尽管深度人脸识别(Face Recognition, FR)系统在识别和验证方面表现出惊人的性能,但它们也因过度监视用户而引起隐私问题,对于在社交网络上广泛传播的公共人脸图像尤其严重。最近,一些研究采用对抗性示例来保护照片不被未经授权的人脸识别系统识别。然而,现有的对抗人脸图像的方法存在许多局限性,例如视觉效果不佳、对模型的可访问性依赖程度高、黑盒迁移性差等,这使得它们难以应用于现实人脸隐私保护场景。为此,我们提出了一种新的人脸隐私保护方法,即对抗妆容迁移网络(AMT-GAN),该方法能够生成具有更强黑盒迁移性与更好视觉质量的对抗人脸图像。为实现此方法,我们通过引入一个新的正则化模块并提出新的联合训练策略,以协调对抗噪声和妆容迁移循环一致性损失之间的冲突,从而在攻击强度和视觉质量之间实现更好的平衡。大量实验证明,与现有技术相比,AMT-GAN不仅可以保持舒适的视觉质量,而且在人脸识别商用API(包括Face++、Aliyun和Microsoft)上实现了更高的攻击成功率。
该成果“Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-Robust Makeup Transfer” 发表在CCF A类国际会议IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022上。该会议与ICCV、ECCV并列为世界三大计算机视觉会议,是人工智能与计算机视觉发展的风向标之一。此次CVPR 2022会议录用率约为25.33%,与往届平均录用率相当。

论文链接:
https://openaccess.thecvf.com/content/CVPR2022/html/Hu_Protecting_Facial_Privacy_Generating_Adversarial_Identity_Masks_via_Style-Robust_Makeup_CVPR_2022_paper.html
代码链接:
https://github.com/CGCL-codes/AMT-GAN
背景与动机
近年来,基于深度神经网络的人脸识别技术(FR)发展迅速。然而,强大的人脸识别系统也对个人隐私构成了巨大威胁。例如,FR系统可用于识别社交媒体档案,并通过大规模照片分析跟踪用户关系网。这种对用户的过度监视,导致当前迫切需要一种有效的方法来帮助个人用户保护其人脸图像免受未经授权的FR系统的恶意监视。
对恶意FR模型的训练数据集或图库数据集发起数据中毒攻击(data poisoning attacks)是保护面部隐私的一个有效解决方案。然而,这些方案需要敌手(即我们场景中的用户)能够向数据集中注入投毒人脸图像。一旦目标模型已经训练完毕,或者其在干净的数据集上进行推理,那么上述方法很可能变得无效。
