IEEE x ATEC科技思享会是由专业技术学会IEEE与前沿科技探索社区ATEC联合主办的技术沙龙。邀请行业专家学者分享前沿探索和技术实践,助力数字化发展。
在万物互联的大数据时代,数据链接了我们生活的方方面面。一方面,大数据极大便利了我们的工作与生活;另一方面,数据的海量化也增加了诸多隐私信息泄露的风险与挑战。本期科技思享会邀请到了四位重磅嘉宾,共同围绕“隐私保护的前沿技术及应用”这个主题,分别从机器学习算法、通讯协议、APP及操作系统等不同层面,就隐私安全风险及技术创新应用展开讨论。
以下是德国CISPA亥姆霍兹信息安全中心研究员张阳的演讲《量化机器学习模型的隐私风险》。

演讲嘉宾 | 张 阳
德国CISPA亥姆霍兹信息安全中心研究员
ATEC科技精英赛高级咨询委员会专家
《量化机器学习模型的隐私风险》
大家好,我是张阳,我来自德国亥姆霍兹信息安全中心。今天我分享的主题是《量化机器学习模型的隐私风险》。
我们已经进入了机器学习的时代,机器学习的模型被应用在诸多领域,包括自动驾驶车、人脸识别、家庭智能助手在内的一系列应用都是由机器学习来提供技术支持。

机器学习在过去20年有了长足的发展,核心原因是智能化时代每时每刻每分每秒都在产生大量的数据,因为数据的质量、数据的精细度越来越好,我们的模型表现也越来越好。但很多情况下,机器学习模型基于有隐私风险的数据进行训练,比如医生用生物样本去判断疾病,或者更常见的例子是当我们每天用各种各样的软件打字,会发现一段时间以后,我们打出字的下一个提示词会越来越准确。因为机器每天在学习你会打出什么样的句子,它把这些数据学习了以后会反馈给模型,让模型表现得更好。虽然机器学习应用越来越强大,大家生活也会越来越方便。但换一个角度想,这些数据包括了很多隐私信息,如果机器学习模型训练好之后隐私数据泄露了,就会造成很大的风险。
所谓量化机器学习模型隐私风险的研究方向,就是在研究一个机器学习模型训练好后会不会泄露它的数据隐私。

今天的Talk会分为三个部分。我首先会分享成员推理攻击,第二会分享数据重构攻击,第三个是分享链路窃取攻击。其中,第二个分享是针对特殊的在线学习,第三个分享是针对于一种特殊的神经网络模型,叫图神经网络。
Membership Inference

我给大家讲数据成员推理攻击之前会给大家快速回顾一下机器学习的一个简单流程。现在做机器学习比以前要简单得多,你只需在网上下载一个你最爱的数据集,然后打开你喜欢用的库,选你最喜欢的模型,再把数据集拿到模型上训练。模型训练好之后,(比如说做一个图片分类模型)拿一张图片放到这个模型里去,这个模型会告诉我:这个图片有80%概率是一只熊猫,10%是一只狗,10%是一只猫,这就是很典型的机器学习流程。
所谓的成员推理攻击(Membership Inference),就是我想知道这一张图片是不是在原模型的训练集里。而从一个攻击者的角度,你只能去用这张图片去探测模型产生它的输出,然后用这个输出来判断它是member还是非member。你当然是没有原始数据信息的,因为如果有原始数据信息,只要轻松地做一个查表,攻击就可以完成。

