今天分享的论文主题是面向语法的灰盒模糊测试,由来自德国波鸿大学和达姆施塔特工业大学的研究人员完成。模糊测试是一种热门的自动化进行程序漏洞测试的方法,近年来,为了涵盖各类待测试的方法和目标,研究人员针对不同的应用场景,设计了多种模糊测试方案。然而,现有的模糊测试方案主要依赖低级的二进制转换以生成新的输入,对仅接受高度结构化输入的程序(如,脚本语言解释器等)而言,效果较差。因此,该论文首次尝试使用语法解决上述问题,并实现了首个结合基于语法进行输入生成和基于反馈引导的模糊测试工具 NAUTILUS。该工具涵盖了多种基于语法的变异策略、最小化策略和生成策略,能够生成在语法和语义上均正确的输入,其表现优于现有的模糊测试工具,并在多个广泛使用的软件项目中发现了数个安全漏洞。论文发表于网络安全顶级学术会议 NDSS 2019(录取率:17.1%)。

全文共3800字,阅读时间约10分钟。
01
【背景介绍】
模糊测试(Fuzzing)是一种自动化的漏洞挖掘技术,基于生成输入的方式可以将模糊测试工具分为两类:基于变异的模糊测试和基于生成的模糊测试方法。
基于变异的模糊测试
受生物遗传学启发,基于变异的模糊测试方法使用比特翻转(bit flips)、输入重组(splicing)等方法,对初始种子构成的输入语料库进行修改,以得到新的模糊测试输入。这些修改的操作可以是随机的,也可以是启发式引导的,更高级的修改方法可能涉及浮点分析、符号执行等。其中,AFL 是一种热门的基于变异和启发式方法引导的模糊测试工具,AFL 使用程序基本块之间的转移路径(边)的覆盖情况,作为引导变异的启发式方法 [2]。
基于生成的模糊测试
基于生成的模糊测试方法会根据给定的模型或语法规范生成输入,比如,可以根据某个语言解释器所支持的编程语言的语法规则,生成符合其语法的输入。虽然,这种方法能够通过程序中复杂的输入处理过程,但很难绕过严格的语义检查。此外,许多基于生成的模糊测试工具不仅需要语法规则,还需要一个初始的语料库(corpus)。由于合法的输入和非法的输入重新组合后,往往能够产生合法且能够触发崩溃的输入,因此理想情况下的语料库应该同时包含这两类输入,也正因为需要同时包含合法和非法的输入,创建这样理想的语料库是非常困难的。
