作者:Mancy 编辑:Joann
摘要
社会治安关乎每一个公民的人身安全和财产安全,本期小性感带大家一起看看如何利用大数据来预测犯罪案件发生区域,降低犯罪率。重点介绍的是预测过程中,如何选取正确的特征变量,怎样做特征选择。
我们生活在一个并不完美的世界中。本月,一位21岁的空姐在搭乘滴滴顺风车途中被司机杀害。这并不是个案,各类的网约车性骚扰、抢劫、殴打乘客等案件时有发生。不仅是网约车,在经济日益发达,贫富差距也日渐悬殊的今天,人性的黑暗面往往更加容易被触发。如果警务人员可以知道哪一条道路,哪一个时间点,怎样的天气会更容易遭遇犯罪事件,是不是可以更好地分配警力,公众是不是可以更好地避开高危地区?
自2011年起,许多欧美发达国家就开始利用大数据来预测潜在的犯罪发生区域,并且取得了非常不错的效果。预测性警力分配(Predictive Policing)大大提高了警务人员的执勤效率,在最易于发生犯罪的时间把警力部署到最易于发生犯罪的区域,使得许多潜在犯罪者心生戒备而放弃作案。下图为预测软件分析的加州圣克鲁兹市(Santa Cruz)盗窃案件可能发生的区域。
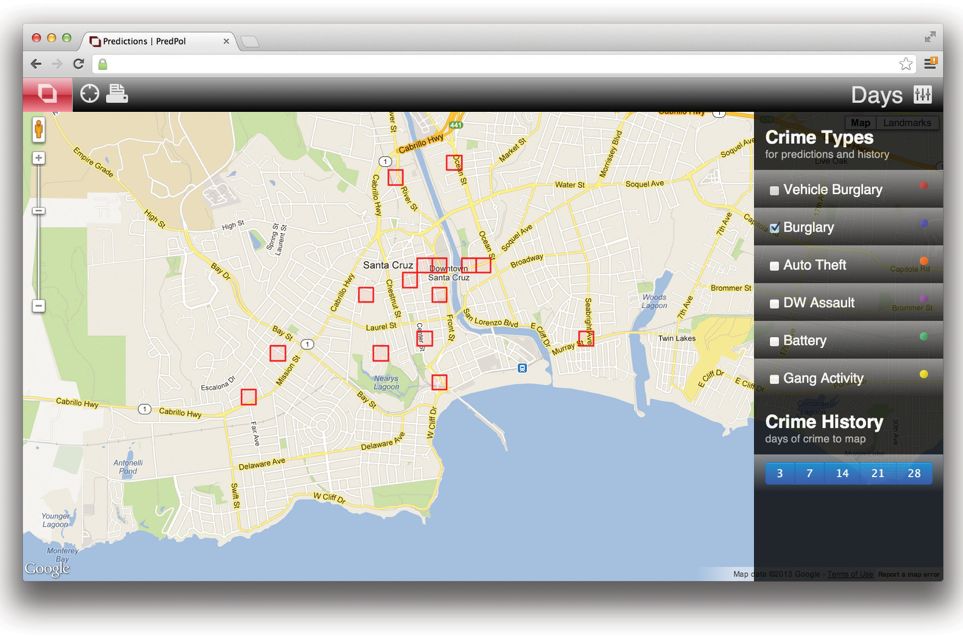
△不同类型犯罪易发生区域中,盗窃案件易发生区域
哪些是合适的预测特征变量?