另一种策略是利用对抗样本发起对抗攻击(adversarial attacks),从而防止人脸图像被非法识别。基于对抗攻击的人脸图像更适合在真实场景中保护用户隐私,因为无论目标模型的设置如何,它们只需要修改用户自己的数据。然而,现有的人脸对抗样本生成方法在用于保护社交媒体人脸隐私时会受到诸多限制:
(1)目标模型的可访问性。大多数现有方案属于白盒攻击(即敌手能够访问目标模型的全部参数),或基于查询的黑盒攻击(即敌手可以任意查询目标模型)。由于用户不知道恶意的第三方运行的是哪种深度网络模型,因此上述需要访问目标模型的方法无法用来保护用户的隐私;
(2)视觉质量差。如图1所示,对FR系统的现有对抗攻击无法在黑盒设置中保持图像质量,而基于补丁的对抗性攻击通常会对原图像造成相当奇怪和明显的变化;
(3)黑盒攻击的迁移性弱。即现有方法在商业API上具有相对较低的攻击成功率。总之,在黑盒环境下,如何平衡人脸对抗图像的视觉质量和攻击能力仍然是一大挑战。
为解决上述问题,我们提出了一种新的框架,称为对抗妆容迁移网络(AMT-GAN),该网络能够生成具有自然外观和更强黑盒攻击强度的对抗人脸样本。ATM-GAN首先利用一组生成对抗网络(GAN)来构建对抗样本,这些对抗样本可以从参考图像中继承化妆风格。同时,为了调和对抗噪声与妆容迁移循环一致性损失之间的冲突,该方法利用编码-解码器结构的解耦功能,引入了一种精心设计的正则化模块。通过该正则化模块,对抗性毒性可以在循环重建阶段得到可观的缓解,这使得生成器能够更好地在源域和具有对抗性特征的目标类型域之间建立鲁棒映射。此外,我们还设计了一种新的联合训练策略,该策略将传统的生成器-鉴别器博弈与新设计的正则化模块相结合,能够在不同模型之间鼓励生成器捕捉、模仿和重构具有高迁移性的通用对抗特征。

图1 AMT-GAN方法的可视化生成结果(最右)以及与其他方法的对比
方案设计
如图2所示,我们提出的AMT-GAN整体框架包含有一个生成器G,两个鉴别器DX、DY,正则化模块M。
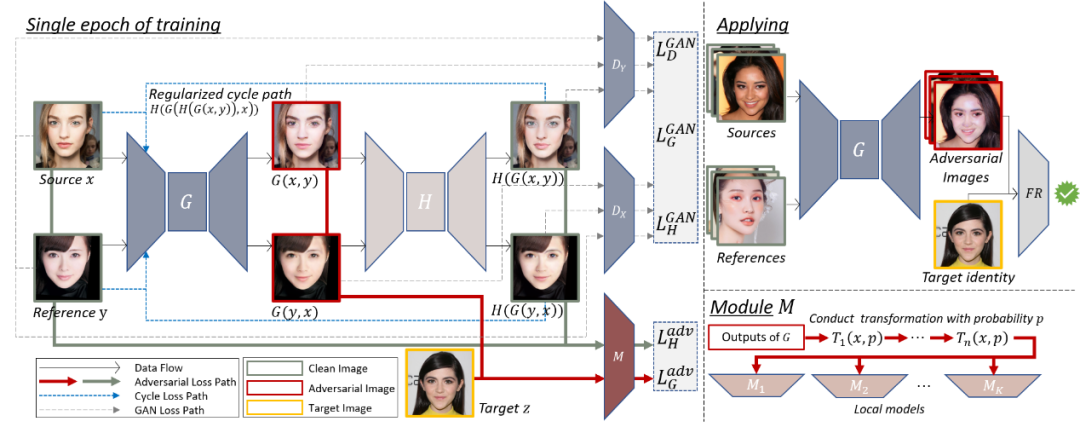
图2 AMT-GAN端到端训练-生成框架图
生成器G和鉴别器DX、DY:生成器G为输入图像生成对应的对抗样本,同时确保整体肉眼视觉效果自然,且化妆风格从源域更改为参考域。鉴别器DX和DY用于区分由G生成的假图像和真实图像的分布。
正则化模块H:循环一致性损失失效是图到图转译生成网络应用于对抗样本领域面临的一个关键挑战,也是我们方法着重解决的一个问题。通常,循环一致性损失函数如图3(a)所示,该过程表示为:
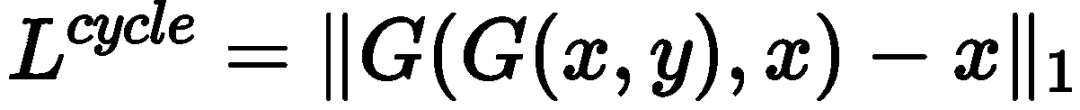