我今天分享的是我们2019年的一篇paper《ML Leaks》,我们不是第一个做成员推理攻击的小组,第一个做的大约是2017年Cornell Attack的一个组。我给大家快速回顾一下他们的工作:我有一个Target Model,和一个Target数据集,假设本地攻击者有一个Shadow数据集,这个数据集和Target数据集来自于同分布的。攻击者把它的Shadow数据集分成两部分,Training和Testing。训练集就训练一堆所谓的Shadow Models(影子模型)。这里的影子模型的影子是指Target Model的影子。如果Target Model是一个猫、狗、熊猫的三分类,那么影子模型也是猫、狗、熊猫的三分类。你也可以假设它的影子模型的结构和Target Model也是一样的。
如果Shadow Models训练好了以后,再把训练集和测试集全部送入Shadow Models,会产生训练集和测试集里每一个sample的output值。所有Shadow训练集,就是Shadow Models的成员,所有的Shadow Models的测试集,就是Shadow Models的非成员。这么做就产生了label的数据集,可以去训练攻击模型。成员推理攻击是一个二分类,一个sample只可以是member或非member,没有第三种可能性。所以,所有的Shadow Models、一整套的流程、一系列的操作只是为了构建数据集去训练Attack Model。这里Attack Model(攻击模型)也是一个机器学习模型。因为我的目标还是想知道这个熊猫图片(sample)是不是Target Model的一部分。那我把这个图片送到Model里去,Target Model产生了output,我把output放入攻击模型里去,攻击模型就可以告诉我这是不是一个成员。
成员推理攻击之所以可以成功,核心原因就是过拟合。所谓的过拟合就是一个Model训练好以后,它会对训练过的图片(数据)更加自信,而对没见过的图片(数据)没有那么自信。通过这个“自信”的区别,就可以区分出一个图片是member还是非member。这个work便是Shokri et al.大约2017年做的,他们是第一个work。这个work里边有三个假设:第一个是攻击者本地有个数据集和原来的Model数据集是来自于同分布,这个假设当然没有问题,但问题是这个假设比较强。因为如果真的攻击一个顶级的互联网公司,它背后有大量的数据训练Model,它的数据集质量非常高,很难去要求一个攻击者有一个同样质量、甚至同分布的数据集,这个是很难的。第二个假设、第三个假设的前提是攻击者需要建立一堆影子模型和一堆攻击模型。而我们要做的是怎么去放松这些假设,把它做一个轻量级的成员推理攻击。如果我们轻量级的成员推理攻击也可以成功且表现得和原来差不多,那就证明了Attack可以通过很简单的方法进行攻击,而这就造成这个Attack对现实生活中的ML Model的威胁会相应地变大。因为你的攻击可以变得更简单,并达到同样的效果。
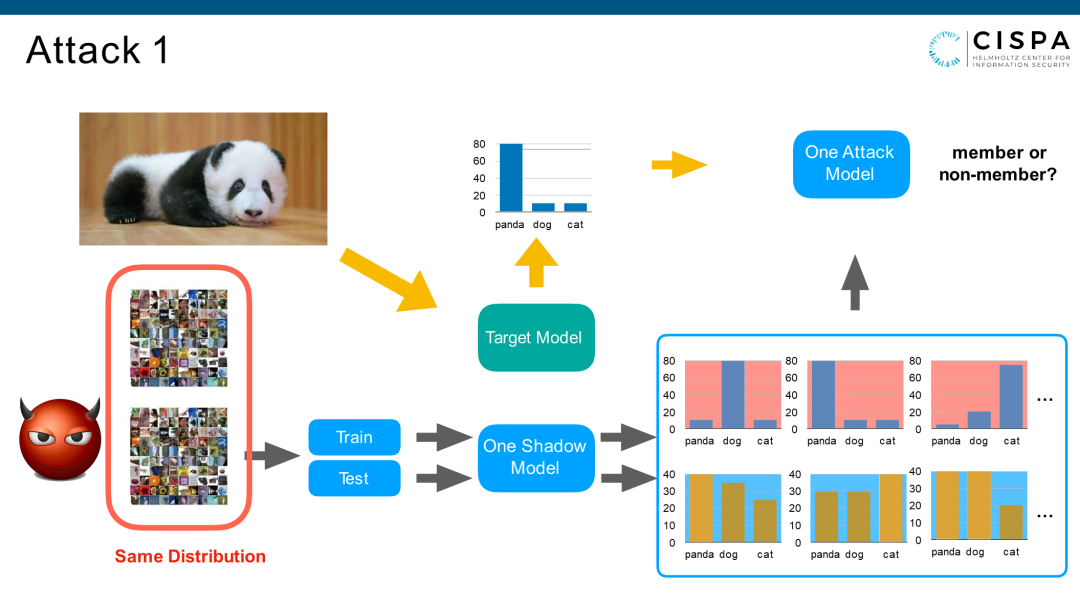
通过这个思路,我们做了三个攻击。第一个攻击本地训练一个Shadow Model、训练一个Attack Model。
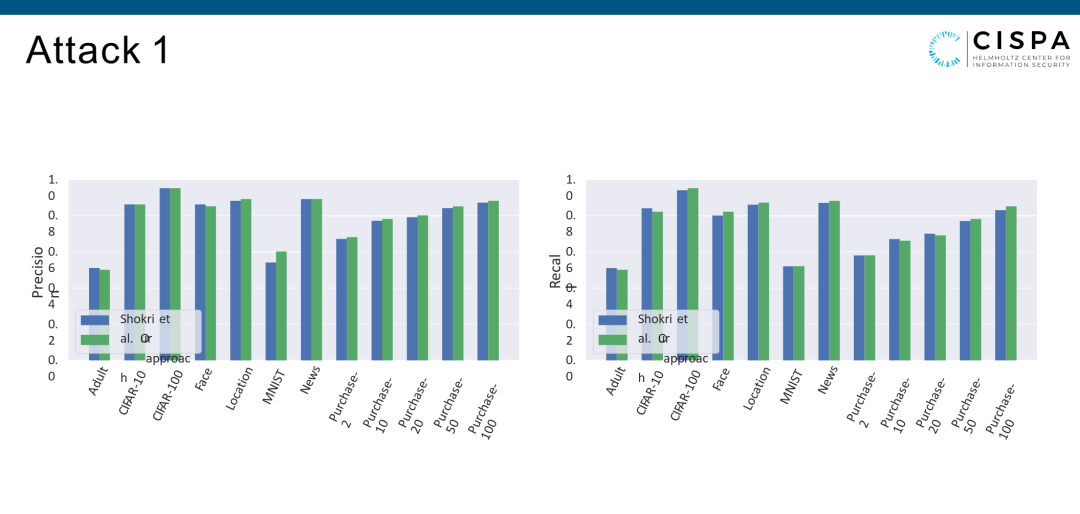
结果左边是Attack Precision,右边是Attack Recall。因为Membership Influence是二分类攻击,只可以是member或非member。绿色的柱子是我们的攻击,就是一个Shadow Model,一个Attack Model。蓝色的柱子是原来的攻击,多个Shadow Models,多个Attack Models。你会发现Precision、Recall在十几个数据集上表现差不多。就证明你不需要多个Shadow Models和多个Attack Models,一个就够。这种情况下,攻击者就省了很多的计算资源。
但这不是最核心、最要紧的假设,最要紧的假设还是Attacker在本地有一个和Target Model同分布的数据集。
那怎么去掉这个假设呢?
我们的方法是在本地找一个完全不相关的数据集,甚至模态都不相关。比如Target Model是一个image数据,我们在本地找一个自然语言数据集,它的数据形式表现都不一样。Target Model可能是一个三维的矩阵或者叫Tensor(张量),而本地只是一堆字符串。本地生成自然语言处理器,只要把数据集换了,剩下的操作一点不变,这样我们的攻击可以在多种情况下成功。

