今天分享的论文主题是检测基于Tor通信的恶意软件。该工作由西蒙弗雷泽大学的Tao Wang等人完成,相关论文发表于网络安全领域顶级会议CCS 2022。洋葱路由(The Onion Router, Tor) 是一种开源的匿名通讯软件,旨在保护隐私,避免用户的私人通信被恶意监听。然而,越来越多的恶意软件利用Tor的匿名通信功能逃避监管,给网络安全带来了极大的威胁。针对上述问题,论文提出了一种流量分析方法,能有效识别基于Tor匿名通信的恶意软件。

【背景介绍】
洋葱路由(The Onion Router, 本文中简称为Tor[1])是目前使用最广泛的开源匿名通信软件,其允许用户通过中继网络访问目的地址,从而达到隐藏用户真实地址、避免网络监控的目标。虽然Tor为互联网用户提供了匿名浏览网站、在线聊天等良好的隐私保护服务,但其匿名通信和流量加密的功能也被各类恶意软件所利用,如与命令和控制(Command and Control, C&C)服务器进行通信、获取赎金软件的支付页面等等,大幅度提高了检测和识别恶意软件的难度。
由于Tor路由的IP地址是对外公开发布的,一种可能的恶意软件检测方式是直接阻断与这些IP相关的网络连接。然而,无论对于个人还是企业,许多合法场景也会用到Tor,基于“黑名单”的阻断方式并不可取。此外,如果受感染的主机和它们的C&C服务器或目的主机之间使用了Tor路由,已有的基于目的地IP地址、端口或深度包检测(DPI)的传统恶意软件检测技术均难以起到良好的识别效果。因为受感染主机在网络日志中记录的不再是直接连接到C&C服务器,而是连接多个Tor路由。从日志层面来看,其与未被感染的主机是很难区分开的。
研究基于Tor的恶意软件检测方法并非易事:首先是相关数据集难以获取的问题;其次,算法需要具备区分良性和恶意加密Tor连接的能力,避免影响合法用户对Tor的使用。
【研究方法】
文章首先对实际应用中的网络日志数据进行了分析。数据集为2018年5月至2019年2月的某企业的BRO/Zeek日志(DNS、HTTP、SSL等),包含超过600百万条TCP,UDP和ICMP的连接记录和超过170百万条的DNS日志数据。经过分析,文章发现有7个洋葱域名(Tor内使用的域名)被WannaCry等远控木马高频访问,这些域名被硬编码在恶意软件中。这启发我们,洋葱域名的访问可能与恶意软件相关,即恶意软件会试图首先通过Tor连接到它的C&C机器。
因此,文章期望以网络流量及网络日志为基础,识别基于匿名通信的恶意软件。流量分析也面临着一些挑战,如Tor会在网络内解析DNS导致无法利用DNS信息、Tor会多流复用、流量的频率特征不明显以及在网络端检测无法利用主机日志信息。
步骤1:数据集构建
恶意流量:作者首先在VirusTotal[2]上根据 tor, onion, torrc 等关键词搜索、下载样本,随后根据样本产生的流量信息判断是否为Tor应用,并根据VirusTotal提供的恶意值来判断Tor应用是否恶意;随后使用Falcon沙箱运行样本产生流量,每个样本提交到该沙箱中60次,每次运行6分钟。通过这种方式,作者共收集了523个恶意软件样本,并验证了其中362个是活跃的。运行这362个活跃恶意软件获得了5985个pcap包,共计30,592个Tor连接。
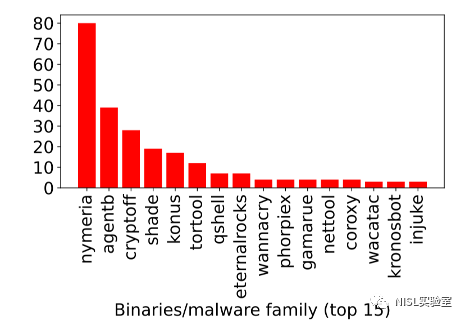
图表1: 恶意样本的数量前15的恶意家族
文章利用AVclass[3]和AVclass2[4]自动恶意软件标签工具将二进制样本归类为恶意软件家族和类别。家族标签是安全公司用来识别特定恶意软件威胁的通用名称。类别标签是定义恶意软件类型的通用标签,如蠕虫、特洛伊木马、黑客工具、勒索软件等。
上述流量被进一步组成四个实验数据集,每个数据集表示为DN,其中N是每个恶意样本随机选择的pcap包的数量。随着N数值的增大,不同恶意软件的数量也会减少。例如,D5数据集由157个恶意软件产生的流量组成,每个样本有5个pcap文件,而D10数据集由130个恶意软件产生的流量组成,每个样本有10个pcap文件。