除了最基础的过往犯罪记录数据之外,新兴的预测方法所运用的数据来源更加广泛。预测犯罪可能发生的地点所需的变量被划分为三个类别:
1、空间变量:犯罪案件发生地点
2、时间变量:犯罪案件发生时间
3、社交关系变量:获得更多案件信息,包括罪犯逃跑落脚点等
空间变量
一般从以下3个维度出发,寻找合适的空间变量:
????潜在受害者的活动范围:以抢劫、盗窃为例,大型商超和酒店人流繁杂,很容易给扒手可乘之机。富人区里停放的名车和不菲的家装也是窃贼们垂涎的对象。
????罪犯的逃生路线:州际高速公路、大桥隧道、地铁等等为罪犯提供了方便快捷的逃跑方式,因此,这些地方附近是罪犯首选的犯罪场所。
???? 罪犯的落脚点:酒吧、成人用品店、快餐连锁店、公交站、公共医疗站这些人流密集不容易引起注意的地方是罪犯们极佳的临时落脚点。他们也会在离这些地方不远的区域实施犯罪计划。
时间变量
时间变量会随天气、活动节日等因素改变。研究人员收集了来自美国50个州的犯罪率和天气数据,发现季节性的温度变化和暴力、财产犯罪发生率呈正相关。社会学家认为高温会引发愤怒,沮丧等情绪,导致人类的攻击性行为,因此和暴力相关的犯罪会增加;随着季节的变化,温度升高会促使人们更多地呆在室外,因此人们更有可能成为受害者,与此同时无人的房子也更有可能成为窃贼的目标。其他的时间如薪水发放日、大型文体活动举办期、夜间、自然灾害期这些时间也更容易引发犯罪事件。
社交关系变量
该变量描述了两个个体之间的关系。这些关系当中包含积极和消极的关系。积极的关系有家庭亲属关系,朋友关系,共事关系等等,消极的关系如施害者与被害者、违约的债权人和债务人。当我们明确预测方向的时候,就可以选择将某一类的关系作为预测变量。例如,分析人员试图预测嫌疑人的藏身之处,通常嫌疑人有很大概率投奔自己信任的人群,那么这时我们就会使用积极关系中的变量去做预测分析。

△常用的空间、时间、社会关系变量
预测盗窃和侵犯需要不同的特征变量
这么多的预测变量,我们要怎样使用呢?小性感想告诉大家,当你明确了一个预测方向之后,并不是每个变量都有预测效果的。应当根据预测的需求和变量的相关性,选择最有解释力度的变量代入模型。
举例来说,每种类型的犯罪(盗窃、杀人、性侵犯)预测是由一组不同的预测变量预测产生的。有些犯罪最有可能发生在人口稠密的地区(扒窃),其他罪行(性侵犯)最有可能发生在偏僻的地方。在为特定的犯罪类型开发预测模型的时候,选择合适的变量是异常关键的。
然而,选择变量充满困难。小性感发现,虽然性侵犯这类罪行不会发生在购物中心的人流密集区,但购物中心内部的楼梯井和停车场隐蔽处也极有可能成为罪犯的选择。所以,选择变量除了依靠经验判断之外,还需要依靠模型中的特征变量相关性去判断某一个变量是否有预测价值。我们把这一过程称之为“特征选择(Feature Selection)”。在下面的案例中,小性感将带你了解预测的步骤以及什么是“特征选择”。