无论是基于变异的还是基于生成的模糊测试方法,都需要产生提供给程序运行的输入。而程序的输入往往是高度结构化的,传统的基于变异的模糊测试方法很难提供结构化的指导。针对高度结构化的输入,上下文无关文法(Context-Free Grammars, CFG)非常适合对其进行描述。直观地说,CFG 是一组形式为“一些变量 X(非终结符)可以被一系列字符串(终结符)或变量替换”的规则,一个特殊的“开始变量”指定了应用这些规则的起点。CFG 描述的输入语言是所有字符串的集合,这些字符串从“开始变量”开始,通过应用任意数量的“产生式规则”派生新的字符串、变量组合,直到不再存在非终结符时结束。

图表 1:一组合法的 CFG 产生式规则示例
图表 1 展示了一组合法的 CFG 产生式规则。具体来说,指定 PROG 为开始变量,那么该 CFG 规则可以按照图表 2 所示的过程派生出 a = 1 这一字符串。并且,由 CFG 生成的字符串都可以用一颗 CFG 树进行表示,如图表 3 所示。论文提出的模糊测试工具,NAUTILUS,就是基于这一棵 CFG 树设计了生成策略、最小化策略和变异策略的方法。
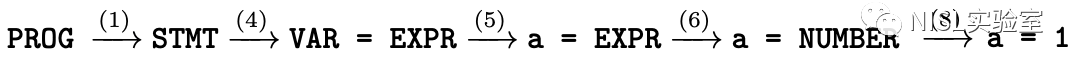
图表 2:a = 1 的派生过程示例
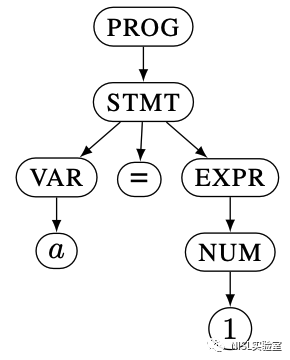
图表 3:a = 1 的 CFG 树示例
根据模糊测试工具的目标,即最大限度减少用户所需的工作量,并最大限度地提高模糊测试工具的效果,论文首先总结了设计基于语法的模糊测试工具所面临的挑战,主要包括以下四个方面:
挑战一:生成在语法和语义上均合法的输入
具体来说,生成的输入需要通过目标程序的语法和语义检查,才能够进入下一个执行阶段。而符合语法和语义的输入只占所有输入的很小一部分。因此模糊测试工具往往很难执行深层次的代码,难以发现在输入验证保护下的逻辑错误。此外在很多情况下,输入语言不能通过 CFG 进行建模。
挑战二:脱离语料库进行模糊测试
已有的模糊测试工具通常需要一个初始的输入语料库,即一组种子文件。但是在很多情况下,构建一个能够很好地覆盖程序所有部分的初始语料库是非常困难的。
挑战三:达成被测目标的高覆盖率
覆盖率指的是,已经触发的代码数占总代码数的比率。覆盖率越高,就意味着可能发现的漏洞数量越多。
挑战四:拥有较好的性能表现
单位时间测试输入的数量是衡量模糊测试工具有效性的主要指标之一。为了保证较高的执行频率,输入长度需要相对较小,同时生成输入的方法需要相对较快。
