今天分享的论文主题为:Web缓存欺骗漏洞测量。Web缓存欺骗,Cache Deception,是指攻击者诱导网络代理服务器缓存受害者隐私数据,使得攻击者可绕过登录授权验证,直接访问已缓存的用户敏感数据。文章围绕Web缓存欺骗漏洞的安全隐患,开展了大规模测量研究,发现该漏洞即使在公开披露两年后,仍然在热门网站中广泛存在。
文章作者呼吁网站运营者谨慎地设置内容缓存策略。该工作由来自意大利特伦托大学、美国东北大学以及Akamai公司等的研究人员共同完成,发表于网络安全领域顶级学术会议USENIX Security 2020(录取率157/977 =16.1%)。

【研究背景】
为了降低用户网络访问时延,很多Web系统使用缓存功能存储一些经常被互联网用户访问的网络资源。例如,浏览器等终端应用为个人用户提供网页访问的“私有”缓存;而网络代理等中间盒子则为互联网用户提供“共享”缓存。内容分发网络(Content Delivery Networks,CDN)便是强烈依赖于Web缓存的一类中间盒子。CDN通过部署大规模共享缓存代理节点,使终端用户可从最近节点直接获取网页内容,从而减少延迟、提升访问效率。
通常来说,Web缓存对象是静态资源,如静态HTML、JavaScript等。管理者需要配置一定的缓存规则,决定缓存资源的类型、访问名称等。一种常见且简单的配置规则基于资源路径或文件名(URL),如规定所有扩展名为jpg的文件都将被缓存。
对某些包含用户隐私信息的资源来说,CDN等“共享”Web缓存应进行正确配置,防止其缓存被其他用户越权访问。但部分Web服务机制可能导致隐私缓存被越权访问。例如,一些Web服务器会引入URL重写,如将example.com/index.php?p1=v1&p2=v2重写为example.com/index/v1/v2,以兼容多样的用户访问。
然而,URL重写机制可能导致资源路径混淆。例如,用户通过example.com/index/img/pic.jpg访问Web服务,CDN认为用户访问图像文件;但在Web服务端,该URL被解释成example.com/index.php?p1=img&p2=pic.jpg,即index.php文件。此类路径混淆将导致CDN与Web服务器对资源类型、缓存执行策略判断不一致,引入错误缓存隐私信息的安全风险。
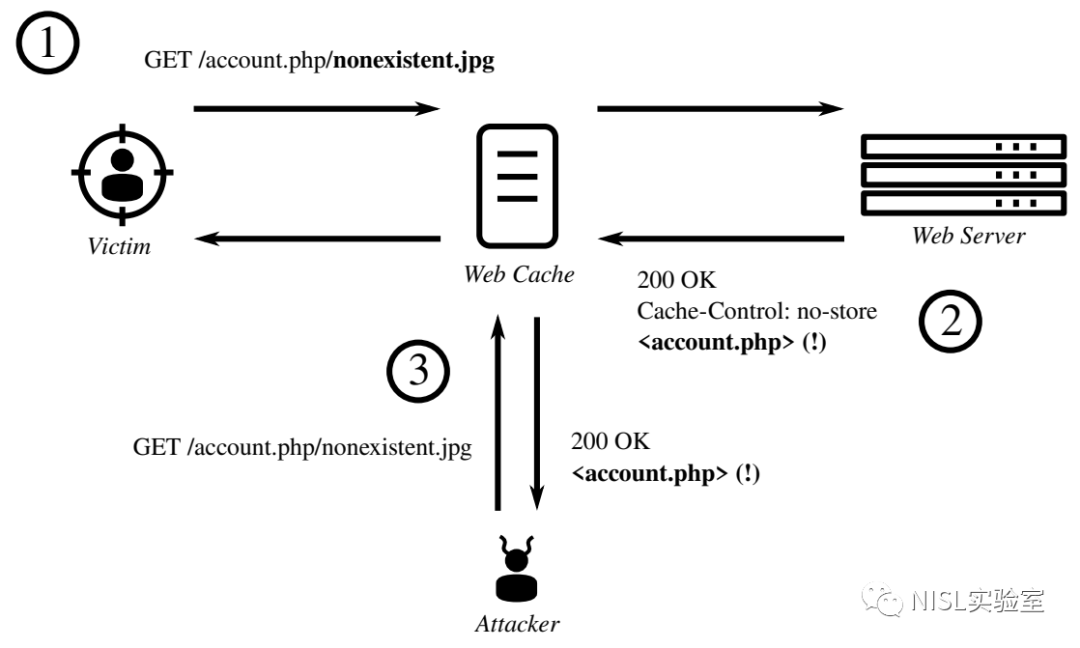
图表1:Web缓存欺骗攻击原理
2017年Blackhat会议首次公开披露的Web缓存欺骗漏洞[1],便是利用路径混淆问题越权访问隐私缓存。如图表1所示,其本质在于Web服务与缓存服务器对同一URL路径的理解不一致:
Web服务器将URL路径理解为带有隐私信息的页面
并返回相应内容,该内容不应被缓存。 中间盒子将URL路径理解为可被缓存的静态对象
,错误地执行缓存。
因此,攻击者可利用社会工程学手段诱导受害者访问此类路径混淆URL,并在CDN执行隐私信息错误缓存后重复该请求,越权访问受害者的隐私数据。
