 新智元报道
新智元报道
编辑:好困 David
你绝对想不到,自己在家上厕所的「实时动态」,不仅被拿去给AI做了训练数据,而且还被发到了网上!
最近,《麻省理工科技评论》在一篇万字长文调查中,就曝光了这样触目惊心的一幕——
图中,一位女士穿着淡紫色T恤的年轻女子正坐在自家的马桶上,而她的短裤已经脱到了大腿中部。

萌萌的TA竟然是个偷窥狂?
时间回到2020年秋天,一系列从低角度拍摄的照片突然出现在了网络论坛上。
其内容全是家庭生活中场景——家具的陈列,电视播放的节目内容,甚至连家庭成员的脸都看得一清二楚。
比如在下面这张图中,一个八九岁的男孩,正趴在走廊的地板上,并很高兴地注视着面前的这个物体。

根据爆料,这些图片全部由iRobot开发的Roomba J7系列扫地机器人拍摄,之后则会被发给Scale AI进行处理,也就是那个大名鼎鼎的人工智能数据标注公司。
Scale AI成立于2016年,在其专有的众包平台Remotasks上,公司会以十分低廉廉的费用与较不富裕国家的远程工人签订合同,并由此建立了一个非常成功商业模式。
而这家公司的创始人Alexandr Wang,曾经从MIT辍学并白手起家,并在今年也就是25岁时,成为了全球最年轻亿万富翁。

值得注意的是,人脸信息在原图中其实是清晰可见的。
我们看到的灰框框,是《麻省理工科技评论》为了保护隐私特地手动打上去的。

那么问题来了,这些信息理论上应该是在严格的存储和访问控制之下的。然而,实际情况却是,它们被负责标注的工人分享到了网上。
这些由机器人拍摄的画面展示了世界各地的家庭房间,有些是人住的,有些是狗住的。家具、装饰品和位于墙壁和天花板上的物体被矩形框勾勒出来,并附有「电视」、「植物或花」和「天花板灯」等标注。
对此,世界上最大的扫地机器人供应商iRobot证实,这些图像是由自家的Roombas在2020年拍摄的。
公司在一份声明中表示,所有这些图像都来自 「经过硬件和软件修改的特殊开发机器人,这些机器人现在和将来都不会出现在iRobot的消费者产品上」。
此外,iRobot还表示,他们已经与Scale AI分享了超过200万张图片,并与其他数据标注平台分享了数量不详的图片。

机器学习革命带来了什么?
今天,越来越多的扫地机器人已经转向计算机视觉,通过训练算法从图像和视频中提取信息来接近人类的视觉,甚至配备激光雷达,该技术被广泛认为是当今市场上最精确但最昂贵的导航技术。
计算机视觉依赖于高清摄像头,越来越多的公司在其机器人真空吸尘器中安装了前置摄像头,用于导航和物体识别,以及越来越多的家庭监控。
为了使扫地机器人中的计算机视觉真正按预期工作,需要在高质量、多样化的数据集上对其进行训练,以反映它们可能看到的巨大范围。与自动驾驶汽车相比,扫地机器人面临的家庭环境更难以标准化,训练难度可想而知。

这时候,训练数据往往需要是更加个性化、私密化的,而且需要以大量的用户基数为支撑,收集这样的数据,需要用户的同意。
以本文iRobot为例,其95%以上的图像数据集来自真实的家庭,这些家庭成员要么是iRobot的员工,要么是由第三方数据供应商招募的志愿者。
根据iRobot的一份声明,使用开发设备的人同意让iRobot在设备运行时收集数据,包括视频流,并可由此换取「奖励」。
但公司拒绝说明这些激励措施是什么,只说它们「根据数据收集的长度和复杂性」而有所不同。

《麻省理工科技评论》采访的大多数扫地机器人公司明确表示,他们不使用客户数据来训练他们的机器学习算法。
然而,在东北大学研究物联网设备安全漏洞的博士生Dennis Giese在对这些机器人进行逆向工程之后发现,它们的管理软件中有一个名为「AI服务器」的文件夹,并有图像上传功能。
这么看来,这些公司所谓的「摄像头数据永远不会被发送到云端」,其实很难成立。
但即便如此,如果这些公司自己不说,或者没有遭到黑客攻击的话,没有人能够验证他们以「训练模型」为由从客户那里具体收集了什么。