02
【NAUTILUS】
针对上述挑战,论文设计了基于语法的灰盒模糊测试工具,NAUTILUS,图表 4 展示了 NAUTILUS 工具的总体架构,其架构与 AFL 相似,主要的创新点在以下四个部分:1)输入生成;2)最小化;3)变异;4)由 CFG 树转换为二进制文件的反解析过程。
针对之前所说的四个挑战,NAUTILUS 也都有针对性地设计以解决挑战。具体来说,NAUTILUS 仅依赖语法的输入派生方法可以解决挑战一和挑战二;使用反馈引导的输入生成方法和变异方法可以解决挑战三;最后,通过控制输入派生长度并最小化输入可以解决挑战四。
我们将在下文中详细介绍 NAUTILUS 中的四个主要创新部分。
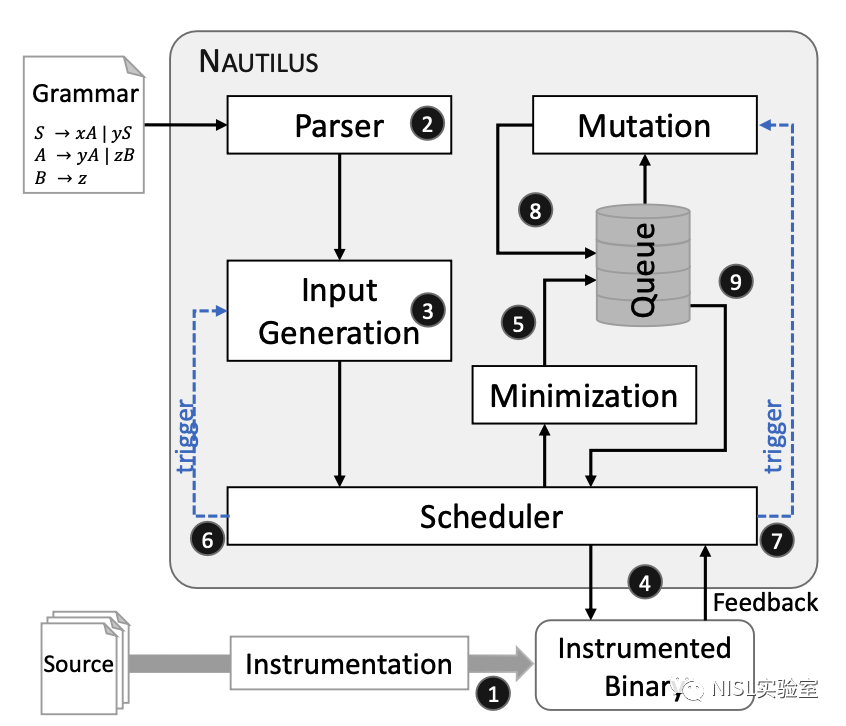
图表 4:NAUTILUS 的总体架构
Step I:输入生成
论文主要提出了两种输入生成策略:1)Naive Generation,即随机地对一个非终结符选择一个应用规则。这种策略会生成许多重复的输入,为了解决重复度高的问题,论文通过使用过滤器来检查新生成的输入是否已经被生成,从而避免重复执行;2)Uniform Generation,采用由 McKenzie 提出的方法 [3],平均地选取所有可能方案,避免了由语法结构引入的偏见。
Step II:最小化
为了最小化 Step I 生成的输入,以提高模糊测试效率,论文提出了两种策略:1)子树最小化(Subtree Minimization);2)递归最小化(Recursive Minimization)。
子树最小化策略的目标是在保证能够触发新路径的前提下,让各个子树尽可能短。如图表 5 所示,子树最小化策略通过生成每个节点的最小子树,并将其替换到该节点上,测试替换后是否触发了新路径,如果是的话则使用替换后的 CFG 树代替原始的 CFG 树,完成最小化过程。
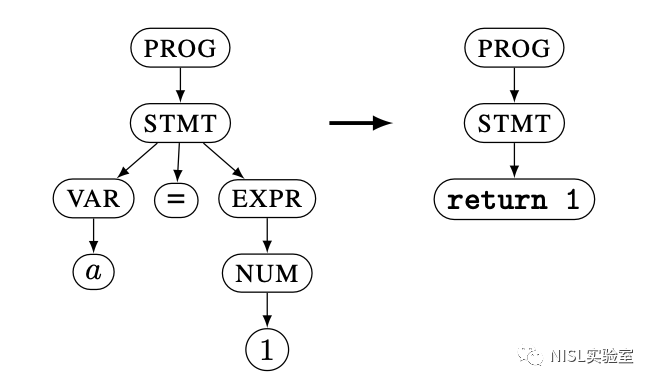
图表 5:子树最小化策略示例
递归最小化策略在子树最小化策略完成之后执行,目的是为了减少递归的层数。如图表 6 所示,递归最小化选择一个和父节点相同的节点,替换父节点子树为当前子树。
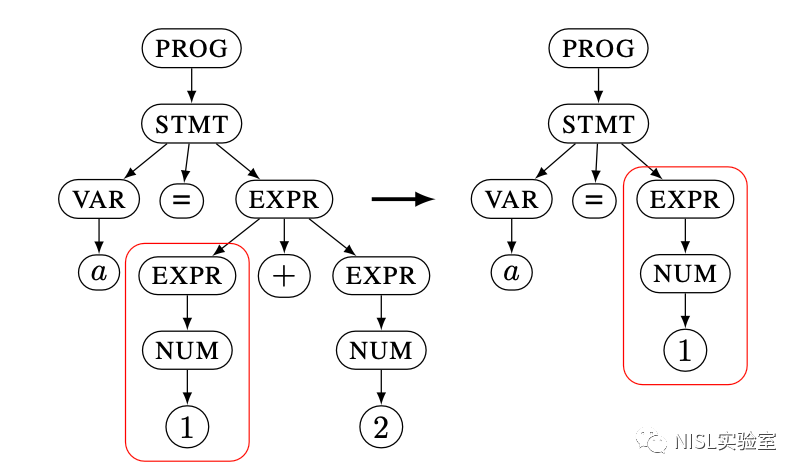
图表 6:递归最小化策略示例
Step III:变异
