摘要:
网络上大量安全情报知识以多源、异构、碎片化的形式存在,为使这些信息表达成安全人员能够有效管理、理解、组织的形式,构建了基于Neo4j的网络安全知识图谱。首先,设计了网络安全本体模型;其次,将权威知识库作为数据源,利用Scrapy爬虫框架采集网络安全数据并进行知识抽取,深入研究知识融合技术对实体进行对齐;最后,使用Neo4j图数据库实现网络安全知识图谱的构建。网络安全知识图谱的构建为安全人员提供了直观、可靠的安全知识查询,也为后续安全场景应用提供了支撑。
内容目录
1 研究现状
1.1 网络安全本体研究
1.2 网络安全知识抽取研究
2 网络安全知识图谱构建
2.1 网络安全本体建模
2.2 网络安全数据获取与知识抽取
2.2.1 网络安全数据源
2.2.2 数据获取与知识抽取
2.3 网络安全知识融合
2.3.1 表示字符串特征的相似度
2.3.2 表示语义特征的相似度
2.4 网络安全知识图谱的存储
3 结 语
近年来,信息技术的突飞猛进,使得网络攻击对网络环境的威胁日益严重,影响了计算机的安全使用。同时,网络攻击也朝着新的趋势发展,自动化程度和攻击速度逐渐提高,攻击行动多变难以捉摸,使得安全专家疲于分析应对。传统的互联网信息检索对信息的获取缺乏及时性和准确性,无法满足信息时代人们的需求。同时,安全知识库、漏洞库、安全博客、威胁信息库等大量有用的安全信息碎片化分散在互联网上,这些安全知识未被合理整合利用,难以为安全人员提供快速、有效的知识支撑。而知识图谱(Knowledge Graph)在信息的基础上,建立了客观世界中实体间的关系,将互联网上多源异质、动态的信息进行组织、管理及表达,使得网络的智能化水平更高,也为数据挖掘和知识分析提供了支持。
本文基于对已有数据源的分析,构建了网络安全本体,利用Scrapy爬虫框架采集网络安全数据并进行知识抽取,利用已构建的网络安全本体进行实体关系标准化,然后利用相似函数和向量空间模型(Vector Space Model,VSM)对实体进行对齐、融合,最后利用Neo4j图数据库实现网络安全知识图谱的构建。
01 研究现状
知识图谱技术提出后,在众多领域中广泛使用。近几年,对网络安全领域知识图谱的研究也愈发成熟,但为使网络安全知识图谱真正运用于安全应用中,仍需要深入研究。Apache基于Cisco OpenSOC推出了知识图谱项目Metron,主要致力于安全监控和分析,整合最新的威胁情报。MITRE公司开发了安全态势感知系统CyGraph,主要面向网络攻击态势理解和攻击面识别等任务。Harshaw提出了网络智能情报平台Stucco,能够自动化并轻松快速地为分析师提供威胁数据。网络安全知识图谱的研究主要可分为网络安全本体研究和网络安全知识抽取研究。
1.1 网络安全本体研究
对于不同的应用场景,研究人员开发了不同的本体。Iannacone等人提出了一种表示整个网络安全领域的本体模型Stucco,并创建一种知识表示形式,促进异构数据源的集成。Shed等人提出了一种统一的网络安全本体(Unified Cybersecurity Ontology,UCO),旨在支持网络安全系统中的信息集成和网络态势感知,它集成了来自不同网络安全系统的异构数据和知识模型,以实现信息共享和交换。Jia等人构建了包含攻击、资产、漏洞、软件和操作系统5种类型的网络安全本体概念,并以此获得了网络安全知识库。
1.2 网络安全知识抽取研究
Balduccini等人利用支持向量机提取文本相关性特征,再利用遗传算法生成的正则表达式与本体相结合,抽取日志文本中的安全实体。Collobert等人在命名实体识别的通用领域初次利用了深度学习,并取得了较好的效果。至此以后便广泛利用深度学习来提取实体特征。彭嘉毅等人提出将基于字符特性的双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)与条件随机场(Conditional Random Field,CRF)相结合的网络安全领域命名实体识别模型,采用主动学习方法,使用小批标注样本获得了良好的结果。李涛等人提出一种融合对抗主动学习的安全知识三元组抽取方法,利用BiLSTM-CRF模型进行实体和关系的联合抽取,实验表明方案的有效性。
当前网络安全知识图谱在本体和知识抽取方面研究较多,对于网络安全实体对齐研究较少,本文在网络安全实体抽取的基础上,深入研究了知识融合技术,并对抽取后的网络安全实体进行消歧对齐。
02 网络安全知识图谱构建
网络安全知识图谱的构建主要包括本体建模、数据获取与知识抽取、知识融合等重要环节。其构建流程如图1所示。
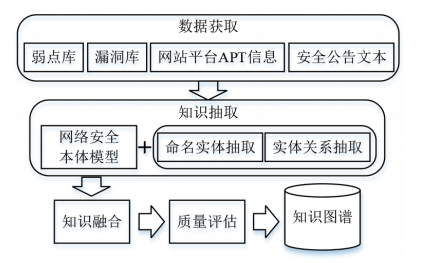
图 1 知识图谱构建流程
2.1 网络安全本体建模
网络安全本体定义了网络安全实体间关系的表达,可以用于组织、表示以及共享网络安全相关的知识,即表示图结构的抽象概念结构类。本体的构建为后续网络安全知识抽取提供了标准。建立的网络安全本体如图2所示。
本体建模参考了各类现行的安全标准规范,分析了结构化威胁信息表达(Structured Threat Information eXpression,STIX)公开的高级持续性威胁(Advanced Persistent Threat,APT)组织报告,利用了STIX 2.1的结构化语言描述与美国国家漏洞库中包含的专家知识和逻辑关系。本体模型主要定义以下8种实体类型及其之间的关系类型。
(1)攻击者。具有对抗行为的入侵活动。可以是个人、团体或组织。攻击者通常会使用某些软件或者攻击模式去完成攻击,故攻击者与软件,攻击者与攻击模式的关系表示为使用关系Use。
(2)软件。攻击者可用来进行攻击的商业代码操作系统实用程序或开源软件。通常分为恶意软件和正常工具。软件与攻击技术的关系表示为实施关系Implement。
(3)攻击模式。攻击者试图破坏目标的方式。如嗅探网络流量,攻击者监视公共或多播网络节点之间的网络流量,试图在协议级别捕获敏感信息。攻击者可以通过某种攻击模式利用存在于目标客体的隐患来进行攻击,故攻击模式与隐患的关系表示为利用关系Exploit。
(4)攻击技术。攻击者进行攻击所执行的动作。如绕过用户账户控制,攻击者可能会绕过用户账户控制(User Account Control,UAC)机制来提升系统中的进程权限。攻击技术和攻击模式在概念的表达上有交叉,又各具特点,故攻击技术与攻击模式的关系表示为相似对应关系Same_as。
(5)缓解措施。可以防止技术成功执行的安全建议或措施。缓解措施与攻击技术的关系为缓解关系Mitigate。
(6)战术。攻击者利用技术或采取行动的目的。如攻击者利用发送网络钓鱼消息技术来达成访问受害系统战术。战术与攻击技术的关系表示为实现关系Accomplish。
(7)隐患。攻击者能够利用的、访问系统或网络的软件缺陷。通常包括弱点和漏洞。隐患与目标客体的关系表示为存在关系Exist_in。
(8)目标客体。攻击者的攻击目标。包括应用程序、系统和平台等。