我们的数据是怎么泄露的?
众所周知,机器学习算法的训练,需要投喂大量的数据。过程中所依赖的标注数据,则需要消耗非常多的人力资源才能完成。
作为一个新兴但不断增长的行业,数据标注预计到2030年将达到133亿美元的市场价值。
目前来说,负责对数据进行标注的,通常是发展中国家的低薪合同工。
他们通过转录低质量的音频改善语音识别软件,并通过标记照片和视频帮助扫地机器人识别环境中的物体。

2020年,Scale AI发布了一项全新的任务——Project IO。
其特点是,视角从地面以大约45度向上,图像内容为世界各地的墙壁、天花板和地板,以及上面的各种东西,当然也包括人。
通常来说,这些负责标注的工人会在Facebook、Discord和其他社交平台上建群,然后在其中讨论和工作有关的各种问题,比如分享处理延迟付款的建议,谈论报酬最好的任务,或请其他人帮忙等等。
对此,iRobot表示,在社交媒体群组中分享图片违反了Scale与它的协议;Scale AI也表示,合同工分享这些图片违反了他们自己的协议。
但现实情况是,这种行为在众包平台上是几乎不可能被监管到的。
惊喜:你可能已经同意了!
扫地机器人制造商自己也认识到设备上的摄像头带来的更大的隐私风险。
对于摄像头带来的隐私风险,iRobot表示,公司已经对此采取很多保护措施,包括使用加密,定期修补安全漏洞,限制和监控内部员工对信息的访问,并向客户提供有关其收集的数据的详细信息。
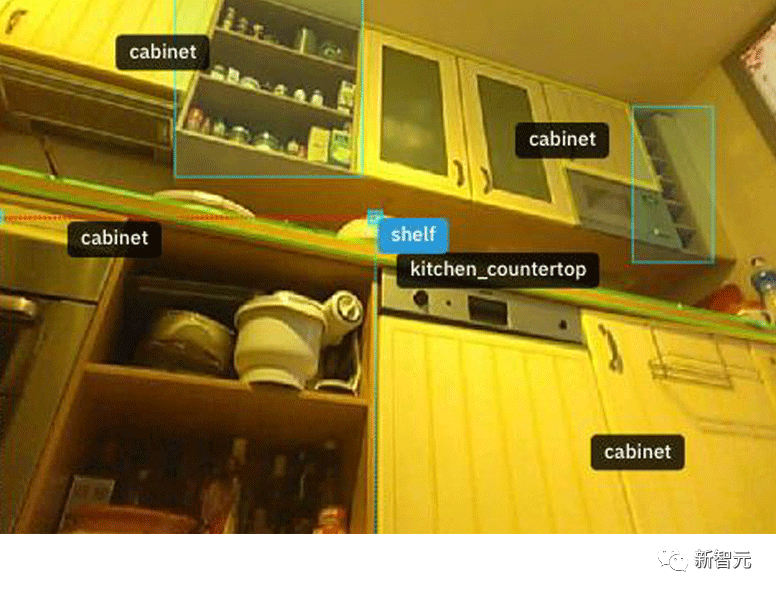
但是,公司谈论隐私的方式和消费者理解隐私的方式之间存在很大差距。
Mozilla的隐私安全项目的研究员Jen Caltrider表示,在企业看来,数据安全指的是产品的物理和网络安全,或者它对黑客或入侵的脆弱性。而数据隐私是关于透明度:知道并能够控制公司拥有的数据,如何使用,为什么分享,是否保留、以及保留多久等等。
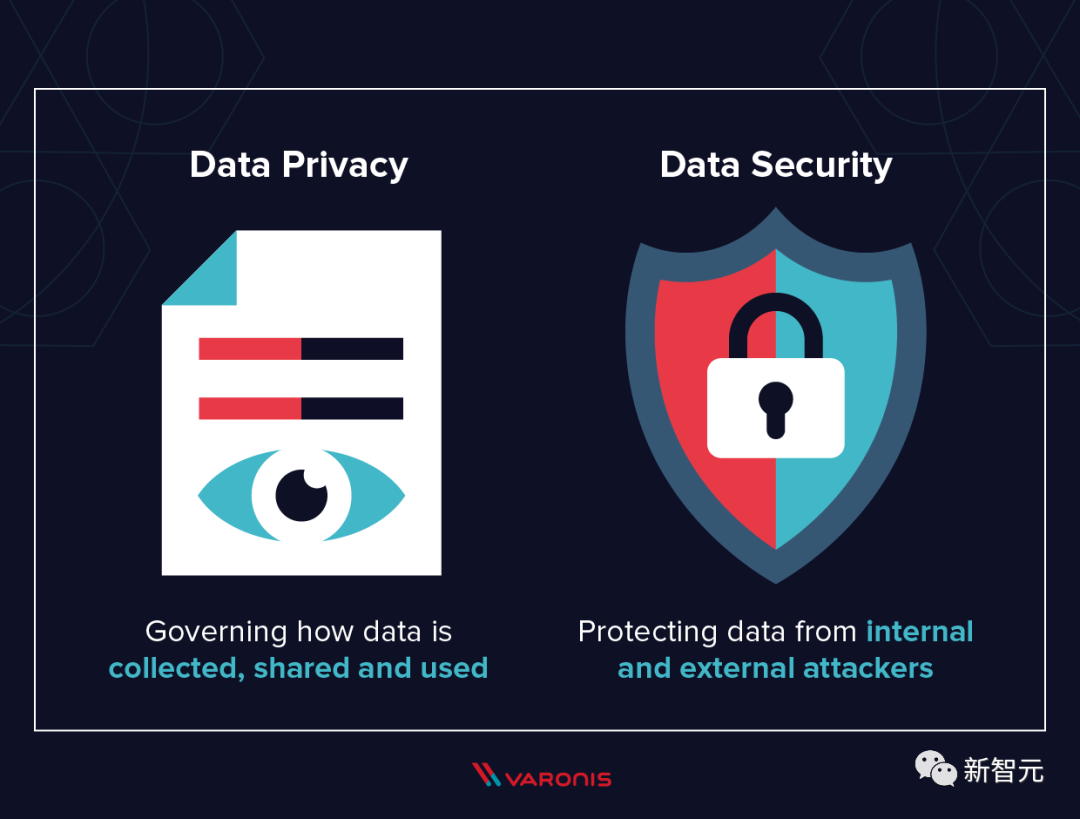