基于生成的输入,为了进行变异,论文提出了四种针对 CFG 树的变异策略,并复用了 AFL 中提出的部分变异策略,我们在下文中逐一进行说明。
随机变异(Random Mutation),随机地选择一个节点,将其替换为使用相同的非终结符规则生成的新子树;
规则变异(Rules Mutation),依照顺序枚举每个节点,用所有其他可能应用的规则生成的子树替换以这个节点为根的子树,这个变异策略类似 AFL 中的确定性变异阶段;
随机递归变异(Random Recursive Mutation),如图表 7 所示,随机地选择一个具有递归性质的子树,将其重复 2^n 次,这个变异策略可以创建嵌套程度更高的树;
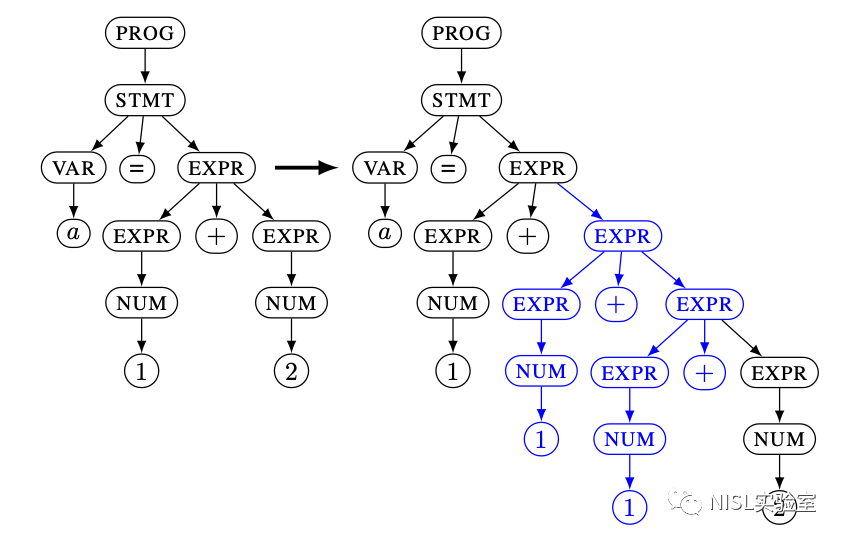
图表 7:随机递归变异示例
AFL 变异(AFL Mutation),即复用 AFL 中的比特翻转(Bit Flips)、算数变异(Arithmetic Mutations)和兴趣值替换(Interesting Values)策略。进行 AFL 变异时,首先会将子树转换为文本形式,然后执行这三种变异策略,最后由于变异后可能已经不满足语法要求,需要将新生成的文本存储为一个新的“自定义规则(Custom Rule)”,该规则不存储至全局语法规则,而是和 CFG 树一同存储。如图表 8 所示,在 EXPR 上应用 AFL 变异策略后, 1 + 2 被修改为 1xf,此时已不满足语法规则,则添加一个“自定义规则” EXPR → "1xf"。AFL 变异可以产生一些不合法的输入,从而能够尝试发现解析器中的漏洞。
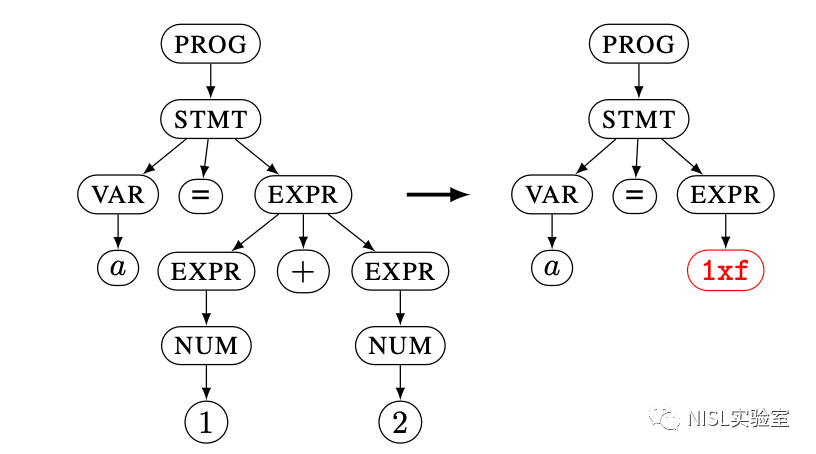
图表 8:AFL 变异示例
Step IV:反解析
最后,为了将变异得到的 CFG 树转换为文本形式,需要进行反解析(unparse)。对于真正的 CFG 而言,无需特别的处理即可将树型结构直接转换为文本。但现实环境中许多输入的语法并不是上下文无关的。因此,作者设计并实现了反解析自定义脚本功能,能够实现如 XML 此类非 CFG 语言的上下文相关的反解析过程。
03
【效果评估】
为了全面地评估 NAUTILUS 的效果,作者围绕六个主要的问题设计了实验以进行效果评估,我们将在下文中进行详细说明。
RQ1:NAUTILUS 是否能够在现实应用程序中发现新的漏洞?
