“谁访问了你的数据?” 这看似一个简单的问题,却很难回答:
首先,你以为数据库日志记录了身份,但数据库日志常常是被禁用的;
然后,你以为应用程序日志记录了身份,但其实没有;
于是,你以为强行启用数据库日志就可以解决问题,但并没有;
接着,你以为应用程序可以把身份带给数据,但其实不行;
终于,你以为这样就没辙了,但聊暗花明又一村……
上述问题本质上是数据访问的身份归因。
我们知道,对于应用程序的访问而言,身份归因是比较容易的,通常由单点登录(SSO)即可解决;那对于数据的访问,身份归因为何就如此困难呢?
区别就在于:“谁访问了你的应用”并不等同于“谁访问了你的数据”。在应用程序和数据之间,存在一条难以逾越的大河。
所以,将零信任思想应用于数据访问时,听起来很简单;但将零信任技术应用于数据访问时,做起来却很困难。
当然,对于正确的事情,即使困难,也该做。
再问一遍:在贵组织的数据访问过程中,真地有用户身份吗?
关键词:SSO(单点登录);DSP(数据安全平台);身份提供者(IdP);
目 录
1.问题:谁访问了你的数据?
2.你以为数据库日志是默认启用的
3.你以为应用程序日志可以办到
4.你以为强行启用数据库日志就好
5.既然无解,请向前辈(应用程序)学习
6.然而,数据并没有SSO(单点登录)
7.既然没有数据SSO,那就创造一个
8.答案:具备数据SSO的数据访问平台
01 问题:谁访问了你的数据?
谁访问了你的数据?很容易提问,但很难回答。
当我们在被审计过程中试图证明我们过去的访问行为是正当的时,我们可能会被问到这个问题;当我们处理数据泄露问题时,我们可能会被问到这个问题。
在大多数情况下,我们都以非常被动的方式回答这些数据。因为我们看不清也说不清这个问题。
当被问及这个问题时,你可能会觉得自己被置于聚光灯下,甚至是审讯椅上。
02 你以为数据库日志是默认启用的
遇到这个问题,我们通常的想法是查看数据库日志,看看是否可以找到答案。但通常没有数据库日志,因为数据库日志经常被禁用。
为什么我们经常会关闭数据库日志呢?
一是延迟。通常,应用程序中的最慢部分就是数据访问,即连接到数据库并检索数据。而数据库检索数据的最慢部分是从磁盘读取数据。当我们写入日志时,我们需要执行两个磁盘操作,从而增加了应用程序的延迟。因此,出于性能原因,我们可能会选择禁用日志记录。
二是存储。我们也可能出于存储原因选择禁用日志。数据库服务器的工作是存储关键业务数据。随着时间的推移,我们可能会存储大量数据,导致我们很久以前选择的磁盘大小现在可能不够了。我们只好先删除一些不需要的东西,首先想到的自然是删除数据库日志。
另一方面,即便数据库日志存在,它们可能太贫乏而无法获得有价值的见解。对此,后文再做解释。
03 你以为应用程序日志可以办到
接下来,我们考虑应用程序日志。
任何使用我们数据库的东西,都可能来自我们的应用程序。值得庆幸地是,我们对应用程序的使用过程有很好的日志记录。我们可能有非常漂亮的仪表板,向我们展示经过身份验证的用户活动、页面请求、响应HTTP状态代码,以及完成请求所花费的时间。于是,我们希望通过这些日志来回答“谁访问了我们的数据?”这个问题。
但是应用程序日志是否足以回答这个问题?不幸的是,并非如此。因为还存在许多不通过应用程序连接到数据库的场景:
SRE(站点可靠性工程师,Site Reliability Engineer):会跳转到客户帐户,以快速修复一些数据错误并让客户恢复正常。
DBA(数据库管理员):直接登录数据库,以调整索引或重写慢查询。
部署工具:运行数据库迁移,以部署软件的新版本。
批量数据提取工具:可以帮助新客户加入或帮助老客户离开。
这些连接是否通过应用程序?他们可能不是。他们可能通过数据库管理工具直接访问数据库。
还可以列举多种合法的场景,其中正常的数据访问都不是通过我们的应用程序完成的;而对于其它不合法的活动,当然很可能也不是通过应用程序来完成的。