图 2 网络安全本体
2.2 网络安全数据获取与知识抽取
2.2.1 网络安全数据源
网络安全知识图谱涉及攻击维、资产维和脆弱维3个维度的数据,这些数据大多以半结构化的格式存储并在互联网上开放共享。
(1)攻击维。MITRE公司构建的攻击行为知识库(Adversarial Tactics,Techniques,and Common Knowledge,ATT&CK)与通用攻击模式枚举和分类(Common Attack Pattern Enumerationand Classification,CAPEC)知识库为攻击维数据提供了基础。ATT&CK通过APT攻击组织的可观测数据提供了共性的战术意图和技术模式,以及攻击组织和软件信息。而CAPEC则更关注攻击者对网络空间脆弱性的利用,描述了对已知应用程序脆弱性的攻击行为。
(2)资产维。数据主要来自通用平台枚举 (Common Platform Enumeration,CPE)数据库,CPE为系统和软硬件设备提供了结构化命名规范的描述和标识。
(3)脆弱维。公共漏洞和暴露(Common Vulnerabilities and Exposures,CVE)数据库、美国国家漏洞库收录了全面、应用范围广泛、评分方式公认合理的漏洞,并且每个漏洞具有唯一的ID标识;通用弱点枚举(Common Weakness Enumeration,CWE)数据库提供了常见软件安全弱点列表。
这些知识库对威胁情报的收集、验证和凝练往往依赖于专家经验,为网络安全知识图谱的构建提供了权威可靠的保障。另外,还可以从网络安全博客、APT相关报告、安全公告等文本信息中提取数据。
2.2.2 数据获取与知识抽取
知识库通常以半结构化的Web网页形式存在,实体的信息是通过带有一定结构的记录块来展示的,ATT&CK网站页面如图3所示。图中展示了软件实体AndroidOS/MalLocker.B的相关信息,上半部分分别展示了AndroidOS/MalLocker.B的描述介绍和属性框,下半部分给出了其所能利用的攻击技术。数据的抽取利用网络爬虫技术,结合对网页的人工分析,先将页面内数据进行分类对齐至网络安全本体中的知识类型,再将该数据描述转换成结构化的知识表示。另外关系抽取可直接利用页面结构特征,也可通过对网站链接跳转关系,抽取出诸如“Use”“Implement”“Exploit”等知识关系。
不同知识库之间构造的知识关系源自美国国家漏洞库中的专家知识和逻辑语义。例如,FireEye发布的APT28:At the Center of the Storm报告中分析了APT28利用CVE-2015-2590、CVE-2015-3043等漏洞,影响Java、Flash和Windows等应用程序。其分析使用的逻辑关系源自NVD包含的专家知识,如CAPEC-ID(攻击模式)“利用”CWE-ID(弱点)、CVE-ID(漏洞)“属于”CWE-ID(弱点)、CVE-ID(漏洞)“影响”CPE-ID(资产)等逻辑语义。
本文利用Scrapy爬虫框架,基于Xpath抽取表达式进行数据的抽取。在信息抽取部分,对网页进行分类,按照类别构建基于Xpath的数据提取规则,使用提取规则抽取数据。具体抽取流程如表1所示。

