一、简介
随着计算机计算能力的提高和大量数据集的公开,机器学习算法在许多不同领域取得了重大突破。这一发展影响了计算机安全,催生了一系列基于学习的安全系统,例如恶意软件检测、漏洞发现和二进制代码分析等。尽管机器学习算法潜力巨大,但其在安全领域中的使用却很微妙,容易出现缺陷,这些缺陷会破坏算法的性能,并使基于学习的系统可能不适合具体的安全任务和工具的实际部署。这也导致了大量安全人士看衰机器学习在安全领域的发展前景。
实际上,机器学习只是一个工具,工具的使用方式一定程度上决定了工具的效果。机器学习无疑是一个强大的工具,那么如何在安全场景中正确使用该工具呢?本文介绍一篇安全4大顶会之一USENIX SECURITY 2022的最佳论文奖论文,该文提出机器学习在安全场景下的10大使用误区,并且提出了可行的建议。
二、论文介绍
文章总结了10个常见的机器学习使用误区,并且分析了过去十年中依赖机器学习解决安全问题的 30 篇顶级安全论文,结果表明,这些误区在研究工作中普遍存在,并且每篇论文都至少存在三个,更进一步,文章分析了这些误区对模型造成的影响,以恶意软件检测为例,分类器因采样偏差有10%以上的性能下滑。
2.1 十大误区及缓解建议

图1 安全领域中机器学习使用的常见误区
如图1所示,文章将这10个误区划分到机器学习流程中的不同阶段。
2.1.1
数据收集与标记阶段
误区1 – 采样偏差。收集的数据不足以代表层安全问题的真实数据分布。
建议: 需要对样本的真实分布做评估,可以使用合成数据来扩展数据集或者使用迁移学习的方法,但是应该避免将不兼容来源的数据混合使用。
误区2 – 标签缺失。分类任务所需的真实标签不准确、不稳定或错误,影响机器学习系统的整体性能。
建议: 1. 应尽可能验证标签,如:手动调查误报或随机抽样。2. 如果不能排除噪声标签,则可以通过以下方式减少它们对模型的影响:(i)使用健壮的模型或损失函数,(ii)在学习过程中对标签噪声进行建模,(iii)在训练数据中清除噪声(不能删除测试集中的噪声)。此外,由于标签可能会随着时间而改变,需要采取预防措施防止标签漂移,如:延迟标记数据。
2.1.2
系统设计与学习阶段
误区3 – 数据窥探。使用通常在实践中不可用的数据来训练机器学习模型。数据窥探可以通过多种方式发生,其中一些方式非常微妙且难以识别。
详细表述。在机器学习流程中,将数据集切分训练集和测试集是一种常见的做法。切分数据集看起来简单,但测试数据已经以及一些不可用的背景信息会以微妙的方式影响训练过程,文章将数据窥探分为3类:测试窥探、时间窥探和选择窥探。测试窥探指将测试集提前使用,如:用于识别有用的特征、参数、模型等;时间窥探指忽略数据的时间属性,如:用将来的数据训练,用历史数据测试;选择窥探指基于不可用的信息做数据清洗,如:基于整个数据集(训练集和测试集)的统计数据去除异常值,而这些统计值在训练阶段是不可见的。
建议:测试集在最终评估前避免使用,拆分数据集时考虑时间依赖性。
误区4 – 虚假相关。与安全问题无关的特征能够完成分类任务,导致模型去拟合这些特征而不是去解决实际问题。
举例:在网络入侵检测场景中,数据集中绝大多数攻击流量来自于一个特定网段,导致模型不学习攻击模型,而是学习特定IP段来检测攻击,导致了IP段与网络入侵的虚假相关。
建议:将可解释性应用于机器学习模型,专家评估解释结果的有效性。
误区5 – 有偏的参数选择。基于学习的方法的最终参数在训练时并不完全固定,间接依赖于测试集。
举例。在测试集上调整模型的超参或阈值,取得更好的效果。如在二分类任务中,在训练数据中阈值设为0.5,在测试集中发现0.6的效果要高于0.5,则将0.6设为测试集上的阈值。
建议:严格的数据隔离。
2.1.3
效果评估阶段
误区6 – 不恰当的基线。在没有或有限的基线方法的情况下进行评估,不能证明对现有技术和其他安全机制的改进。