使用应用程序日志来回答有关数据库访问的问题,仍是一个谎言。因为数据访问不仅仅通过应用程序发生。
04 你以为强行启用数据库日志就好
既然没辙,就让我们启用数据库日志吧。
如果我们查看Postgres官方文档,就会发现:默认情况下日志是禁用的——正如前文所述。
当然,我们可以启用日志,即通过如下配置,将日志级别从无更改为全部:
postgres -clog_statement=all -clogging_collector=on
启用日志后,再重启数据库。然后,使用应用程序和终端工具访问数据库。这时,我们可以看到类似下面的日志信息:
2021-02-21 15:35:07 CET [3492-349] postgres@prod LOG: execute
2021-02-21 15:35:07 CET [3492-350] postgres@prod LOG: duration: 11.069 ms
2021-02-21 15:35:08 CET [3494-223] postgres@prod LOG: duration: 0.030 ms
2021-02-21 15:35:08 CET [3494-224] postgres@prod LOG: duration: 0.081 ms
我们的确可以看到执行的查询操作、查询的日期/时间、消耗的时间,但看不到查询是由谁执行的。即便我们想记录用户信息,我们可能只会看到应用程序使用的服务帐户。
而即便是由非应用程序型工具所运行的查询,也可能仍然使用相同的服务帐户。我敢打赌,DBA或SRE用户只是打开了Web应用程序,又从配置文件中提取了凭据,然后登录。
为何会执着地使用服务帐户?因为在数据库中创建个人用户,并使其在员工加入和离开时保持同步,真是太困难了——所以没法这么做。于是,大家都使用相同的服务帐户。
关于日志的小结和回顾。出于性能原因,可能会关闭数据库日志,以避免额外的磁盘访问延迟或节省宝贵的存储资源。即使我们打开了日志,所有访问都使用单个服务帐户——不论是来自我们的微服务的访问,还是来自非应用程序型工具的访问(如DBA、SRE、DevOps工具)。总之,数据库日志不包含用户身份信息,所以无法帮助我们回答“谁访问了数据?” 这个问题。
05 既然无解,请向前辈(应用程序)学习
或许,你以为没辙了。但还可以向前辈(应用程序)学习。
我们知道,Web应该程序使用单点登录 (SSO) ,完美地解决了身份问题。我们来看看,它是如何做到的。
SSO的工作流需要用户、应用程序、身份提供者 (IdP) 这三方的共同努力:
用户启动Web应用程序
用户点击登录
浏览器重定向到身份提供者 (IdP) 登录页面
用户登录到这个受信任的资源
浏览器重定向回应用程序
用户完成工作
可见,应用程序、身份提供者、用户共同构建了很好的体验:
身份提供者:将用户凭据安全地存储在一处。身份提供者提供丰富的用户上下文,包括经过验证的身份和组成员资格。
应用程序:接受此令牌,并可以根据用户的组成员资格或其他声明对用户做出授权决定,但Web服务不需要存储凭据或验证用户的电子邮件。
用户:如果已经登录到共享的SSO身份提供程序,他们可能会直接被重定向回网站,而无需再次登录。这是一种很棒的用户体验。
当我们审视SSO内部的这种机制时,我们看到了一个优雅的机制,即应用程序、身份提供者、用户三者一起工作,来创建这个优雅的解决方案。如果我们查看微服务的日志,我们可以看到用户的身份、组成员资格、请求URL、响应状态代码、请求持续时间、日期/时间、连接的细节(如源IP等)。
既然SSO已经解决了应用程序的问题,我们是否可以用SSO解决数据库的问题呢?
06 然而,数据并没有SSO(单点登录)
对于应用程序而言,单点登录 (SSO) 是应用程序的绝佳解决方案,可以获取请求和响应的细节、连接的细节、身份上下文。
那为什么我们不能对数据这么做呢?