然而,循环一致性损失与对抗样本的对抗特性相冲突。如图3(b)所示,当建立从对抗域YA到源域X的逆映射时,生成的对抗性示例G(x, y)被反过来当做生成器G的输入图像。由于此图像对干净源域X中的样本进行了对抗性修改,生成器G可能无法提取G(x, y)的特征,因此无法将该具有对抗性的输入图像从对抗性域YA转换回干净源域X。因此,循环一致性损失中要求的重建样本G(G(x, y), x)可能与原图像x显著不同,即G(G(x, y), x)位于某个意外域中,而不是原域X。简而言之,由于给生成器G的输出具有对抗性,因此G很难建立从YA到X的鲁棒逆映射。这种现象使得现有的循环一致性损失不适用于我们聚焦的基于妆容迁移的对抗生成任务。
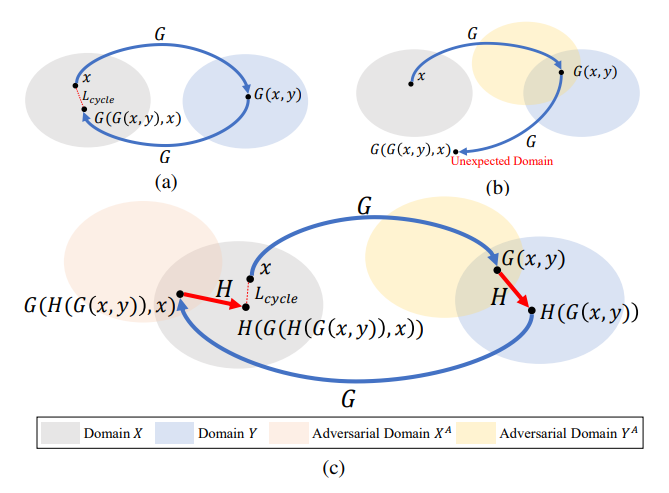
图3 对抗循环损失示意图
为了确保循环一致性损失正常发挥效果,AMT-GAN训练框架中引入了一个正则化模块H。该模块被设计用来生成干净的图像H(G(x, y)),其内容、风格和尺寸与G(x, y)相同,但不具有对抗性。如图3(c)所示,H将生成的图像G(x, y)从对抗域转换为非对抗域,从而保证在进行循环重建训练过程中,对抗性损失不会对生成器进行攻击从而导致循环一致性损失失效。图4所展示了相应的可视化结果,在没有正则化模块的情况下,生成器可能会生成具有不自然细节的图像,这表明生成器对于域之间的映射在某种程度上受到了破坏。这是因为对抗毒性损害了循环一致性损失。通过应用正则化模块H,循环一致性损失正常工作,并确保了生成器输出更自然的图像。

图4 采用对抗净化模块前(左)和采用对抗净化模块后(右)
黑盒迁移性增强模块M:该模块由K个预训练的人脸识别模型组成,这些预训练的人脸识模型在公共人脸图像数据集上具有较高的精度。当我们训练AMT-GAN时,上述这些模型将充当白盒模型并试图模仿我们无法访问的潜在目标模型的决策边界。该模块算法将同时进行模型聚合训练和输入多样性处理。上述过程可以表达为:
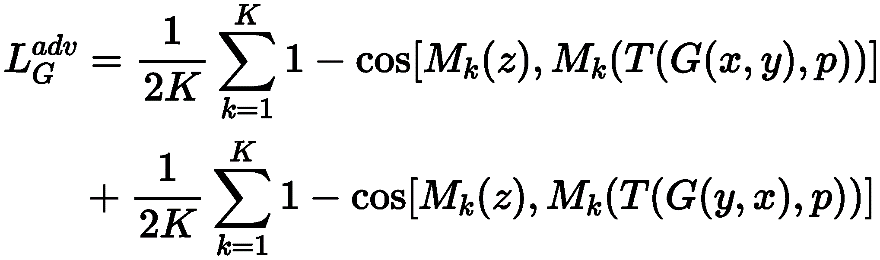
辅助目标函数:AMT-GAN使用直方图匹配与LPIPS感知损失作为辅助函数,进一步增强妆容迁移的准确度与生成图像的视觉质量。直方图匹配通常用于模拟参考y的颜色分布,同时保留x的内容信息。在这里,我们使用此目标函数来确保嘴唇、眼影和面部区域的妆容相似性以及正则化模块H的重建能力。LPIPS感知损失用来避免生成器G为了达到对抗性而扭曲人脸图像结构信息的行为。
实验评估
表1展示了针对四种不同的人脸识别模型的黑盒攻击强度。在公共数据集上被攻击的这些目标模型具有很高的识别准确率。对于每个被攻击的目标模型,其他三个模型将用作AMT-GAN的集成训练模型,从而确保被攻击模型的不可访问性。表中指标为攻击成功率(ASR),该项指标越高则表明攻击能力越强。实验结果表明,AMT-GAN在黑盒环境下具有较强的攻击能力。