首先看一下结果,同样的,左边是Precision,右边是Recall。成员推理攻击二分类,所有这两个矩阵对角线上的点,就是Attack1的result,用同分布数据集去攻击同分布数据集。所有不在对角线的点,是非同分布数据集去攻击另一个数据集,即两个不相关的数据集相互攻击。你会发现多种情况下,两个图里颜色越深表现越好。总体来说,对角线表现当然是比较好的,但是好多情况下非对角线也表现得非常好,这就意味着Transfer Attack在大部分数据集上表现都会很好。
那这个攻击为什么可以成功呢?
是因为我们的攻击模型的input并不是一个图片或一篇文章,也不是一堆自然语言的字符串。我们的input是一个sample放到Target Model里去产生output的最大三维。
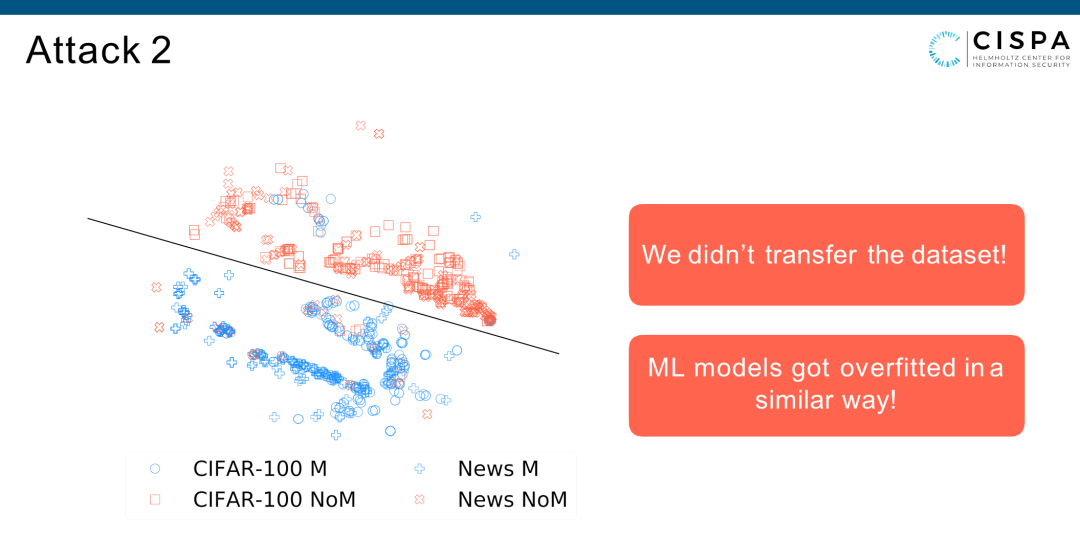
左边有一个图是它的TSNE plot。我们找了两个数据集,一个叫CIFAR-100、一个叫News 。CIFAR-100是一个图片数据集,News是一个自然语言数据,这是他们二维的分布。他们原来的维度是三维,这个三维是他们对应的Attack Model的input。比如说每个点对应的Attack Model的最大三维的后验概率。M意味着member,Non-M意味着Non-member。你会发现, CIFAR-100的member和Non-member分得比较开,News的member和Non-member分得也比较开。而更有意思是News的member与CIFAR-100的member基本处于一个区域,同样Non-member也处于一个区域。这就意味着如果本地的Shadow数据集,比如说CIFAR-100是图片数据集,通过这个数据集训练拿到的数据,然后训练Attack Model,可以把CIFAR-100的member和Non-member分开。那么这条线也自然而然可以把News的member和Non-member分开。
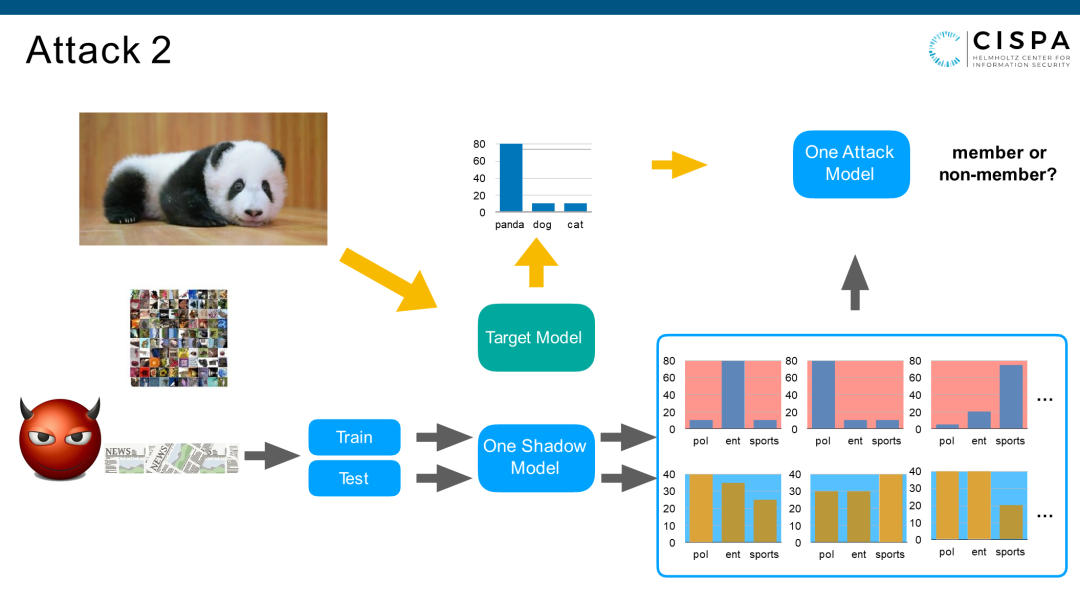
这就是为什么我们的Transfer Attack可以完成的原因。究其原因是我们并没有转换数据集,只是转换了Model和Model之间的Overfitting Behavior。或者换句话说,都对他的member过拟合了,那就意味着它们的Overfitting Behavior是比较相似的。就是说一个Model对一个member,自信度非常高。那么另一个Model对它的member的自信度也非常高。这两个自信度差值不大,就促成了我们的攻击可以进行,这是我们的第二大Attack。
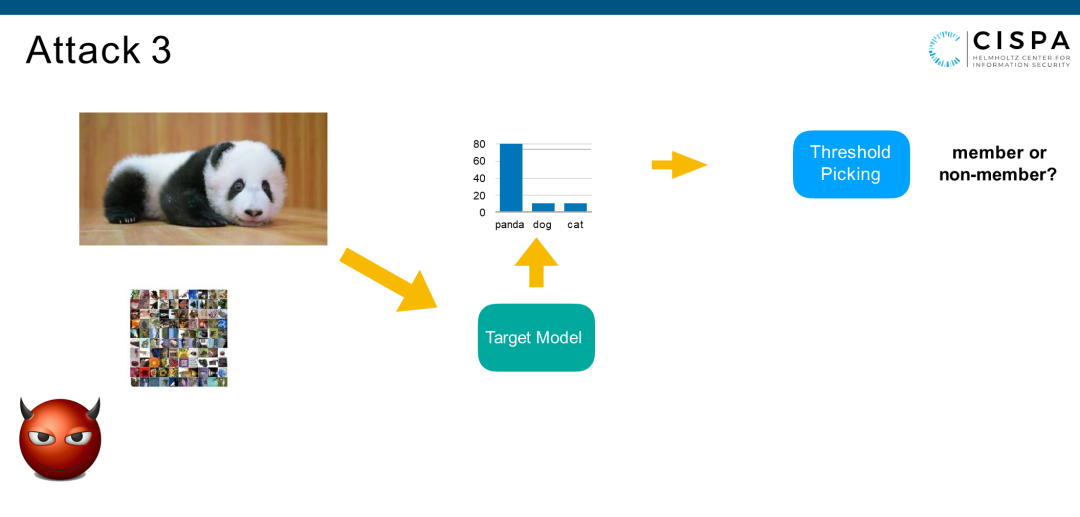
我整个Talk都在讲成员推理攻击的核心就是过拟合。那么第三个Attack,我们是不是可以把它做得更简单。因为过拟合完全可以只通过从Target Model产生output的postulate来体现。我们第三个Attack,不需要任何的Shadow Model,也不需要训练任何的Attack Model,你只需要把想确认的图片放入Target Model,在它最大的一维后验概率上设一个阈值,比如设成70%。现在最高的值是80%,80%高于70%。那我就认为这是一个member。这个Attack是最简单的,而且需要的资源是最少的。我们有一个怎么去自定义或者说怎么去寻找阈值的方式,今天时间有限就先不讲了,大家可以在这个paper里找到。
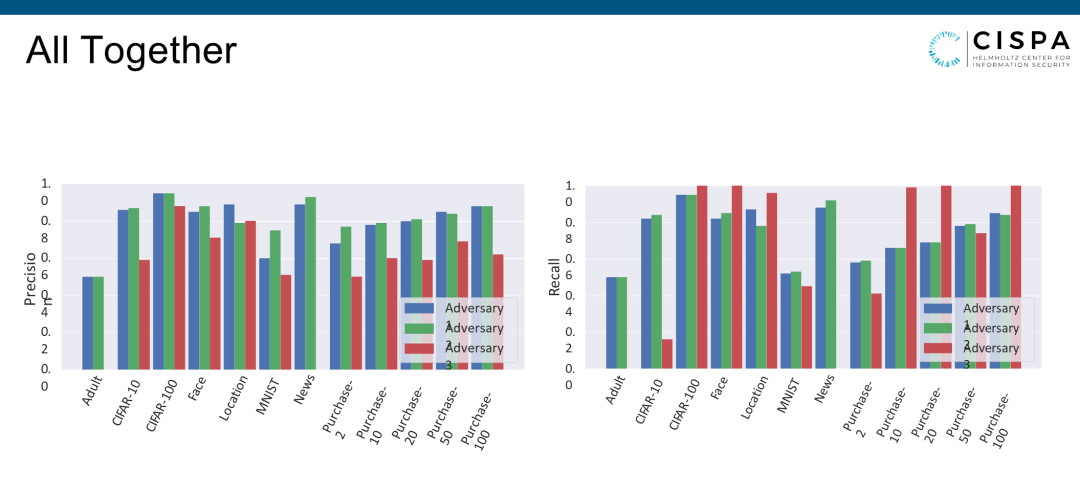
我已经介绍了三个Attack,Attack1已经比最原始的Attack简单。Attack2就更简单,因为其假设更少,本地不需要它的Shadow Dataset,Target Model Dataset是同一数据集的。Attack3可能更简单,因为它根本就不需要任何的Shadow数值集。这种情况下,我把三个Attack的表现放在一起比,Attack1和Attack2表现差不多(看左边的Precision和 Recall),Attack3在Precision上似乎差一点,但在Recall上比较强。如果我们的阈值再调得好一点,三个Attack会表现差不多。