论文针对图表 9 中的四个目标程序进行了模糊测试,结果都发现了新的漏洞,而其他的模糊测试工具并未在评估期间发现这些漏洞。其中,在 mruby 中发现的漏洞分配了 6 个 CVE 编号。

图表 9:NAUTILUS 在四个目标程序测试中找到的漏洞
RQ2:NAUTILUS 是否比主流的模糊测试工具更高效?
为了衡量不同模糊测试工具测试同一程序的代码覆盖程度,作者计算了分支覆盖率,即在模糊测试过程中至少执行了一次的分支占全部分支的百分比。作者主要对比了基于反馈的模糊测试工具 AFL [2] 和基于语法的模糊测试工具 IFuzzer [4]。从图表 10 的结果中,可以看出 NAUTILUS 在分支覆盖率上占据了绝对优势。
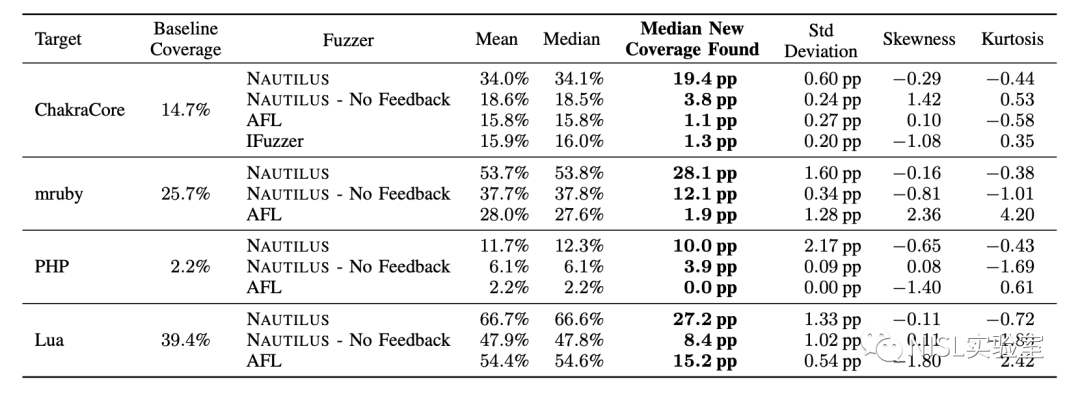
图表 10:NAUTILUS 与其他模糊测试工具的对比结果
RQ3:对于具有高度结构化输入的目标程序,语法的使用在多大程度上提高了模糊测试的效率?
RQ4:使用语法做指导时,反馈机制对模糊测试的性能提升有多大?
对于以上两个研究问题,作者通过关闭 NAUTILUS 中的反馈功能,在同样的环境下进行测试,得到的测试结果在图表9中标记为“No Feedback” 。通过将 AFL 和 “No Feedback” 结果进行比较,以及将“No Feedback” 和 NAUTILUS 结果进行比较,可以分别得出语法的使用和反馈机制的使用很大程度上提高了模糊测试的性能。
RQ5:文章提出的复杂的、相较简单方法需要更多的计算能力的生成方法,对模糊测试的性能提高了多少?