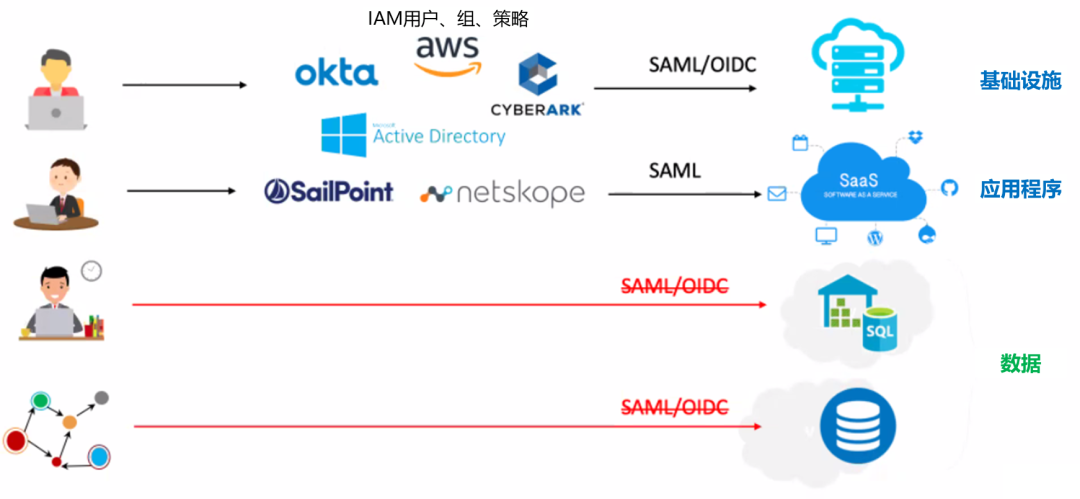
图1-数据没有SSO(单点登录)
如上图所示:
面对Web应用程序:我们可以轻松地转发给身份提供者 (IdP)。借助云资源,我们可以使用OIDC或SAML进行身份验证。
面对本地和云中的数据资源:我们却一下子回到了石器时代,因为许多流行的数据库并不支持SAML/OIDC协议。尽管Snowflake或Redshift这样的现代数据库的确可以通过Okta或IAM支持原生SSO,但大多数业务用户使用BI工具(如Looker、Tableau、Thoughtspot等)通过单个服务帐户来访问数据,所以仍然看不清这些工具背后的真实用户。
简言之,应用程序有SSO,但数据没有SSO。
07 既然没有数据SSO,那就创造一个
让我们从应用程序的SSO解决方案中学习,并设计能够为数据提供身份上下文的日志记录解决方案。
我们先列举我们理想中的日志记录解决方案:
SSO用户名
SSO组
SQL查询
结果行数
客户端连接的细节
日期和时间
这正是我们想要的信息:SQL查询、响应的细节、日期和时间、连接的细节、用户身份。
这也正是我们通过启用SSO的应用程序所能获得的数据。我们得到经过身份验证的用户和组、请求URL、响应状态代码、返回的字节数、用户的源IP、查询的日期和时间。
如果我们的数据日志中有这些细节,我们就可以明确而自信地回答问题——谁访问了我们的数据?
那么,我们该如何获得数据存储的这种详细程度?让我们采用数据访问平台,或者称为数据安全平台(DSP)。
08 答案:具备数据SSO的数据访问平台
我们的方案是一个数据安全平台(DSP),它必须是一个身份联合访问控制系统,也必须能够将SSO带入数据网格。
由于数据访问需要区分应用程序访问场景和非应用程序访问场景,故需区分两种场景,分别进行应对。
1)应用程序场景的数据SSO
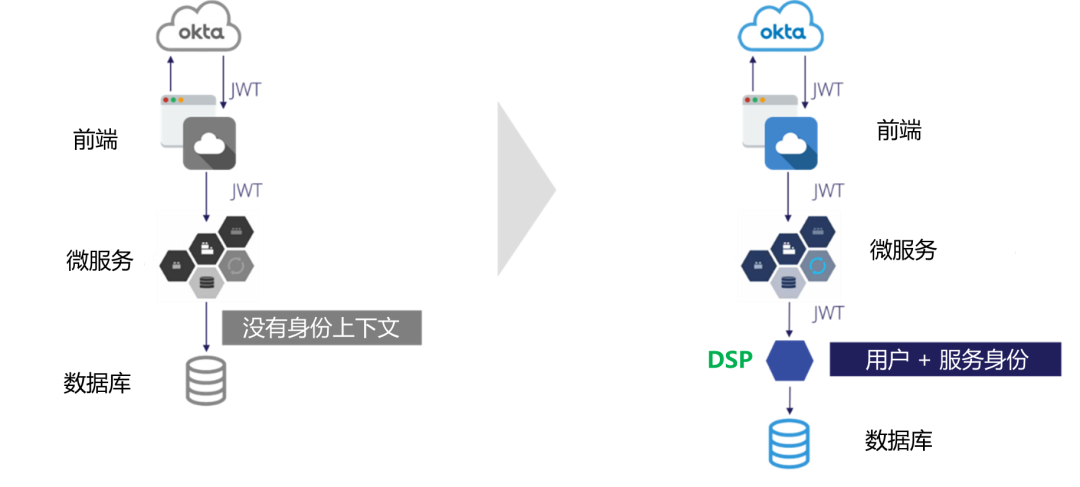
图2-传统方案 vs. 数据SSO方案
在上图中,左侧是DSP之前的场景;在右侧,我们添加了DSP来支持身份上下文日志记录。
在左侧(传统方案):前端向SSO提供者进行身份验证,并检索包含所有 SSO 组和其他声明的 JWT(JSON Web Token)。应用程序可以在微服务之间传递此身份验证令牌,以验证用户的身份并做出授权决策。但是,一旦微服务接触到数据,它就会切换到共享服务帐户,于是身份上下文就丢失了。
