
深度学习技术的引入显著提升了图像隐藏方法的隐藏容量,但是现有方法的主要挑战在于难以平衡载体图像的嵌入误差和秘密图像的恢复误差。本文设计了一种联合压缩自编码器(Joint compressive autoencoder,J-CAE)框架的图像隐藏算法,以及一种用来扩大隐藏容量、实现多图像隐藏的新策略。本文中的方法实现了极高的图像隐藏容量和较小的秘密图像重建损失,更重要的是,方法通过映射图像在J-CAE模型隐空间中的表示,解决了现有方法存在的平衡问题,从而实现载密图像的高视觉质量和秘密图像的低重建误差。
提出方法包括三个阶段:①双CAE训练阶段(Dual CAE training phase);②隐藏阶段(Hiding phase);③提取阶段(Extracting phase)。
图1为双CAE训练阶段的训练流程和编解码器的详细结构。这些模型学习不同的非线性映射函数,以在不同维度的二值化隐空间中表示图像,以及高质量地重建图像。编码器 和 分别学习将自然图像编码为长度为 和 的二进制向量,而解码器 和 分别学习将向量解码为图像。
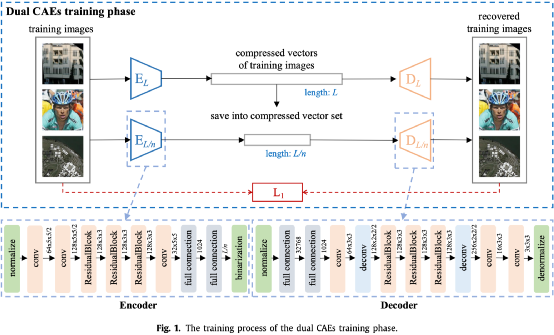
图2为提出方法的隐藏阶段,在该阶段中发送者使用训练好的CAE模型和混沌映射机制(chaotic mapping system)来实现多图像的隐藏。具体流程描述如下:首先使用编码器 将张秘密图像编码并拼接为长度为 的二值向量 ,然后从训练阶段随机选择一个载体图像的二值向量 并使用解码器 解码为载密图像,最后使用混沌映射机制使用密钥加密二值向量以进一步提高安全性。
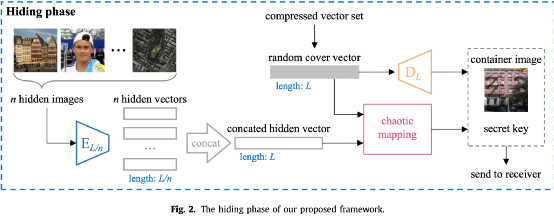
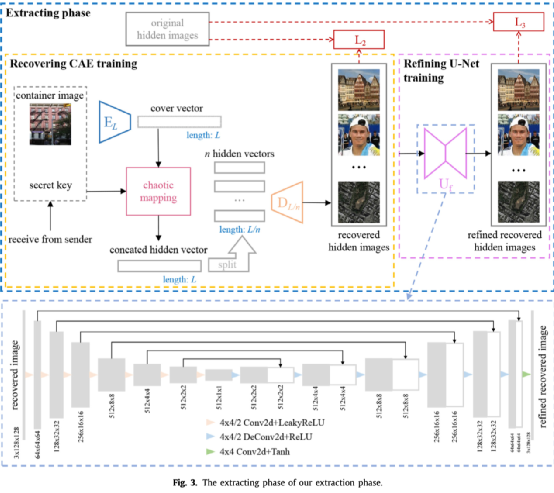
图3为提出方法的提取阶段,该阶段首先使用编码器 提取载体向量,然后使用混沌映射机制根据密钥提取并拆分出 个隐藏向量,再使用解码器 还原秘密图像,最后使用U-Net结构的修复网络 进行进一步修复。这一阶段需要对编码器 、解码器 和修复网络 进行训练,以提高还原秘密图像的质量。
在单张载体图像中隐藏1/2/4张秘密图像时的嵌入损失和提取损失分别如表1,表2和表3所示。可以看出,本文提出的方法在嵌入和提取方面都取得了最低的平均像素误差(pixel error)、最高的峰值信噪比(PSNR)和结构相似度(SSIM),也即更好的不可感知性和重建质量。此外,相对于其他方法,可以看出提出方法隐藏图像数量的增加并不会影响其嵌入损失,这得益于独特的设计。
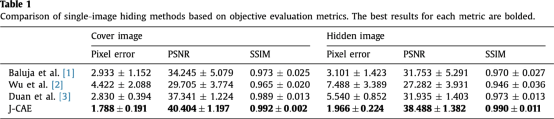


图4所示为隐藏4张秘密图像时的嵌入和提取效果,其中(a)为原始的载体图像和秘密图像,(b)/(c)为现有方法的载密图像和提取秘密图像,以及和原始图像之间的残差图像(强度提高5倍),(d)/(e)为提出方法的载密图像和提取秘密图像,以及和原始图像之间的残差图像(强度提高5倍)。可以看出提出方法在隐藏图像数量很高时,仍能保持出色的视觉不可感知性和重建质量,且显著优于现有方法。

参考文献
Liu X, Ma Z, Chen Z, et al. Hiding multiple images into a single image via joint compressive autoencoders[J]. Pattern Recognition, 2022: 108842.
作者:刘熙尧,中南大学计算机学院
联系方式:lxyzoewx@163.com
个人主页:https://faculty.csu.edu.cn/liuxiyao/zh_CN/index.htm
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