图 3 ATT&CK 网站页面
表 1 网页信息抽取流程

(1)实体抽取。对于实体类别的识别,统一资源定位系统(Uniform Resource Locator,URL)是一个较好的区分性特征。例如,软件实体AndroidOS/MalLocker.B的URL是https://attack.mitre.org/software/S0524/,其中https://attack.mitre.org/为ATT&CK网站首页URL,/software/为网页类别,/S0524/为网站为实体设置的编号。网页类别即对应着实体类别。再根据实体详情页抽取出实体属性。不同类型网页存在不同的结构,根据网页类型构造基于Xpath数据抽取规则。抽取图3右面属性框内容,其网页可扩展标记语言(eXtensible Markup Language,XML)部分代码如图4所示。若抽取“ID”属性,构建Xpath查询规则为“//div[@class=”card”]/div[@class=”card-body”]/div[1]/span/text()”;若抽取“ID”属性的属性值“S0524”,构建Xpath查询规则为“//div[@class=”card”]/div[@class=”card-body”]/div[1]/text()”。抽取的内容可能会存在一些符号噪声,可以利用正则表达式对内容进行清洗,最后将抽取出的每个实体名称以及相对应的属性保存并输出。

图 4 示例图 3 中右面属性框对应 XML 部分代码
(2)关系抽取。与实体属性抽取类似,网页中除包含构成实体信息的属性键值对外,部分属性值还包含相应的导航链接信息。如果这些包含链接信息的属性值通过URL分析出另一类实体,则利用预先定义的本体关系规则,将这两个实体关联起来,本体关系规则如表2所示。
表 2 本体关系规则

抽取图3下面“Techniques Used”属性列表内容,其第二行网页XML部分代码如图5所示。根据Xpath抽取规则,能够获取第二行第二列“ID”属性值为“T1402”的标签,其超链接信息为T1402,通过URL分析该链接网页类型为/techniques/,对应的实体类型为攻击技术,再通过页面跳转,获取该实体的具体信息,最后利用预先定义的关系规则抽取出<实体,关系,实体>。