真实案例教你如何做特征选择
在2014年,来自意大利特伦托大学、麻省理工媒体实验室、巴塞罗那电信研究所的研究人员利用多方数据源建立了一个预测模型,用于预测伦敦市区的潜在犯罪区域。他们的预测成果获得了70%的准确率(与真实的犯罪区域相比对),让我们来看看他们是怎样得出这一结果的。
第一步:数据来源1、区域犯罪案件的数据集
包括所有已发生犯罪的地理位置(以经纬度表示)、类型、发生时间、罪犯信息。2、区域信息档案的数据集
这是一个官方的开放数据集,包含68个不同的指标,包括人口数量、流动人口、种族、语言、就业失业、收入、教育、志愿服务、就业密度、碳排放、预期寿命、政治倾向等等。
3、区域人类活动的数据集
该数据集由一个在线平台Smartsteps提供,数据来源于人们在手机移动端记录的日常活动数据。Smartsteps将伦敦市区分为了124119个细胞块,针对每个细胞块的人类活动都有清晰的统计,如年龄分布、性别分布、在家时长、区域不同时间的人口密度等等。
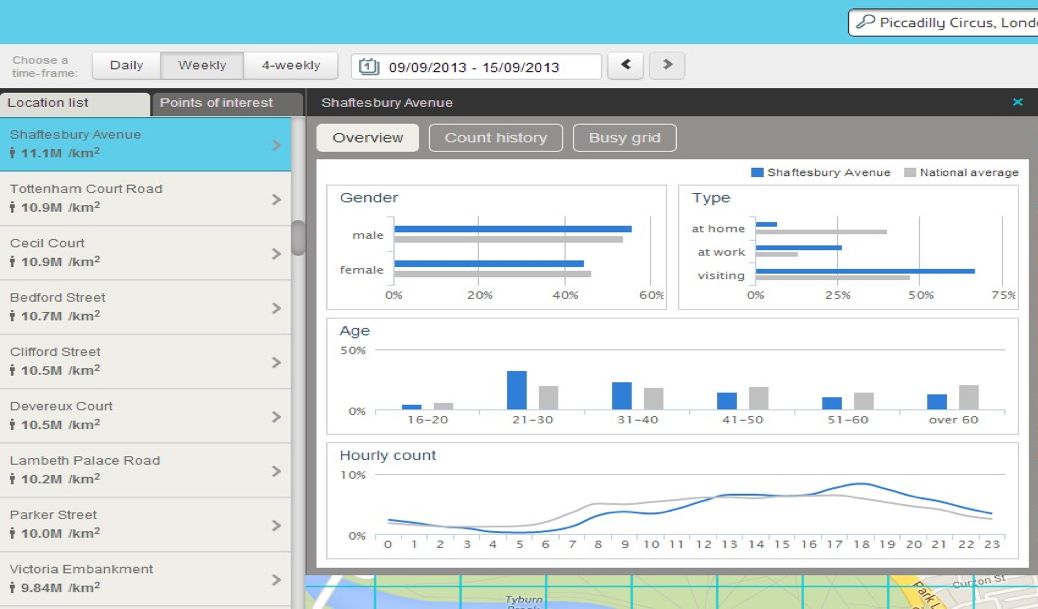
△细胞块示意图(红色代表高密度人口地区)
第二步:模型训练
1、将所有数据随机分为训练数据(80%的数据)和测试数据(20%的数据)。特征排序和特质子集选择均使用训练数据,用来发现潜在的预测关系。而测试数据则用来评估预测模型的强度和效用。
2、特征选择(Feature Selection/ Variable Selection)
特征选择,是在构建模型时为删除冗余数据,选择相关特征变量子集的过程。目的在于:简化模型使其更易于解释;缩短模型训练时间;避免过多维度的数据;减少过度拟合以增强模型的泛化。
特征排序(Feature Ranking):进行特征选择的一种方法。在这个案例当中,用于特征排序的指标是基尼系数(Gini Coefficient of Inequality)的下降值。基尼系数介于0和1之间,0表示所有维度都具有相同的预测能力,1表示他们的预测能力差别最大。特征子集若有最大的基尼系数下降值,就说明它在预测准确性上提高得最多。
本次特征选择从最初的大约6000个特征变量中筛选出了预测能力最强的68个特征子集,将特征空间的维度减少了90倍。特征选择中的排名前20的特征变量如下表:
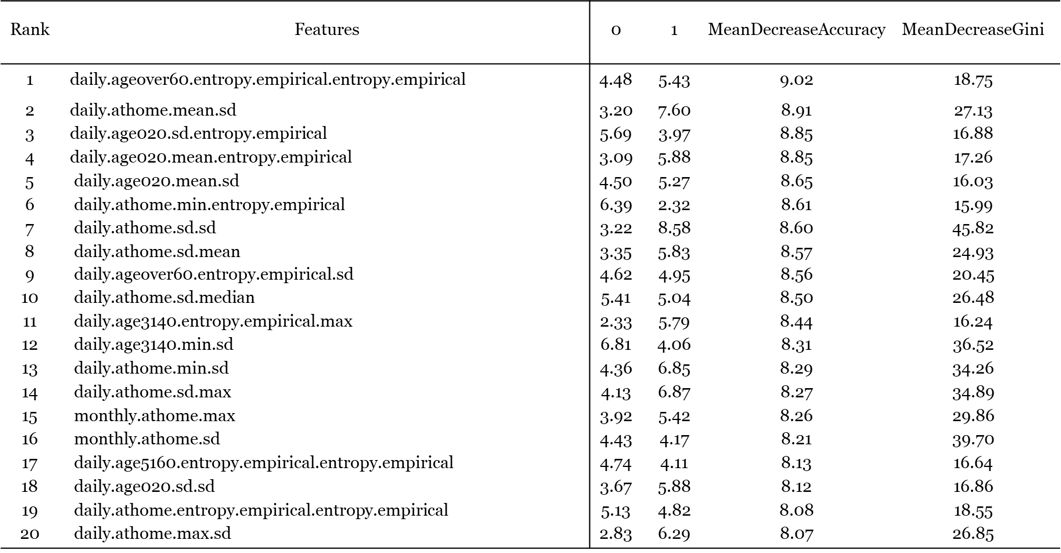
△特征选择中的排名前20的特征变量
注:daily, monthly分别表示以日、月为单位统计的数字