尽管Web缓存欺骗漏洞已被公开披露,研究人员也发布了相应的检测工具[2][3]。但此类工具需要测试者对目标服务器有控制权,因此安全研究人员无法开展规模化测试。为此,文章提出了一个系统化测量框架,可对现网环境中对Web缓存欺骗漏洞进行规模化检测。
【测量方法】
文章提出的Web缓存欺骗漏洞检测方法,包括如下三个步骤:

图表2:测量步骤示意图
步骤1:测量准备
攻击者利用缓存欺骗漏洞的最终目的是窃取用户隐私数据,因此,需要用户创建个人账户的网站才可能成为攻击目标。作者首先爬取了热门域名及其子域名,以筛选攻击目标;其次,分别创建受害者账户和攻击者账户,并在受害者账户中填入隐私信息,以进行受控条件下的攻击实验。此外,作者还利用爬虫程序采集账户Cookie信息,对用户登录状态进行判断。
步骤2:目标收集
Web缓存欺骗攻击的关键是找到引起路径混淆理解的URL。为此,作者首先对候选网站页面中的URL进行递归爬取,形成备选URL集合;随后根据URL的具体结构及页面类型,将相似的URL归类,并从每类中随机选取1个URL作为测试目标。
步骤3:漏洞检测
执行Web缓存欺骗攻击:依次控制受害者账户、攻击者账户访问一个不存在的静态资源URL,查找响应进行比较。访问的URL由步骤2采集到的URL附加"/
.css"(random为随机字符串)构成。 提取标记信息:执行攻击后,从攻击者的响应中提取受害者的个人信息(由实验人员控制生成)。
提取令牌信息:提取一些令牌和凭据(例如CSRF令牌)。
测量实现的一些具体细节还包括:
为防止爬虫触发防御和限制系统,作者使用了真实的浏览器进行爬取,并对所有发现的漏洞进行了手动确认;
为便于实现自动化检测,文章的测量目标主要是Alexa排名前5000域名,支持Google OAuth登陆且不需要额外信息的站点。
此外,文中还就性能影响、安全性问题、漏洞披露和实验可复现性4个方面进行了补充讨论,请感兴趣的读者参考原文。
【测量发现】
文章针对系统检出的Web缓存欺骗漏洞展开了测量分析,主要回答以下几个问题:
Q1: 多少知名网站受到Web缓存欺骗漏洞的影响?
Q2: Web缓存欺骗洞是否会直接暴露用户敏感信息?
Q3: 在攻击者未经身份验证的情况下,是否可以利用Web缓存欺骗漏洞?
Q4: 能否能对路径混淆方法进行扩展,进一步扩大Web缓存欺骗漏洞的攻击面?
Q1:多少知名网站受到Web缓存欺骗漏洞的影响?
——Web缓存欺骗漏洞广泛存在于流行网站和CDN厂商中。
为了自动化地创建测试账户,作者将Alexa排名前5K的网站中支持Google OAuth身份认证的295个网站作为初始目标,并最终识别出16个包含Web缓存欺骗漏洞的网站,其热门程度分布如图所示:
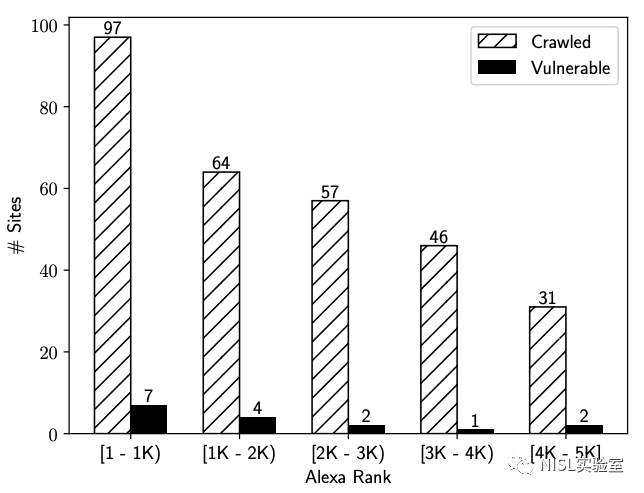
图表3:受Web缓存欺骗漏洞影响的知名域名Alexa排名分布
作者还根据响应的HTTP headers,对存在漏洞的站点是否使用CDN及具体的CDN供应商进行了识别,如图表4所示。尽管Web缓存欺骗理论上可能出现在任何一种Web缓存中,文章发现的所有漏洞站点都部署了CDN服务,说明CDN可能是目前漏洞仍普遍存在的主要原因。

图表4:Web缓存欺骗漏洞在CDN厂商中的分布
Q2:Web缓存欺骗洞是否会直接暴露用户敏感信息?
