在AI安全行业有影响力的MLSEC 2022(机器学习安全规避竞赛 ) 中,参赛者成功地修改了名人照片,目的是让他们被识别为不同的人,同时尽量减少对原始图像的明显更改。
MLSEC 2022于今年8月12日至9月23日举行,由Adversa AI、CUJO AI和Robust Intelligence组织。MLSEC竞争始于2019年,今年是第四届。本届挑战赛的主要变化是:放弃了恶意软件二进制攻防赛道;继续开展网络钓鱼攻击赛道,但难度有所增加;添加了人脸识别赛道。参赛者攻击了人工智能面部识别和人工智能钓鱼检测系统。参赛者试图以不同的方式愚弄人工智能模型,并展示了人工智能算法的弱点。两个AI受害者系统都被证明容易受到规避攻击。这再次提醒人们,大多数人工智能算法在设计上都是不安全的,需要付出额外的努力来保护它们免受对抗性攻击。
这场比赛还表明,传统的网络安全无法应对AI漏洞的影响——AI模型的安全是一个独特的领域,应该在AI/ML负责关键任务或关键业务决策的组织中实现。这绝不仅仅是面部识别的问题——反欺诈、垃圾邮件过滤、内容审核、自动驾驶,甚至医疗AI应用都可以通过类似的方式绕过。

人脸识别AI黑客大赛规则
针对人脸识别的攻击挑战是由Adversa AI的首席技术官兼联合创始人ugene Neelou领导的Adversa AI Red Team准备的。攻击的目的是修改一些名人的照片,使其在看起来与原始图像相似的同时被识别为不同的身份。Eugene Neelou坦言,设计这场比赛是为了提高人们对人工智能算法漏洞的认识。尽管挑战提供了绕过AI面部识别的方法,但这只是为了简化视觉演示。事实上,大多数类型的人工智能系统在设计上都很脆弱,可能会以各种意想不到的方式被黑客入侵。
主办方Adversa.ai准备了十张名人面孔的图像。目标是修改原始图像,使新图像能够被ML模型识别为另外的名人。这意味着要为其他九位名人修改十张图像,总共90张图像。评价规则则设计了两个指标,“置信度”(confidence)和“隐匿性”(Stealthiness )。置信度显示了对抗性图像被j归并到目标类别的概率。隐匿性显示了对抗图像与源图像的结构相似性。今年,只有置信度分数进入记分牌,隐匿性指标仅供参考。

这是用于被攻击的名人脸部图片
规则也比较清晰,比如让模型预测Brad Pitt的防护乳方法就是简单地发送一张Brad Pitt的照片。显然规则不允许这样做,因为挑战还要跟踪“隐匿性”分数,该分数判断参赛者提交的图像与原始图像的差异程度。所有图像都必须获得50%或更高的隐逆性分数才能使攻击真正有效。如果选手发送完全不同的图像,那么其的隐匿性得分始终为 0。
人脸识别AI黑客大赛成果
1、一等奖成果:面部粘贴攻击
一等将的获胜者Alexander Meinke设计了一种基于面部粘贴和混合原始照片与受害者照片的策略。Alexander首先将受害者身份照片的一部分粘贴到原始身份证照片中。AI识别系统起初不接受它,但通过额外的优化,Alexande解决了问题。
虽然AI攻击成功了,但Alexander仍在与其他人竞争。他需要优化他的指标并花费数小时才能使他的总分额外增加0.0005%(置信度从99.9976%提高到99.9981%)。
Alexander表示,他整合了一种名为Square Attack的现有黑盒方法,该方法在某些黑盒攻击任务中表现出色。这种攻击获得了一些关于允许修改每个像素的空间,然后开始修改该空间内的方形区域。提供较大的空间会大大降低隐匿性,而提供较小的空间不会提高置信度,但有一个最佳点,他获得了以下图像。“0.0005%的改善真的值得花几个小时在这上面吗?Alexander认为这一小小的改进是值得的。