在右侧(数据SSO方案):增加了DSP(数据安全平台)来支持身份上下文日志记录。我们使用相同的SSO身份验证机制,检索相同的JWT,并通过微服务传递此身份验证令牌。然后,我们要做一些新颖的事情:我们还将这个身份验证令牌传递给DSP的Sidecar(边车)代理。DSP捕获查询请求和响应的细节,以及用户身份的细节。DSP将该查询操作,代理到数据存储,并将结果返回给应用程序。也就是说,通过使用DSP,我们可以通过数据层保留用户身份。
2)非应用程序型场景的数据SSO
注意到,许多数据访问场景并不经过应用程序:SRE、DBA和其他人可以直接连接到数据存储。所以,现在让我们来看看通过终端(terminal)或其他专用连接的数据访问。
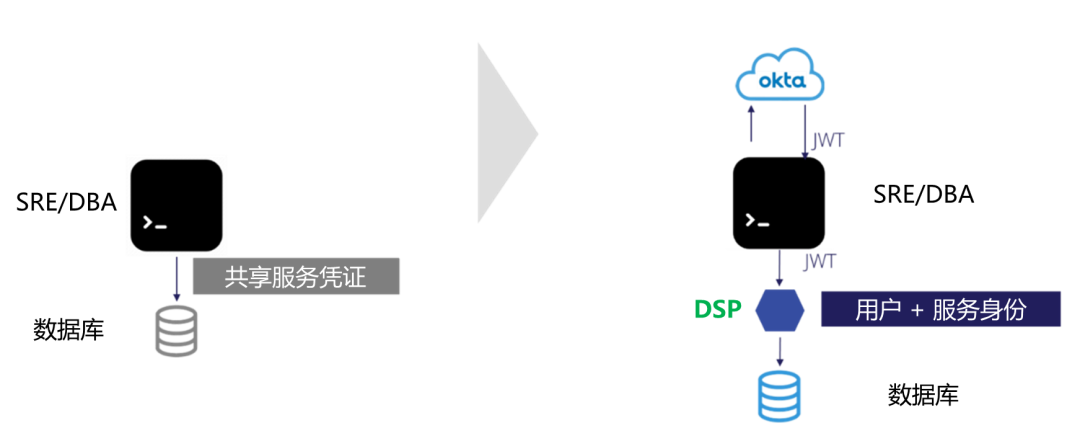
图3-传统方案 vs. 数据SSO方案
在左侧(传统方案):用户直接连接到数据库。他们很可能使用共享服务帐户,从而导致用户身份丢失。
在右侧(数据SSO方案):用户通过DSP门户,登录到他们选择的SSO提供商。从那里,他们获得了一个令牌,用于向DSP的Sidecar验证他们的身份。所以,DSP可以捕获查询请求和响应的细节以及用户身份。然后,DSP将该查询操作,代理到数据存储。
3)结论:具有数据SSO的DSP
对于应用程序和非应用程序的数据访问,DSP都可以在数据访问过程中捕获用户身份。也正是在DSP日志中,我们找到了我们正在寻找的东西:用户身份!
借助DSP,我们可以使用各种身份联合访问控制,如Okta Azure Active Directory、G-Suite等;也可以连接到各种数据存储,如MariaDB、MongoDB、SQL Server等;还可以将日志发送到您选择的SIEM平台,如ELK、Splunk、DataDog等。
有了DSP的Sidecar代理,我们就可以使用标准SSO工具,向我们的数据库进行身份验证。应用程序用户和非应用程序用户(如SRE、DBA、部署工具)都可以通过SSO进行身份验证。DSP收集的日志包括查询请求、响应行数、所用时间、连接的细节(如客户端IP等),以及最重要的SSO用户和组。
谁访问了我们的数据?有了具备数据SSO能力的DSP,我们就能知道。(一帆 & 柯学)
本文的封面来自于下面这本书:

声明:本文来自网络安全观,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