这意味着什么呢?三种攻击表现差不多,一种攻击比一种攻击需要的资源少,就证明了成员推理攻击在一个很简练的情况下就可以被进行,说明了这个攻击对现实生活中产生的威胁会更大。

再讲一个我们在CCS2021的工作。我们之前讲的成员推理攻击,包括现在主流的大量的成员推理攻击,都有一个假设,即Target Model给你完整的postulate。比如说80%的熊猫,10%的狗,10%的猫。如果我们没有那个假设(因为很多情况下机器学习Model,可能只给你一个比较简单的Label),如果只给你一个Label告诉你这是一个熊猫,这种情况下还能做成员推理攻击吗?
过去的几年里,我们一直认为这是不可能的。但是去年我们发现,实际上这个也是可能的。在座的各位可能有好多是Trustworthy Machine Learning的专家。
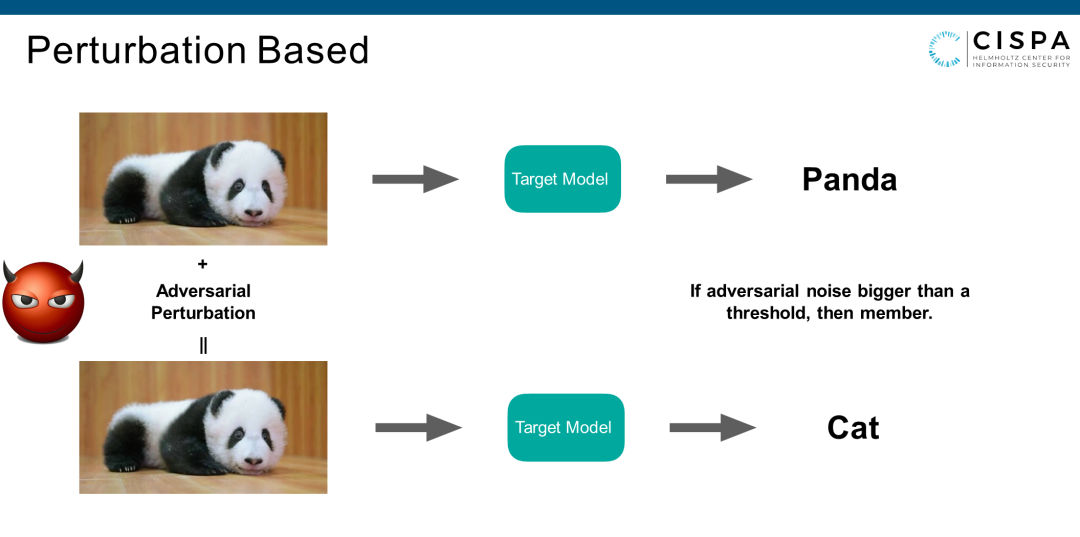
大家做这个领域,一定听过一个叫做对抗样本的攻击。对抗样本和成员推理攻击,是两个完全不同的技术。对抗样本更接近于对Model的攻击,成员推理攻击是隐私方面的攻击。但对抗样本是一个很常见的东西,就是对一个正常的、黑盒的Target Model,有一个图片放到Target Model里去,它告诉我这个是熊猫。对抗样本攻击会找一个方法自动产生一些噪音。这些噪音加到原图片,人眼看不出区别(下面这张图片是加了噪音的图片),但如果把这个加了噪音的图片放到Target Model里去,它会告诉你这不是一只熊猫,而是一只猫。
所以,对抗样本攻击和成员推理攻击是不相关的攻击。但对抗样本攻击理论上可以找到信号来判断这个sample是不是member。我们可以通过对两个图片(一个是member,一个non-member)加噪音,会发现对member加的噪音要大,对non-member加噪音小。你可以通过这个噪音的大小来判断一个sample是不是member还是non-member。这个就是通过Label-only的方式来做成员推理攻击。

除此之外,我的实验室也做了很多关于成员推理攻击的文章。因为成员推理攻击是现在机器学习隐私风险方面的主流攻击,甚至可能是最火的攻击或者是唯一攻击。别的一些攻击并不被主流认可,或者并没有那么popular,成员推理攻击反而是很重要的一个攻击。
我们在Label-only上、在推荐系统上做过成员推理攻击,发现效果都非常好。甚至在如自监督学习、图神经网络、神经网络架构搜索等方面也做得比较好。包括对于想让GPU省资源,让AI更加绿色的Multi-exit Networks上,我们都做了成员推理攻击。总体来说,成员推理攻击在这些Model上都可以成功,而且表现都不错。唯一可能成功率不太高的就是自监督学习。现在更高级模式的ML Model,他把sample的representation学得越来越好,造成的攻击表现可能没有那么好。
Data Reconstruction
(In Online Learning)
第二部分是数据重构攻击,这里是指在线学习的数据重构攻击。我刚刚说的数据是推动机器学习发展的一个很重要的因素。而数据的产生是一个动态过程,每时每刻每分每秒都有数据在产生。这就意味着再强大的公司训练了一个机器学习模型,而过了三个小时、三天或者三个礼拜后,数据、Model都已经过时了。因为过去时间产生的新数据,Model没有见过,它就可能判断不准。