——绝大部分漏洞站点中暴露了用户敏感信息。
如图表5所示,在16个漏洞站点中,有14个泄露了用户隐私信息(PII),如姓名、用户名、邮件地址、电话号码等。此外还有一些财务信息被泄漏,可被用来执行鱼叉式钓鱼网络攻击。
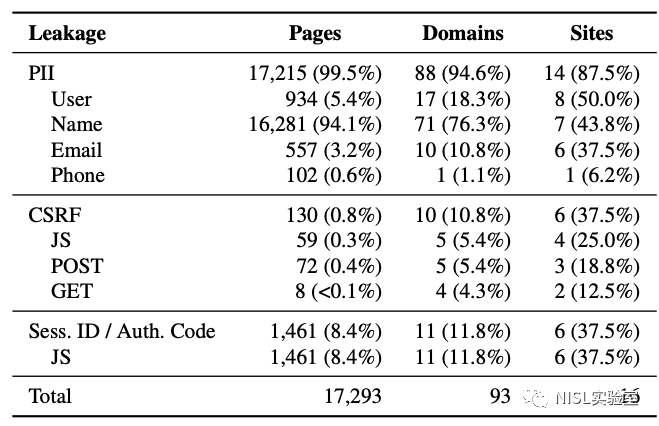
图表5:Web缓存欺骗攻击泄露用户敏感信息情况分布
Q3:在攻击者未经身份验证的情况下,是否可以利用Web缓存欺骗漏洞?
——本文发现的漏洞均可被利用。
作者通过不携带Cookie访问攻击URL的方式,测试了未经身份验证的用户利用Web缓存欺骗漏洞的可能性。经确认,本文发现的所有漏洞都可被未经身份验证的用户利用。
Q4:能否能对路径混淆方法进行扩展,进一步扩大Web缓存欺骗漏洞的攻击面?
——可通过插入特殊字符实现攻击扩展。
作者尝试对URL进行类似模糊测试的混淆扩展,如图表6所示(每个URL的第二行为混淆扩展后的形式),包括向其中插入编码后的换行符、分号、井号等。并基于扩展后的URL,于2019年7月(第一次实验的14个月之后)展开第二轮测量。测量目标除了原有的295个网站,还包括Alexa排名前5K中随机选取的45个未使用Google OAuth的网站,以消除潜在的测量偏差。

图表6:路径混淆变种方法示意
如图表7、8所示,与原始URL相比,扩展后的混淆方法能引起服务器200 OK响应的数量明显增加,并进一步导致服务器以更高的概率返回带有用户敏感信息的内容。实验结果证实了扩展混淆技术能显著地增加Web缓存欺骗漏洞的攻击面、提升成功率。
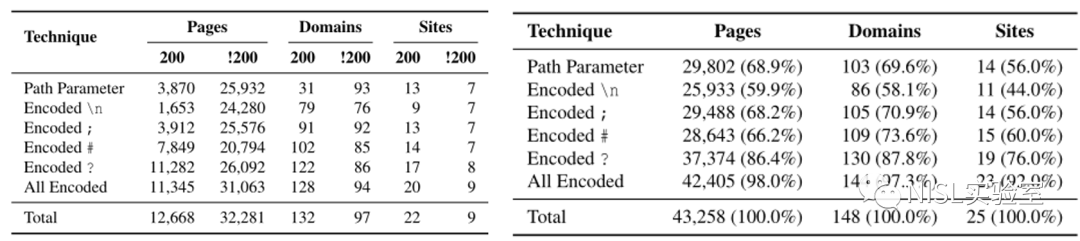
图表7、8:变种路径混乱方法测量结果
【结论】
文章针对现实网络环境中的Web缓存欺骗漏洞开展了大规模测量,最终发现,即使是在漏洞公开披露的两年后,仍有大量热门网站存在上述漏洞。研究表明,Web缓存不是一项可以“即插即用”的技术,正确地配置缓存策略绝非易事。许多CDN厂商的默认配置没有严格遵守RFC,是导致Web缓存欺骗漏洞普遍存在的主要原因之一。(李家琛)
原文链接
https://www.usenix.org/system/files/sec20-mirheidari.pdf
参考文献
[1] Omer Gil. Web Cache Deception Attack. Black Hat USA, 2017. https://www.blackhat.com/us-17/briefings.html#web-cache-deception-attack.
[2]Arbaz Hussain. Auto Web Cache Deception Tool, 2017. https://medium.com/@arbazhussain/auto-web-cache-deception-tool-2b995c1d1ab2.
[3]Google Identity Platform. Using OAuth 2.0 to Access Google APIs. https://developers.google.com/identity/protocols/OAuth2.
编辑&审校|张一铭、刘保君
声明:本文来自NISL实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