表1 在黑盒人脸识别模型上的攻击成功率
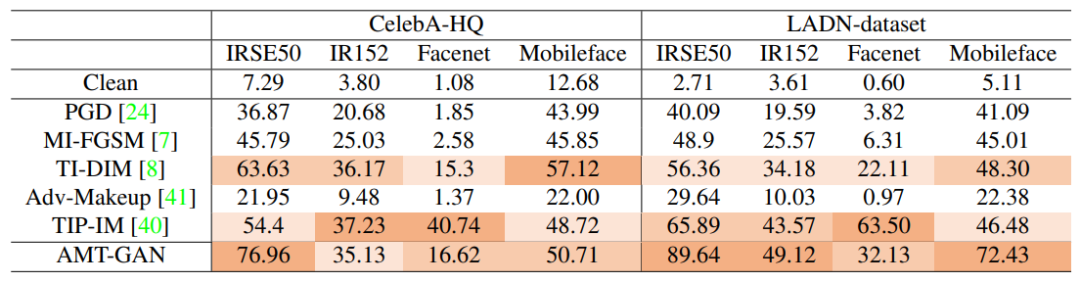
图5展示了AMT-GAN在不同测试数据集(CelebA-HQ, LADN)上针对Aliyun和Face++人脸识别商用API的攻击性能。图表中所展示的数值为API对错误人脸配对返回的置信度得分,得分越高表明对应攻击方法的强度越高。实验结果表明,对于两种API,AMT-GAN在攻击能力方面都优于竞争对手。具体而言,针对Face++平台,排名第二的方法平均置信度为61.99,而我们的方法为64.58。对于Aliyun平台,排名第二的平均置信度是32.37,而我们的方法是53.53。我们所提出的AMT-GAN方法的攻击强度比竞争对手高出约4%至60%。同时值得注意的是,AMT-GAN在不同API之间也具有更强的性能稳定性,而综合排名第二的方法在阿里云中的性能与在Face++上的性能相比有很大的下降。

图5 针对主流商用人脸识别API的攻击置信度结果
同时,我们也与同样适用妆容迁移进行人脸对抗攻击的方法(Adv-Makeup)进行了比较。如图6所示,由Adv-Makeup生成的图像在眼睛区域之间具有锐利的边缘。相反,AMT-GAN的生成图像更为逼真,且图像细节更为平滑。这是因为Adv-Makeup仅以部分改动的方式来改变原始人脸图像的眼部区域,这导致其虽然在视觉质量定量评估方面具有良好性能,但与AMT-GAN相比具有较弱的黑盒攻击强度和锐利的边缘问题。

图6 可视化结果以及与Adv-Makeup方法的对比
我们在论文中也展示了针对AMT-GAN生成图像的视觉质量定量评估实验以及相关模块的消融实验。(刘晓耕、胡胜山)
详细内容请参见:
Shengshan Hu, Xiaogeng Liu, Yechao Zhang, Minghui Li, Leo Yu Zhang, Hai Jin, and Libing Wu. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 15014-15023.
https://openaccess.thecvf.com/content/CVPR2022/html/Hu_Protecting_Facial_Privacy_Generating_Adversarial_Identity_Masks_via_Style-Robust_Makeup_CVPR_2022_paper.html
声明:本文来自穿过丛林,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