图 5 示例图 3 中下面属性框对应 XML 部分代码
针对网络安全博客、APT相关报告、安全公告等非结构化数据,本文采用实体关系联合抽取方式对其实体间关系进行抽取,采用BiLSTM-CRF网络模型作为基本知识抽取模型,最后对抽取的实体进行融合。
2.3 网络安全知识融合
在知识融合阶段需要对实体进行对齐。攻击组织在不同的厂商分析报告中可能具有不同的名称,如APT19,其常见名称有“Codoso”“C0d0so0”“Codoso Team”等。要先考虑基于实体的唯一属性标识的实体对齐,如漏洞的CVE_id属性、弱点的CWE_id属性等。如果实体没有唯一的属性标识,则需利用基于相似性函数特征匹配来实现对齐。常用的相似性函数包括:(1)基于文本相似性函数的特征匹配,如基于token的相似性函数、基于编辑距离的相似性函数等;(2)基于结构相似性函数的特征匹配,如Adard评分算法、共同邻居计数算法和SimRank算法等。本文采用编辑距离相似性函数和Jaccard相似性算法衡量字符串特征,结合经典的VSM计算上下文的语义特征,综合得出实体相似度。
2.3.1 表示字符串特征的相似度
编辑距离(Edit Distance,ED)是指将一个字符串转化为另一个字符串所需的最少操作数,操作包括插入、修改、删除。具体计算公式如下:

式中: 为两个实体字符串,其长度分别为
为两个实体字符串,其长度分别为 和
和 ;
; 为字符串
为字符串 到
到 之间的编辑距离;
之间的编辑距离; 为其中较大的字符串长度。本文对编辑距离进行归一化处理,即
为其中较大的字符串长度。本文对编辑距离进行归一化处理,即 。式(1)中
。式(1)中 为两个字符串之间的基于编辑距离的相似度,其值越大,表明两个字符串的编辑距离越小,相似度越高。
为两个字符串之间的基于编辑距离的相似度,其值越大,表明两个字符串的编辑距离越小,相似度越高。
Jaccard相似性算法如下:

式中: 为和的交集大小;
为和的交集大小; 为和的并集大小;
为和的并集大小; 为两字符串交集大小与并集大小的比值,其值越大,表明两个字符串的相似度越高。
为两字符串交集大小与并集大小的比值,其值越大,表明两个字符串的相似度越高。
为了使实体对齐结果更加的准确,本文将式(1)和式(2)求平均值得到的 ,作为最终字符串的相似度计算结果,计算公式如下:
,作为最终字符串的相似度计算结果,计算公式如下:

2.3.2 表示语义特征的相似度
仅利用字符串相似度去评价实体相似度会存在很大的误差,本文考虑到实体所处的上下文语义特征,可结合两个实体描述属性中的上下文之间的文本特征计算两个实体的相似度。对于和之间的文本特征,利用VSM进行计算,通过空间上的相似性能够直观易懂地表达语义的相似度。
首先,对两个实体的上下文进行预处理,如分词、符号去除等;其次,利用词袋模型(Bag-of-Words,BoW)将两个实体的文本向量化,并计算两个向量之间的余弦值作为两个实体文本语义相似度,计算公式如下:

式中: ,
, 分别为实体,上下文文本的词向量;
分别为实体,上下文文本的词向量; 为这两个向量的内积;
为这两个向量的内积; 和
和 分别为向量和向量的模;
分别为向量和向量的模; 为,的余弦值,用来表示实体,上下文语义之间的相似度,其值越大,则越相似。
为,的余弦值,用来表示实体,上下文语义之间的相似度,其值越大,则越相似。
本文将上述式(3)和式(4)两种相似度的线性组合作为最终两个实体的相似度,计算公式如下:

式中: 和
和 为可调参数;
为可调参数; 为最终两个实体的相似度计算结果。本文选取2.2节中抽取的攻击者和软件实体数据作为实验数据,一共800条数据。实验结果使用准确度、召回率和F1值进行评估,并与基于文本相似性算法和基于结构相似性算法进行对比,实验结果如表3所示。
为最终两个实体的相似度计算结果。本文选取2.2节中抽取的攻击者和软件实体数据作为实验数据,一共800条数据。实验结果使用准确度、召回率和F1值进行评估,并与基于文本相似性算法和基于结构相似性算法进行对比,实验结果如表3所示。
表 3 实体对齐实验结果

经过实验验证可以看出,本文实体对齐算法优于上述两种类型算法,其准确度为85%,召回率为64%,F1值为73%。将2.2节中抽取出的实体,先基于实体的唯一属性标识进行实体对齐,剩下的利用本文实体对齐算法进行实体对齐,最后总体实体对齐结果如表4所示。
表 4 总体实体对齐结果