去解决这个方案,我们需要用到在线学习方法。即我们在Model训练好、新的数据进来以后,把新数据在原来Model的基础上去微调一下,这个Model就有了新数据的支持了。这是一个很基本的一个online learning的过程。我们在想,这个过程会不会反而构成一个可以被攻击的一个平面。假设我有个Target Model,我用一张图片去query Target Model,会产生output。然后晚上这个Target Model的拥有者用一些新数据更新了Model。明天早晨我用同样的图片去query这个已经更新过的Model,会得到一个不同的output,因为Model更新了。这个很像智能手机应用商店里软件的update。
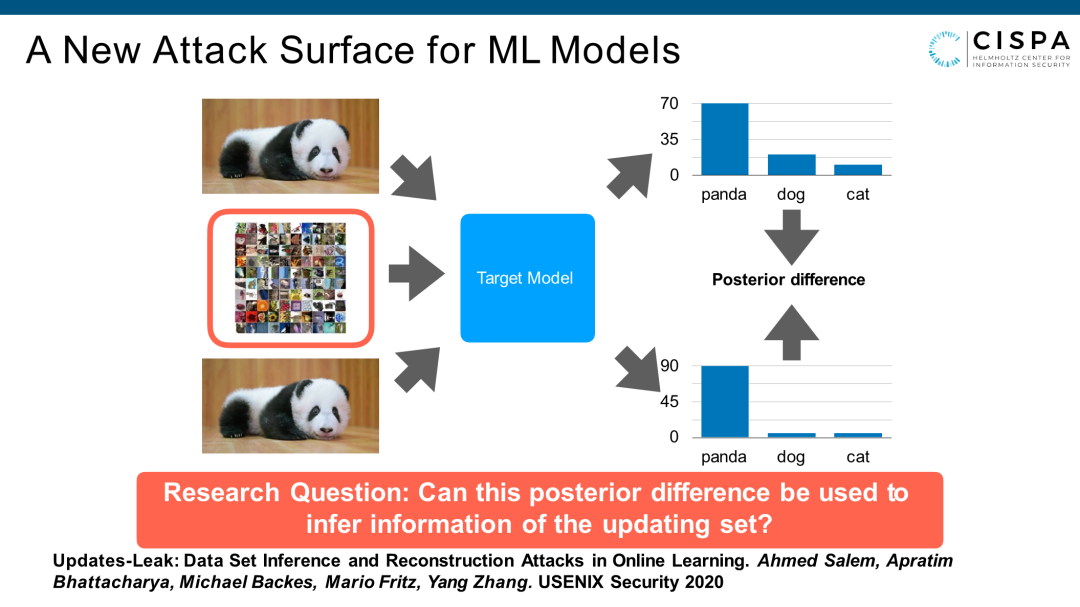
这种情况下,同一张图片在一个模型的两个不同版本会产生不同的output,这完全是因为更新数据造成的。我们就想,这会不会构成一个Attack Surface?我们可不可以利用一个同样的图片,同样的sample数据在不同版本Model output的不同,去推测它用了什么数据去update这个Model。这个是我们要研究的问题,这个是我们2020年在USENIX发的文章。
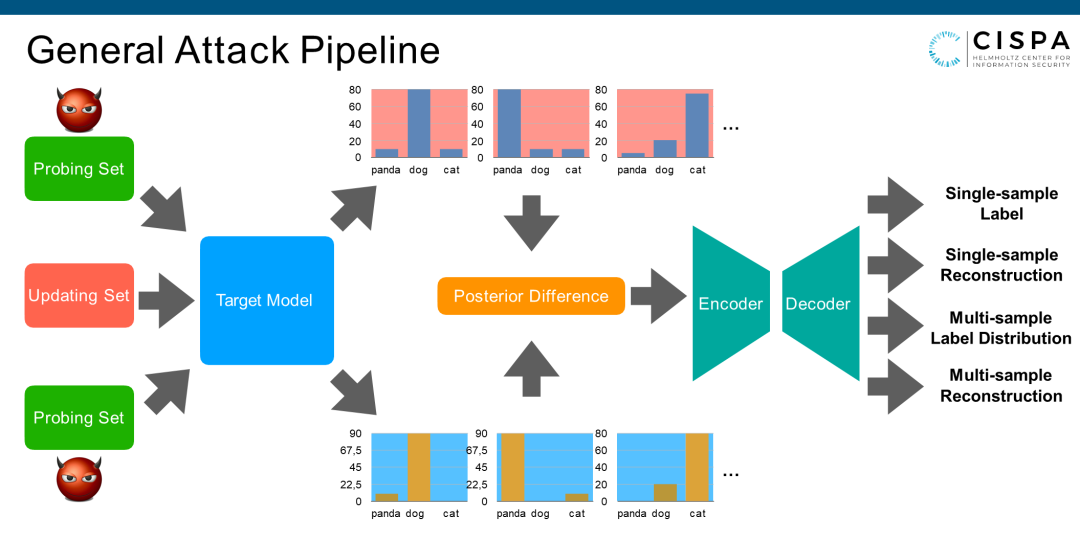
我们做了一个general的Attack Pipeline,就是我有一个Target Model,然后找一个 Probing Set去探测这个Model。探测集有100张图片或1000张图片,探测以后会产生1000个output。我们假设有100张图片update了这个Model。然后我从Attacker的角度,再用同样的Probing Set再去探测Target Model的第二个版本,每个output都不同,因为Model更新过了。我们把Posterior Difference放到一个Encoder去,我们做了四个不同的Encoder(解码器),对应着4种不同的攻击。今天的时间有限,我只能讲最后一个攻击,可能也最难的一个攻击,即Multi-sample Reconstruction。我们通过把这个Posterior Difference放到编码器,再转换成解码器,能不能把原来所有的Updating Set里的sample给重构出来。