Alexander以89.999912分(满分90分)的近乎完美的置信度得分和54.267957分的隐匿性得分获得第一名,并获得了3,000美元的奖金。
2、二等将成果:混合对抗样本攻击
来自上海科技大学和新加坡管理大学随便玩玩团队团队获得了第二名。与第一名不同,他们立即从对抗样本开始。团队的赵哲表示:本质上,比赛是对人脸识别神经网络的黑盒对抗攻击。所以他们使用的主要算法是基于模型集成BIM或PGD攻击。在这个基线算法上,他们针对这次攻击做了几处优化。赵的团队详细介绍 了他们如何从基本的对抗性示例开始并添加了几个攻击优化层。
他们最终对可转移的对抗样本进行了相当高级的优化。这种转移攻击通过其本地代理模型启用了本地攻击利用。这是一种攻击AI系统的出色策略,因为它更难被发现。
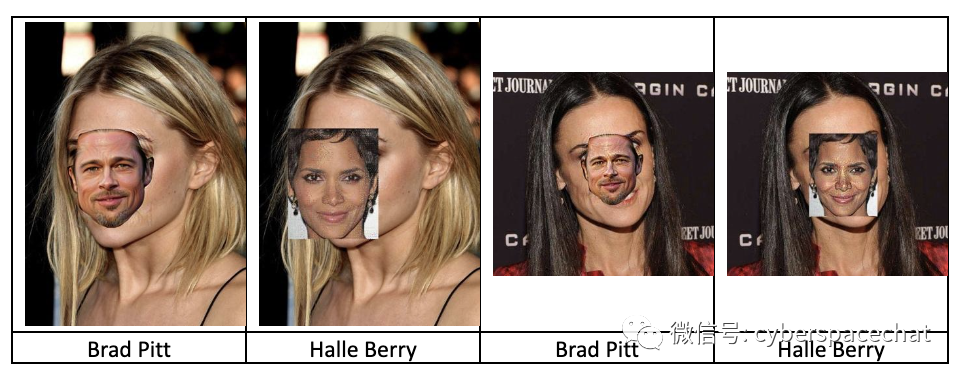
随便玩玩团队以89.999494(满分90 )的第二高置信度得分和48.719501的隐匿性得分获得第二名,并获得了1,500美元的奖金。
3、最硬核成果:最独特的对抗技术组合
Jérôme Rony介绍了最独特的对抗技术组合。他也是唯一一个没有尝试将两幅图像合二为一的参赛者。Jérôme的算法包含的方法涵盖了他在对抗性机器学习方面的多篇论文中的前沿研究成果。
该策略基于使用本地代理模型来创建可转移到黑盒竞争模型的可靠AI攻击。让转移工作顺利的是,在对代理模型的每次攻击迭代中,他都对一堆补丁进行了采样,并对它们的置信度约束进行了平均。这样一来,无论检测器提取图像中的哪个补丁,都将是对抗性的。

仅通过几百次请求,Jérôme就获得了89.984533分(满分90分)和所有参赛者中最高的隐匿性得分-61.053852 。后来他试图最大化主要指标,但意识到如果不重新设计攻击算法,进一步优化是不可行的,所以他只获得了第四名,但获得了Adversa AI Red Team的荣誉奖。
4、最具科学性成果:智能AI愚弄贴脸攻击
尽管科学家Niklas Bunzel和Lukas Graner不依赖于对抗性示例,但他们设计了一种在他们的论文中记录的最节省资源的算法。
在他们的策略中,他们将目标的面孔粘贴到源图像中。通过利用手动和自动屏蔽的位置、缩放、旋转和透明度属性,该方法每次攻击需要大约200个请求以获得最终最高分,并且至少需要大约7.7个请求才能成功攻击。