作者分别使用 Naive Generation 和 Uniform Generation 两种方法进行了测试,得到的结果显示在图表 11 中。可以发现两种方法的效果相当,启用 Uniform Generation 不但不能提高模糊测试的效果,反而还增加了执行的复杂程度,因此实际运行采用 Naive Generation 方法即可。
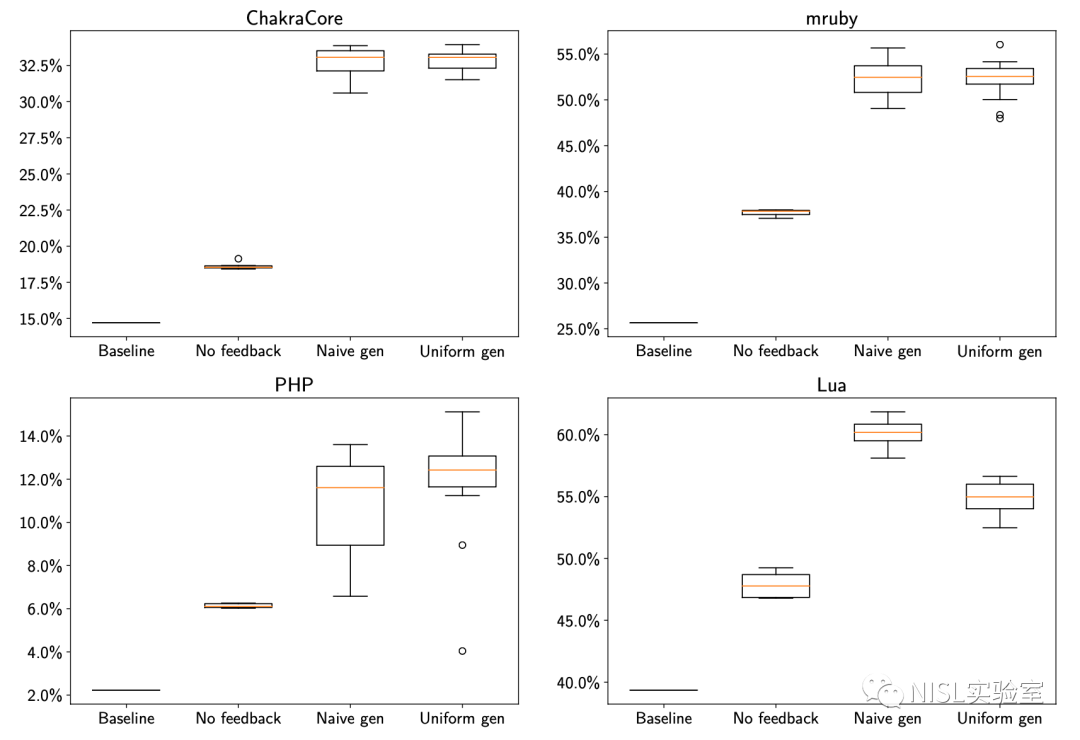
图表 11:NAUTILUS 在不同配置下的分支覆盖率
RQ6:每种变异策略对寻找新路径的贡献有多大?
为了回答这个问题,作者使用一个计数器记录每种变异策略、最小化策略和生成策略触发新路径的次数。根据图表 12 和 13 中的结果,可以发现生成和最小化策略在最开始触发了较多的新路径,但在几个小时之后随机变异和拼接变异触发了超过一半的新路径。随机递归变异策略虽然比其他方法触发的新路径更少,但据作者描述随机递归变异策略发现了数个其他变异策略未发现的漏洞。
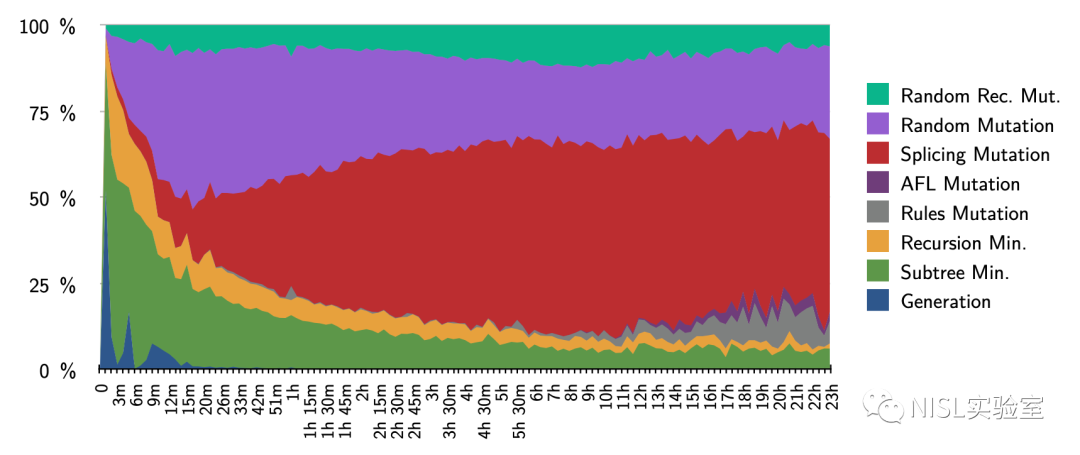
图表 12:每种生成/变异策略在各执行时间点触发新路径的百分比
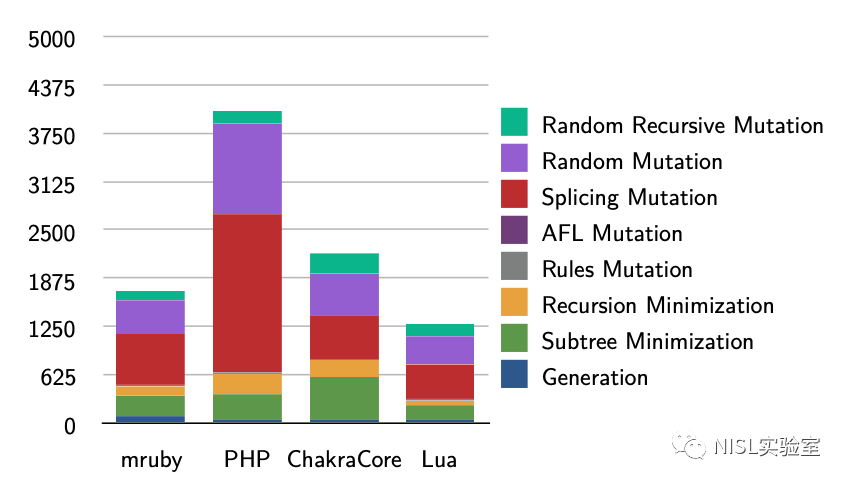
图表 13:每种生成/变异策略在四个目标程序测试中产生的触发新路径的输入数量
04
【总结与思考】
总结
该论文首次尝试将语法应用于模糊测试中,实现了基于语法进行输入生成和基于反馈引导的模糊测试工具 NAUTILUS。NAUTILUS 在模糊测试过程中应用了 CFG 树,其总体架构与 AFL 相似,但是去除了对初始种子的依赖,在输入生成、最小化、变异和由 CFG 树转换为二进制文件的反解析这四个过程进行了创新。在对作者选取的四个目标程序的测试过程中,NAUTILUS 表现最优,并发现了数个新的安全漏洞,其中有 6 个漏洞分配了 CVE 编号,证明了语法指导模糊测试过程的有效性。
思考与展望
作者在论文的末尾总结了未来的工作方向,我们也从中进行了一些思考和展望,具体包括以下几个方面:
1.首先,论文提出的模糊测试方案中覆盖引导是基于编译时插桩实现的,这种方法仅适用于能够获取源代码的程序。针对无法获取到源代码的二进制程序,可以通过应用 AFL++ 中的 QEMU、Frida 等模式,实现对二进制的动态插桩,从而对二进制程序运用本文提出的进行基于语法的模糊测试;
2.NAUTILUS 依赖人工给定语法执行,对于部分程序,特别是无法获取到源代码的闭源程序来说,人工提取语法规则工作量较大。对此,可以考虑集成自动化语法推断功能 [5];