我们的核心思路和别的数据重构不太一样。别的数据重构可能基于数学公式来做这个问题。而我们的思路是先学出这个Updating Set的分布。有了分布以后,我就可以不停地从分布抽取图片出来。有了图片以后,再做一些简单的后期处理,比如聚类,我就会得到这个重构的数据集。
如果要学出一个分布,你脑中想到第一个模型想必是对抗生成网络(GAN),GAN就是一个学分布的模型。我们解决这个问题的方案,就是我们在原有GAN的基础上提出了一个新的GAN,就相当于在上面加了一个新的Loss Function,然后我们就有能力去学出这个Target Model Update Set的分布。有了分布,我们再做后期处理。
我给大家快速回顾一下GAN,GAN本身有两个神经网络构成,一个叫生成器、一个叫判别器。生成器的input是128维的高斯噪音。这高斯噪音输入进去以后,Generator会把这个噪音转换成一张图片。判别器是一个二分类器,这个二分类器的工作是判断这是真图片,还是这个生成器生成的图片。判别器的目的就是我让所有任何generator生成图片都被准确地找出来,都能准确的和真实图片分割出来。而生成器的目的是我生成的图片越像真的越好,让判别器看不出来。所以这两个机器学习模型,本身是一个对抗的过程。这就是被叫做对抗生成网络的原因,他们的目标是相悖的。他们两个同时训练,互相训练,最后会达到一个convergence。训练完以后,generator就是一个很好的生成假图片的工具。
现在大家所说的Deepfake(深度伪造),大部分是通过GAN产生的。而这个generator本身学了很好的分布性质,实际上就是学出真正的训练数据集的分布,这是普通的GAN。
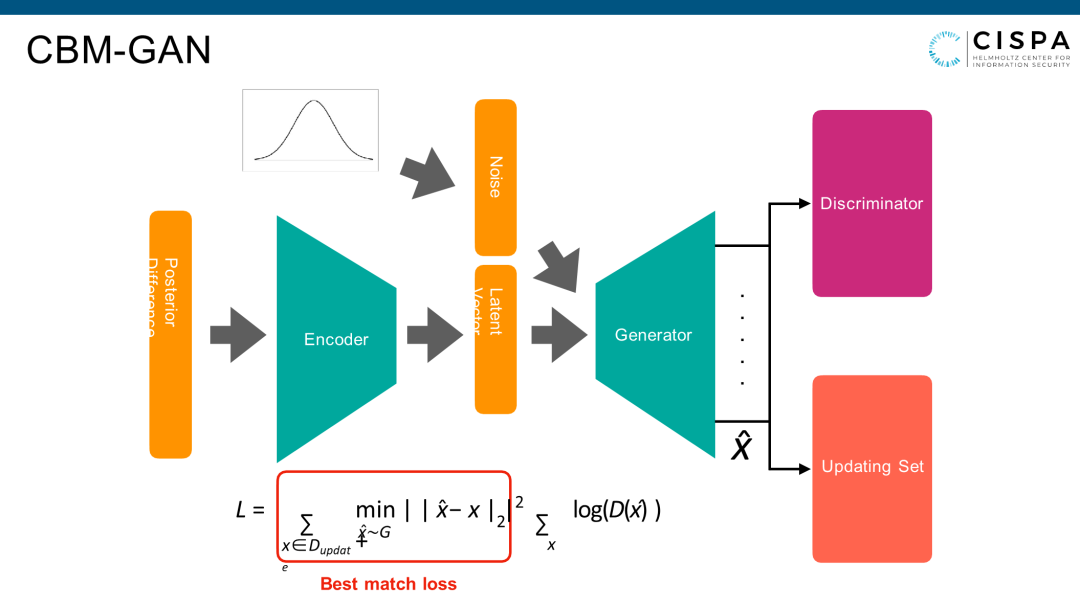
我们的CBM-GAN是把Probing Set在Target Model上两个版本的Posterior Difference放到Encoder去,也把它变成128维做成Latent-vector,加上原来GAN的Latent-vector 128维,合起来256维一起作为generate的input,相当于Model两个update版本的Posterior Difference和generator已经产生了联系。然后我们在generate的loss基础上加了一个新loss。如果不看红框里边的lost,只看外边,这就是一个普通的generator的loss。D这里代表discrimination。我们加了一个新loss,这个loss叫Best match loss。我本地有一个Shadow Update Set,我要保证generator对Shadow Update Set里每一个sample都可以学出一个和它最像的。比如说100张图片的,我要保证我的generator有能力把Shadow Update Set的每一个图片都给尽可能地还原出来,这个是我的loss。

我们看一下实验结果,有200张图片,假设这些数据是被MNIST这个经典数据集去update其中100张图片。用黄框标出来都是重构的,没有被标出来是原来的。你会发现我们学出的效果相当不错,而且这大约是两三年以前的工作。当时,GAN远没有现在强大,如果用现在更高级GAN,表现应该会更好。这就证明了我们从分布到重构数据的思路应该也可以去解决重构数据集,这一个比较难的问题。
Link Stealing Against GNN
我演讲的第三部分就是链路窃取攻击。
图神经网络是过去四五年机器学习领域新兴起的一个领域,也是一个非常火的领域,尤其在工业界很常用。图神经网络和传统的神经网络(左图)不一样。传统神经网络,是假设每一个训练sample都是独立的。但图神经网络(GNN)的input是整个graph data。
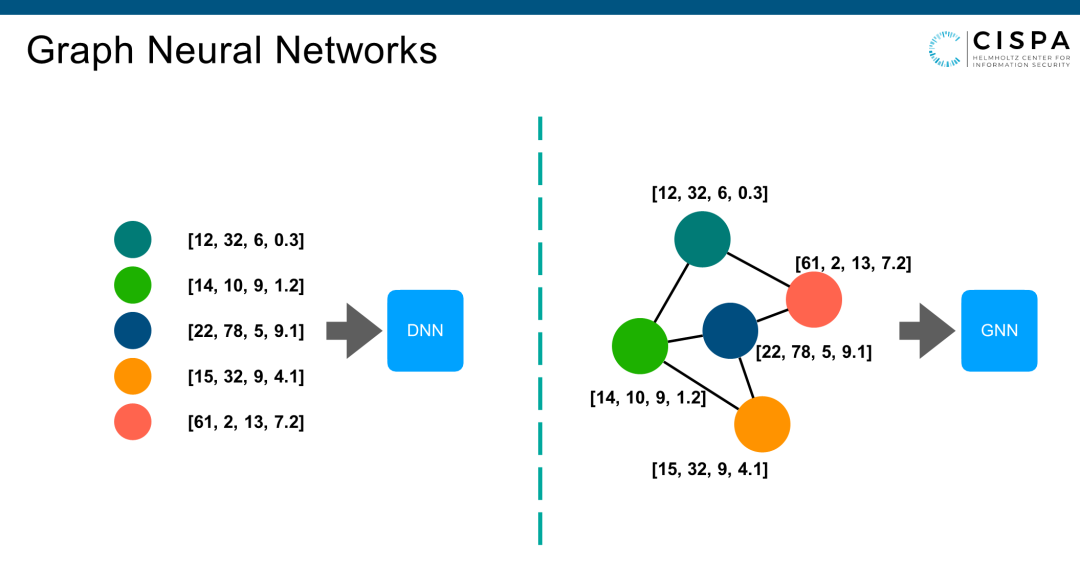
每个点可以是张图片也可以是社交网络里的人,每个点都有一个自己的feature vector。它除了把每个点的feature vector考虑到Model的训练过程中以外,还把点与点之间的联系也考虑进去。比如工业界很常用的场景是社交网络、金融交易网络、交通网络等。因为好多工业界的数据可以自然而然组织成一张图。