图表2:恶意样本的类别
良性流量:分为两部分,一部分是通过模拟浏览器访问采集得到,作者模拟三种用户操作频率来分别访问Alexa Top(访问频率排名)域名和非Top域名,其中低操作频率的访问占38%,中等频率占40%,频繁操作的访问占22%。通过这种方式得到了4,585个pcap文件,其中top域名有3,540个pcap。另一部分良性流量是来自公开数据集ISCXTor2016[5],该数据集包含来自facebook等超18种代表性应用程序的浏览、聊天等8种类型的流量。最终,作者共收集了32,275个良性Tor连接。
步骤2:检测方法
作者分析发现,良性和恶意Tor流量之间的差异来自于(1)服务器流量指纹(模式、突发性、连接寿命、频率等)和(2)客户端的异常情况。因此,本文采取特征工程的方法,从上述两个层面提取流量特征进行检测。
1. 流级别的特征,本文主要采用的是USENIX Security 2016中Hayes等人[6]提出的150维网络指纹特征,包括Tor连接中的时间、方向、顺序和包的密集程度等特征信息。作者为每个pcap文件的前三个活跃的Tor连接提取以上网络指纹特征,这是由于Tor客户端通常会选择三个入口节点建立TLS连接,并在这连接中进行多路复用。
2. 主机级别的特征,文章提取了40维特征如图表3所示,其中有22个特征是针对Tor的,如每个pcap中的Tor连接数、失败连接尝试数等。这些特征可以显示出客户端的异常情况。
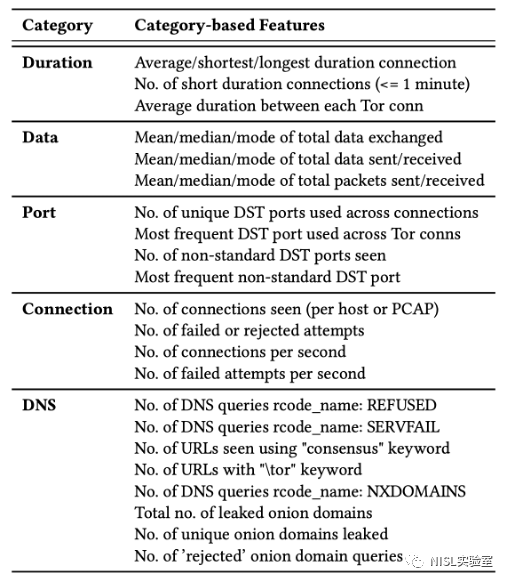
图表3:每个pcap的所有Tor连接提取主机级特征
【实验验证】
文章首先在四个实验数据集中验证所提出的算法的恶意软件检测能力,将70%的数据用于训练,30%的数据用于测试。在实验中记录准确率(Precision),召回率(Recall)、误报率(False Positive Rate,FPR)。

图表4:不同数据集下的性能比较
图表4记录了检测结果,从表中可以发现通过增加恶意样本产生流量文件的数量,可以提高召回率和准确率,而误报率也随之增加。
考虑到D5数据集包含最多数量的恶意软件,并且误报率最低、AUC最高,具有很强的恶意软件区分能力,文章选用D5数据集进行进一步的实验验证,验证检测算法受特征种类的影响、恶意软件多分类效果、检测未知恶意软件能力及仅使用网络日志的场景下的检测效果。

图表5:使用不同模型和特征集合的恶意软件分类效果
实验结果发现:
○ 主机级别的特征能够起到更好的分类效果,流级别的特征中能起到重要效果的是传入传出流量占比等统计信息;
○ 在多分类实验中,检测算法可以达到68.12%准确率和72.37%召回率,可以根据恶意软件的行为来推断其家族和类别;
○ 算法可以0.7%的误报率检测此前从未见过的恶意软件,即使这些恶意软件产生的流量在测试集中占比不到5%;
○ 在真实的企业网络日志数据集上进行了实验测试,仅使用网络日志而不用全流量的情况下,恶意流量的识别精度可以达到93.3%。
【结论】
文章首先收集了基于Tor通信的恶意软件,随后采集并分析这些恶意软件产生的流量,发现了从流量维度区分良性和恶意Tor流量的可行性。因此,作者构建了一个包含数百个经过验证的基于Tor通信的恶意软件库;随后设计了支持识别不同恶意软件的分类器(如勒索软件、蠕虫病毒、木马病毒等);最后,在真实的企业网络日志数据集上进行了实验测试,恶意流量的识别精度可以达到93.3%。
【个人观点】
文章除了传统的流量层面的特征,还利用了Tor特有的通信特征,这种针对具体问题具体分析的方式值得我们学习借鉴。文章使用的数据集均由人工分析得到,数量虽不是特别多,但人工验证数据的结果较为准确。本文使用的方法也较简单容易实现。不过实验设置稍有些简单,也缺少了一些对比实验和分析(例如缺少baseline作为对照)。
原文链接
https://alrawi.io/static/papers/tor-malware_ccs22.pdf
参考文献
[1] Roger Dingledine, Nick Mathewson, and Paul Syverson. 2004. Tor: The Second-Generation Onion Router. In 13th USENIX Security Symposium (USENIX Security 04). USENIX Association, San Diego, CA. https://www.usenix.org/conference/13th-usenix-security-symposium/tor-second-generation-onion-router
[2] VirusTotal. https://www.virustotal.com/gui/home/upload
[3] Marcos Sebastián, Richard Rivera, Platon Kotzias, and Juan Caballero. 2016. AVclass: A Tool for Massive Malware Labeling, Vol. 9854. 230–253. https://doi.org/10.1007/978-3-319-45719-2_11
[4] Silvia Sebastián and Juan Caballero. 2020. AVclass2: Massive Malware Tag Extraction from AV Labels. In Annual Computer Security Applications Conference (Austin, USA) (ACSAC ’20). Association for Computing Machinery, New York, NY, USA, 42–53. https://doi.org/10.1145/3427228.3427261
[5] Tor-nonTor Dataset (ISCXTor2016). https://www.unb.ca/cic/datasets/tor.html
[6] Jamie Hayes and George Danezis. 2016. k-fingerprinting: A Robust Scalable Website Fingerprinting Technique. In 25th USENIX Security Symposium (USENIX Security 16). 1187–1203.
付卓群,编辑&审校|刘保君、张镇睿、张一铭
声明:本文来自NISL实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