3.可以对 NAUTILUS 进行扩展,以实现对更多上下文相关文法语言的支持;
4.最后,可以开发其他更好的生成策略,比如在生成输入尽可能地生成当前种子库还未覆盖到的输入空间,以最大化漏洞发现的可能性。
原文链接
https://react-h2020.eu/m/filer_public/cf/1e/cf1e4089-3103-4038-9b69-783d8a021a1a/ndss19-nautilus.pdf
NAUTILUS的开源链接
论文版本:https://github.com/RUB-SysSec/nautilus
维护版本:https://github.com/nautilus-fuzz/nautilus
参考文献
[1] Aschermann, Cornelius, et al. "NAUTILUS: Fishing for Deep Bugs with Grammars." NDSS. 2019.
[2] Technical "whitepaper" for afl-fuzz [online]. http://lcamtuf. coredump.cx/afl/technical_details.txt. Accessed: 2018-06- 12.
[3] Bruce McKenzie. Generating strings at random from a context free grammar. 1997.
[4] Spandan Veggalam, Sanjay Rawat, Istvan Haller, and Herbert Bos. Ifuzzer: An evolutionary interpreter fuzzer using genetic programming. In European Symposium on Research in Computer Security, pages 581– 601. Springer, 2016.
[5] Matthias Höschele and Andreas Zeller. Mining input grammars from dynamic taints. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, 2016.
穆柯燃,编辑&审校|刘明烜、张一铭
声明:本文来自NISL实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