最早、最经典的GNN,也许可能在工业界应用很多的Transductive Setting,就是左边这个数据集有五个点,每个点的feature vector我都知道,唯一我不知道的是这个蓝色点和红色点的label是熊猫、猫、还是狗。所谓的Transductive Setting就是说我的训练过程中把整个图全部放进去了。因为我知道图之间的关系,也知道每个点的feature,我只是不知道那两个点的label。我把这个全图信息放进去训练一个Model,训练完以后,我的目标还是想知道这个蓝色点和红色点的label是什么。那我query这个Model的时候,我只需要把这个蓝色点或者红色点的ID给这个Model就可以。给一个蓝色的ID,不用给feature(因为feature在训练的过程中见过),GNN可以写一个很简单的查表语句,就可以知道这个蓝色点指的是哪个点,它会给一个output。如果给一个红色点,我就知道另一个output,这个是Transductive Setting的GNN。我们这里研究的问题是在Transductive GNN上有没有隐私泄露风险。因为GNN之所以比别的Model强大,是因为GNN用了图的信息。那么通过GNN去query它的过程,能不能泄露图的信息。
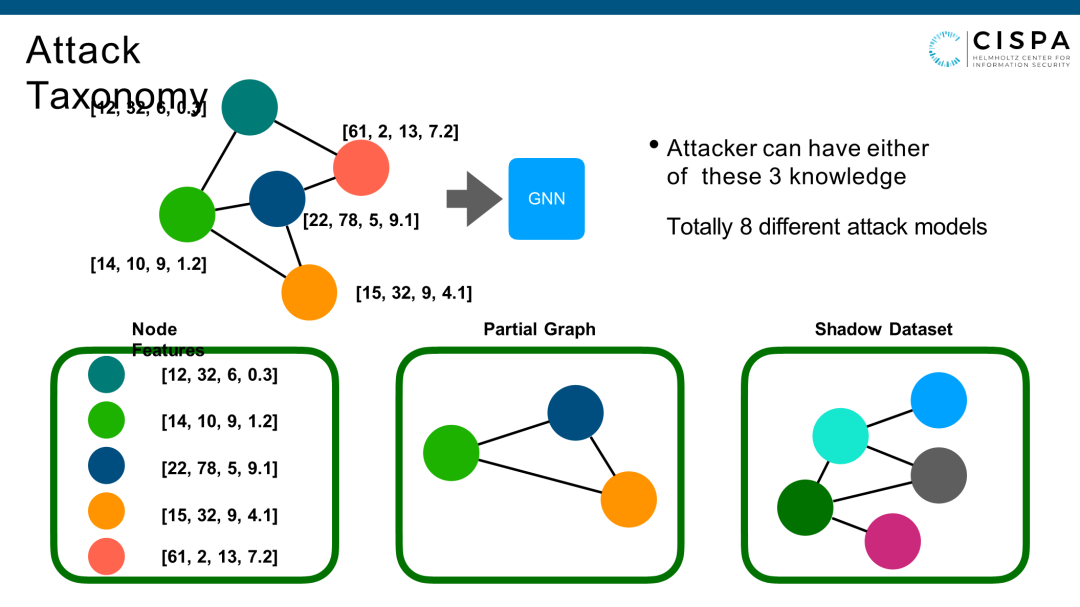
这是我们在USENIX2021的文章,也是这个领域第一篇文章。我把攻击考虑得完整一点,包括Node Feature、Partial Graph、Shadow Dataset,每一个信息可以有也可以没有。但不同情况下,组合起来就有8种不同的攻击。
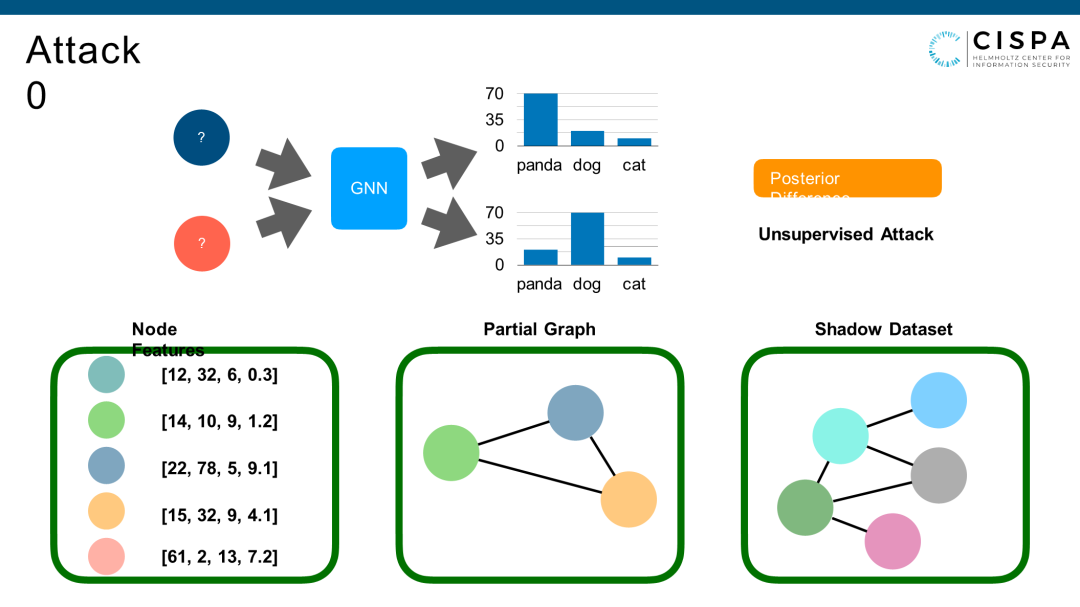
时间关系,我介绍两种最简单的Attack。第一种Attack是最弱的,Node Feature、Partial Graph、Shadow Dataset这些信息都没有。它只能做的是有一个点探测Model产生Posterior、另一个点也探测Model产生Posterior。通过2个Posterior判断这两个点是不是链在一起的,这就是链路窃取攻击。实际上这个Attack也很简单,我们假设这两个点之间在原图里边有一条边,那么它们的Posterior应该更相近,反之亦然。原因是社交网络里很常见的SocialHomophily,两个点在很多相似的Feature环境下更容易被链接在一起。所以我们把两个点产生的Posterior Difference算出一个值。如果相似度很高,那么这两个点之间就有一条边连着,否则它两个点之间就没有一条边连着。