建议:不要仅仅对比复杂方法,找一些经典的、简单方法做比较;利用AutoML技术找到合适的基线。
误区7 – 不恰当的评估指标。选择的性能指标没有考虑应用场景的限制,例如数据不平衡或需要保持低误报率。
建议:机器学习中评估指标的选择与场景强相关,这些评估指标往往不是那些标准的指标,如:准确率,应该根据实际场景选择合适的指标。
误区8:比例错误。没有考虑样本不均衡的现象导致评估效果过高。
举例。模型的误报率只有1%,但是如果正负样本的比例是1:100的话,那么结果中TP:FP=99:100
建议。对于攻击检测,建议使用精确率和召回率的相关指标,但是如果低比例样本的估计数据偏高,就应该使用马修斯相关系数 (MCC)等相关指标来评估分类器效果。
2.1.4
部署和运营阶段
误区9 – 仅实验室评估。基于机器学习的系统仅在实验室环境中进行评估,而不讨论其实际使用中的局限性
建议。在尽可能真实的环境下进行评估。如:考虑数据的时间、空间特性,考虑实际场景下的运行时间和存储限制,理想情况下,应该部署于真实环境以发现实验室环境中发现不了的问题。
误区10 – 不恰当的威胁模型。不考虑机器学习的安全性,使系统暴露于各种攻击,例如中毒和绕过攻击。
建议。假想一个对手,对机器学习系统进行攻击;尽可能的关注白盒攻击,遵循Kerckhoff原则和最佳实践。
2.2 普遍性分析
文章在选择了在安全4大顶会(ACM CCS, IEEE S&P, USENIX Security, and NDSS)中近10年发表的应用机器学习方法解决安全问题的30篇论文,涵盖领域众多,包含:恶意软件检测(6篇),网络入侵检测(4篇),漏洞挖掘(4篇),网站指纹攻击(4篇),社交网络滥用(3篇),二进制代码分析(3篇),代码归因(2篇),密码学(1篇),网络诈骗(1篇),游戏人机检测(1篇),广告拦截(1篇)。
对于每一类误区,评判标准分为7类:呈现、部分呈现、没有应用、不清楚、呈现但是有讨论,部分呈现且有讨论,未呈现。严重程度依次由高到低。
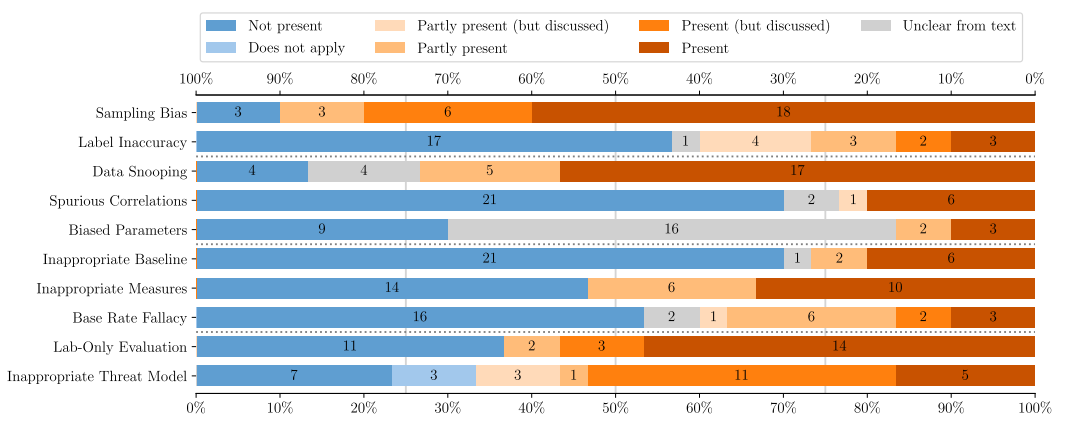
图2 常见误区在30篇文章中的分布情况。颜色的深浅表示误区在文章中的呈现程度
如图2所示,流行度分析的汇总结果表明,最普遍的误区是抽样偏差(误区1)和数据窥探(误区3),出现概率分别为 90% 和 73% ,每篇论文都受到至少三个误区的影响,这也表明了这些问题在最近的安全研究中的普遍性,特别是,数据集收集仍然非常具有挑战性。
2.3 影响性分析
文章分别在:恶意软件检测、作者归因、漏洞挖掘、网络入侵检测4个领域分析了这些误区对实验结果的影响,我们以恶意软件检测为例加以说明。
如图3所示,D1数据集收集了谷歌和中国软件市场的软件,D2数据集仅收集了谷歌软件市场中的软件,DREBIN 和OPSEQS为两种最近的恶意软件分类方法,可以看到因为采样偏差(误区1),在D2数据集上,两个分类器均有一定程度的性能下滑。
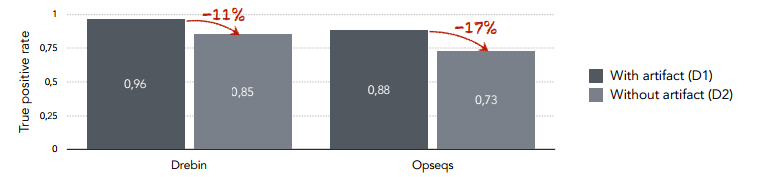
图3 数据偏差(误区1)对恶意软件分类的影响
三、总结
机器学习在网络安全中得到了广泛应用,但是其表现往往不尽人意,很大程度上与机器学习方法的使用不当有关。本文介绍一篇顶会最佳论文,该论文总结了机器学习在安全场景下使用的10大误区,并且指出这些问题非常普遍,且对模型的表现有较大影响。希望读者朋友们了解并尽量避免上述误区。
参考文献
[1] Arp, Daniel, et al. "Dos and don’ts of machine learning in computer security." Proc. of the USENIX Security Symposium. 2022.
内容编辑:创新研究院 童明凯
责任编辑:创新研究院 陈佛忠
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
