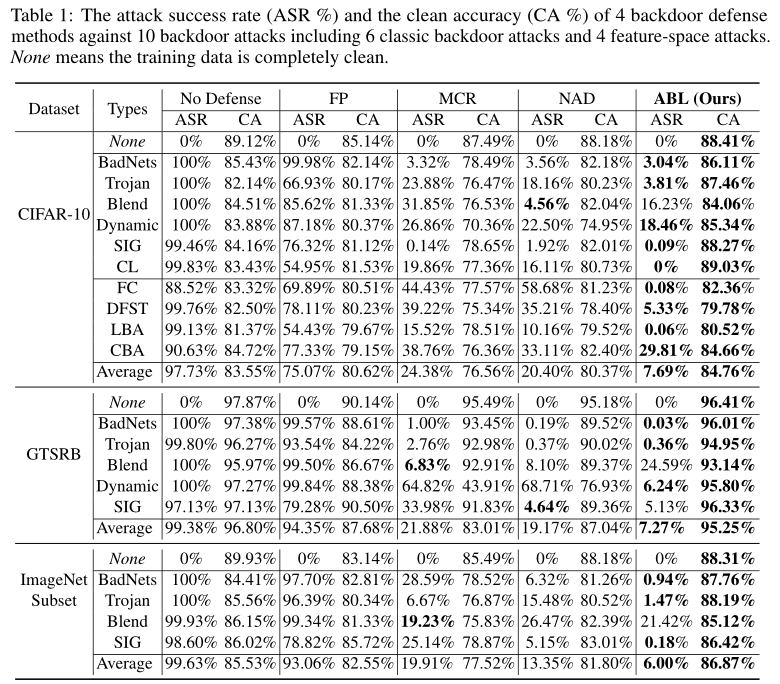
图 1 ABL与3种防御方法对10种后门攻击的防御效果对比结果
在使用不同后门样本隔离比率时,作者发现只要一小部份被隔离的后门样本就可能打破后门样本与后门目标类的相关性。
此外作者还提供了不同隔离方法和不同遗忘学习的方法的对比,并且提出ABL方法也可以帮助其他防御设置的防御方法。例如结合Neural Cleanse,对一组触发模式进行反向工程,然后通过最大化含有反向工程触发模式样本的推理损失,从模型中剔除后门。实验结果如图2。
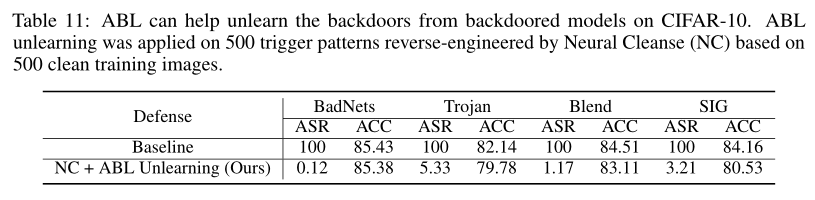
图 2 ABL结合防御方法Neural Cleanse的实验结果
作者已经开源该项工作的源代码,并给出基准供参考对比。项目开源代码地址:https://github.com/bboylyg/ABL
参考文献
Li, Yige, et al. "Anti-backdoor learning: Training clean models on poisoned data." Advances in Neural Information Processing Systems, 34 (2021): 14900-14912.
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