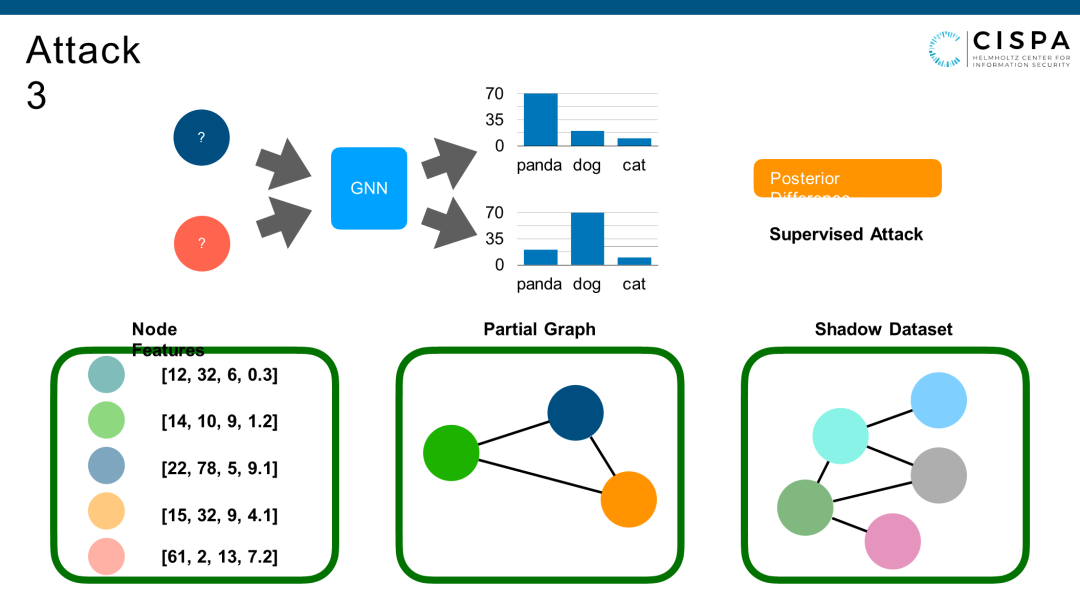
Attack3是内容攻击,我知道原图里一些存在的边,但是并不包括这蓝红两点的边。那Attack3和原来的Attack0是非常相似的。唯一的区别是我现在有一些ground truth label可以给我做训练了,就是我可以用与Attack0一样的Feature,Attack Model可以训练一个分类器来做攻击,两个点之间有没有连接。
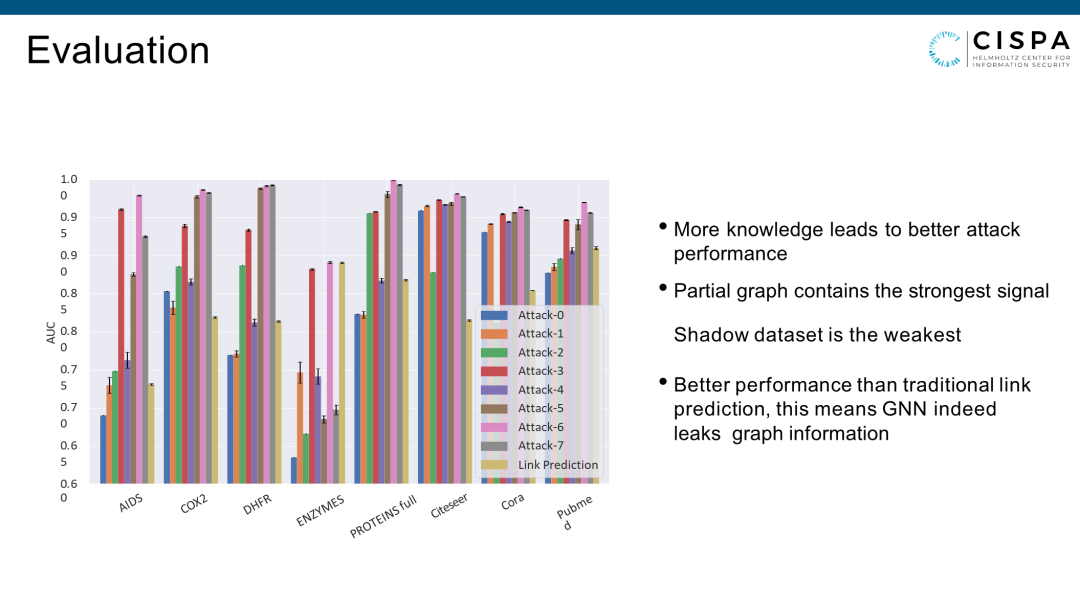
我们做了8种不同的攻击,Attack7知道的信息是最多的,Attack0知道得最少。Attack知道的信息越多越好。这三种不同的信息里,知道原图的部分边是最强的信息,而有一个不同分布的Shadow Dataset是最没有用的信息,对攻击加成不大。更重要一点是我们GNN链路窃取攻击的表现,比传统的Link Prediction(纯通过图的结构来判断这两个点之间一条边)表现都要好,就证明GNN确实能记住图的边的信息。也说明GNN也确实可以泄露这种边的信息。虽然说工业界很强大的应用,但是Model Deploy的时候要小心,因为原来的边很容易被Attacker窃取。

最后分享的是我们组今年刚做的一个工具ML-doctor,很快就会在USENIX2022发表。它集合了几种不同攻击,包括成员推理攻击、数据提取攻击、模型逆向攻击、模型窃取攻击。我们第一次把这四个攻击放在一起考虑,做成了一个包。我们分析了这四个攻击方式之间的关系,发现了一些有意思的现象,并已经把相关code放上了GitHub。欢迎大家下载使用我们的工具,以后在做这方面研究时可以节省很多时间。

总结一下,我分享了成员推理攻击,数据重构攻击,链路窃取攻击。感谢所有的合作者(以上list不是完整的,有些还未更新),感谢他们对我的帮助,如果没有他们的贡献,我以上分享的工作都是不可能实现的。今天的分享到此为止,谢谢各位,期待有机会和大家相见。
声明:本文来自ATEC,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