通过选择两种方法的最佳结果,他们获得了89.998329的置信度得分和57.685751的隐匿性得分,获得第三。
5、创意成果奖:对抗性面部交换攻击
与其他参赛者不同,Ryan Reeves利用比赛来释放他的创造力。比赛前,他一直在研究自己的换脸算法。Ryan尝试使用他的方法,但由于供攻击的算法模型的对抗性强化,它并不有效。
然后,Ryan找到了一个更好的算法,叫 SimSwap。他已经从谷歌图像中抓取了数百张名人头像,并在这些图像上进行了迭代,选择了置信度最高的照片。然后,他通过将原始图像与换脸图像混合来优化置信度。令人惊讶的是,他设法通过强行调整图像尺寸来提高隐匿性,这将大幅波动置信度分数,有时将其从最初的0.50左右提高到0.99或更高。

凭借这种创造性的方法,Ryan获得了89.029803的置信度得分和52.793099的隐匿性分数,获得第六名。
比赛总结
正如最终指标所示,最有效的策略涉及对面部识别AI算法的对抗性攻击,与更常见的深度造假和演示攻击相比,该算法具有最佳的总体结果(隐匿性和效率的结合),并且不易被检测和缓解. 此外,Rony的对抗样本表现出最好的隐匿性,这是现实世界中成功攻击的关键特征之一。
因为很少有机器学习模型和AI系统的开发人员关注对抗性攻击和使用红队测试他们的设计,找到导致AI/ML系统失败的方法是相当容易的。MITRE、微软和其他组织敦促企业更认真地对待对抗性人工智能攻击的威胁,通过人工智能系统对抗性威胁景观(ATLAS)知识库描述了当前的攻击,并指出对人工智能的研究——通常没有任何健壮性或安全性设计——正在/必然迅速增长。不了解机器学习背后数学原理的非专业人士往往认为,系统理解其运行的环境和世界。然而对于这样的模型来说,它们的“世界”只包括训练它们的数据,因此在其他方面它们缺乏背景。创建能够在异常情况或恶意攻击面前正确行动的AI系统,需要考虑到各种问题的威胁建模。
Eugene Neelou总结认为,这场比赛表明人工智能算法在设计上是脆弱的。许多科技公司正在成为人工智能公司,它们依赖于第三方或开源模型和数据集。他们通常不审计甚至不能强化这些神经网络。这必将危及这些公司的AI产品安全和用户安全。 为了解决人工智能安全风险,公司需要重新考虑安全模型开发工作流程。
首先,他们应该提高AI产品和安全团队对常见AI网络威胁、相关AI应用程序中的漏洞以及后果严重性的安全意识。
其次,他们应该在发布支持AI的产品之前进行对抗性测试和AI红队测试,以了解其 AI模型的真实安全级别。正如黑客所证明的那样,有很多方法可以成功地进行AI攻击。因此,公司应特别注意并聘请领域专家来解决安全人工智能风险。这包括针对对抗性攻击的AI算法验证,白宫的AI权利法案强调了这一点,Gartner和CBInsight将其列为 2023年及以后的顶级技术趋势。
第三,他们应该实施安全的AI生命周期,从安全数据工程和处理到安全模型开发及强化,再到威胁检测和响应。
保护模型的最佳且唯一方法是在管道的不同阶段使用组合控件。在训练和推理过程中有多种防御技术,例如对抗性再训练、输入修改、攻击检测等方法。保护阶段越早,保护效果越好。这也正是安全控制左移的关键之所在。
参考资源
1、https://adversa.ai/ai-hacking-competition-results-and-review-by-organizers/
2、https://cujo.com/mlsec-2022-the-winners-and-some-closing-comments/
3、https://github.com/persistz/2022-machine-learning-security-evasion-competition/blob/main/biometric/write-up.md
4、https://www.darkreading.com/vulnerabilities-threats/adversarial-ai-attacks-highlight-fundamental-security-issues
5、https://www.alexmeinke.de/2022/10/09/adversarial-attacks.html
声明:本文来自网空闲话,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