2.4 网络安全知识图谱的存储
知识图谱的存储主要是以关系数据库和图数据库两种方式存储。本文使用图数据库Neo4j来存储知识图谱数据。Neo4j能够使用与结构化查询语言(Structured Query Language,SQL)相似的数据库查询语言Cypher语句,对存储的数据进行增删改查等操作;同时Neo4j提供用于查询和展示数据的Web操作界面。本文将融合后的数据转化为csv格式后,通过编写Python脚本将实体、关系、属性数据导入图数据库Neo4j中。构建后的知识图谱包含4 590条实体、13 372条关系,规模统计如表5所示。
表 5 知识图谱规模统计

如图6所示,展示了所构建的网络安全知识图谱部分内容,其中每一个圆形节点代表一个实体,连接两个圆形节点的线代表这两个实体之间的关系,关系通常是有向的。可以看出图谱内容相对复杂,然而,其目的并不是一定要查看整张图,相反,图谱为分析和查询提供了一个丰富的框架。除此之外,Neo4j还能将实体的属性和属性值单独进行存储和展示,如图7所示,展示了恶意软件实体Wiper的属性框图。其中展示了Wiper的创建时间(Created)、ID、最后修改时间(Last Modified)、作用平台(Platforms)、类型(Type)、版本号(Version)、名字(Name)、软件描述(Software_description)等属性及其属性值。

图 6 网络安全知识图谱部分展示

图 7 恶意软件 Wiper 属性框
通过本文构建的知识图谱,安全人员能高效地对网络威胁场景进行分析。利用Neo4j自带的Cypher查询语言,通过路径搜索,能清楚地
看到目标客体遭受攻击的所有路径,包括攻击者所利用的攻击软件和攻击手段等。当示例目标客体 (简称cpe1)受到了攻击时,Cypher查询语言如下文所示,其中限定攻击路径条数展示,最终结果如图8所示。
(简称cpe1)受到了攻击时,Cypher查询语言如下文所示,其中限定攻击路径条数展示,最终结果如图8所示。

从图8可知,攻击者APT32和WIRTE都可以对目标客体cpe1发起攻击。APT32使用(Use)攻击技术Software Deployment Tools(软件部署工具),其中攻击技术与攻击模式CAPEC-187相关联(Same_as),即APT32可以使用攻击模式CAPEC-187。攻击模式CAPEC-187利用(Exploit)弱点CWE-494,其中弱点CWE-494导致(Cause)漏洞CVE-2008-3438的发生,即漏洞CVE-2008-3438属于弱点CWE-494。漏洞CVE-2008-3438存在于(Exist_in)目标客体cpe1中。通过目标客体路径反向搜索,可以得到所有可能的攻击路径,安全人员可根据路径节点有针对性地实施缓解措施,从而保护网络安全。

图 8 攻击路径查询
03 结 语
在网络环境中,存在着大量、多源异构的网络安全数据,为使其合理整合利用,本文借助Neo4j图数据库构建了网络安全知识图谱。首先,本文设计了网络安全本体,并在此基础上,利用Scrapy爬虫框架对多源数据进行采集并抽取出实体、关系和属性;其次,利用相似函数与向量空间模型对实体进行对齐、融合,最终构建出网络安全知识图谱。网络安全知识图谱的构建一方面有利于为安全技术人员提供技术支持,另一方面为后续网络安全应用场景提供参考。
本文针对网络安全实体进行了实体对齐算法研究,实验证明,该方法具有良好的性能,但由于本文抽取出的数据量相对较少,对于更加复杂的应用场景的表现还有待考证,并且算法的可移植性有待进一步提高。因此,今后将针对这些问题做进一步的研究,同时对于网络安全知识图谱自动化构建程度和应用开发等方面有待进一步完善。
引用格式
唐思宇,李赛飞,张丽杰.基于Neo4j的网络安全知识图谱构建分析[J].信息安全与通信保密,2022(8):60-70.
作者简介 >>>
唐思宇,女,硕士研究生, 主 要 研 究 方 向 为 网 络安全;
李赛飞,通讯作者,男,博士,讲师,主要研究方向为网络安全;
张丽杰,女,硕士,主要研究方向为网络安全与信息化。
选自《信息安全与通信保密》2022年第8期(为便于排版,已省去原文参考文献)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