3、 建立模型
在培训了逻辑回归、支持向量机、神经网络、决策树这些分类器(Classifiers)之后,研究团队选择了基于Breiman随机森林算法的决策树作为实践模型。
第三步:结果的可视化
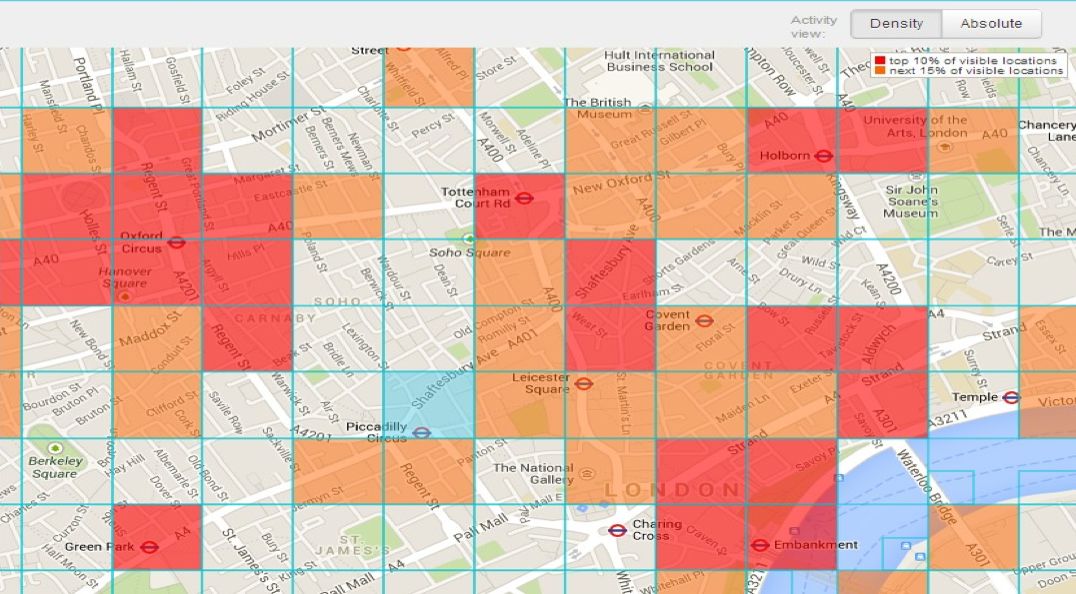
图1展示了研究团队对于伦敦市区犯罪区域的预测结果。在地图中,绿点代表“低犯罪率区域”,红点代表“高犯罪率区域”,点的大小代表区域半径。对比实际统计的犯罪发生区域(图2),模型预测的准确率高达70%。

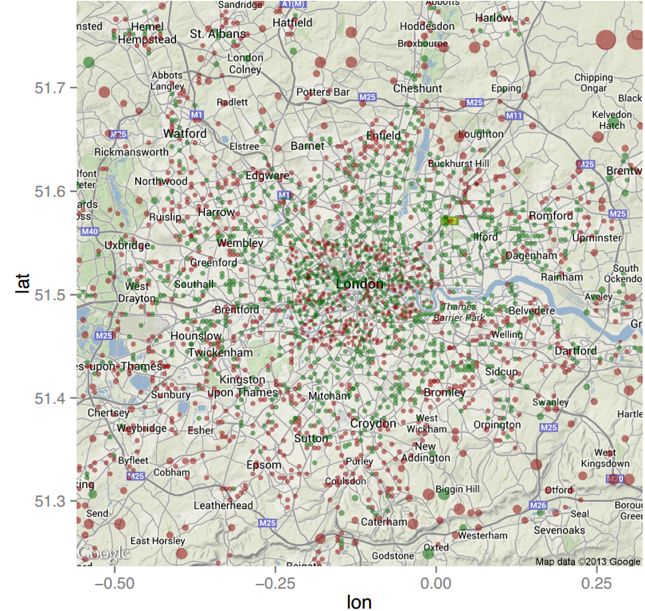
△图2:实际统计的犯罪区域
你知道吗
美国加州的圣克鲁兹市(Santa Cruz)在使用大数据的预测结果作为警力分配的参考之后,盗窃事件的数量降低了27%。
美国的田纳西州,自实施预测分析后,严重犯罪(serious crime)的数量下降了30%,暴力犯罪的数量下降了15%。
英国的警察们也发现,根据预测结果改变巡逻地区后,遇到犯罪事件的概率是随机巡逻的10倍。
小性感觉得,这样的预测效果真的是非常可喜呀!值得高兴的是,我国的警务人员也开始探索使用大数据预测为警力的部署提供参考。小性感在想,如果未来在夜间的机场打车区部署更有力的警方监控和查证人员,也许下一个类似的遇害事件就不那么容易发生了。你说呢?
延伸思考????
数据科学在警务系统取得的成功也让数据伦理与数据安全的难题再一次浮出水面。在数据为我们的安全服务的同时,人们对于自己的隐私安全反而不再有安全感。谁可以搜集这些数据?又是谁可以使用这些数据?怎样保证这些数据不被泄露?当数据科学技术被引入到越来越多的领域,这些问题将一次又一次地冲击在技术发展中眩晕的我们。
除了以上问题,过于强调降低犯罪率会不会忽略了警务系统面临的其他问题?是否降低了犯罪率就解决了所有的问题?这些问题都亟待讨论。
欢迎留言和小性感讨论你的想法(对本期的思考,对往期和未来内容的建议,表白当然也欢迎嘤嘤嘤)都来后台勾搭我们噢!
资料传送门
1.Predictive Policing
http://www.businessofgovernment.org/sites/default/files/Predictive%20Policing.pdf
2.Towards Crime Prediction from Demographics and Mobile Data
https://arxiv.org/pdf/1409.2983.pdf
声明:本文来自现感,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