他们有时会使用微妙的措辞差异,比如使用「共享」数据,而不是出售数据,这使得如何处理隐私对于非专业人士来说特别难以解析。
只不过,当一家公司说它永远不会出售你的数据时,它很可能会使用或与他人分享这些数据。
根据公司措辞含糊的隐私政策,这些广泛的数据收集定义往往是合乎规定的,几乎所有的隐私政策都包含一些条款,允许将数据用于「改善产品和服务」,用语非常广泛,基本上拿来干什么都行。
事实上,《麻省理工科技评论》审查了12个扫地机器人的隐私政策,所有这些政策,包括iRobot的,都包含类似的表述。
此外,大部分公司也都没有回应关于所谓「产品改进」是否包括机器学习算法的问题。
在隐私条款中列明的「不公平」或「欺骗性」的做法,基本上都是狭义的,也就是说,除非隐私政策明确规定 「嘿,我们不会让承包商看你的数据」,然后还是分享了数据,否则公司方面在法律上就是没问题的。
扫地机器人,只是个开始
对数据的渴求在未来几年只会增加。扫地机器人只是在我们生活中大量出现的联网设备中的一小部分,而扫地机器人领域的大公司,包括iRobot、三星、Roborock和戴森等,都表示出了比「扫地」更宏大的野心。
机器人技术,包括家用机器人技术,长期以来一直是真正的香饽饽。而且,真正的重点不在于扫地,而在于机器人。

2018年,时任iRobot技术高级副总裁的Mario Munich就在一次演讲中解释过这个问题。
在关于该公司第一台计算机视觉扫地机器人Roomba 980的演示中,他展示了来自该设备有利位置的图像:包括一个有桌子、椅子和凳子的厨房,旁边是机器人算法对它们的标记和感知。
实际上的挑战不在于吸尘,而在于机器人,他解释说。如果我们能够更充分了解环境,就能够改变机器人的操作。

制造扫地机器人的公司已经在投资其他功能和设备,使我们更接近机器人的未来。
可想而知的是,这样的业务多样化大潮,带来的是对数据标注在深度和广度上巨大需求的双重增长,一旦这种需求没有有效监督,或者超出了监管的能力,对隐私的侵犯就变得几乎不可避免。
而很多时候,这种侵犯是以一种便捷、易用、智能的方式进行的。
参考资料:
https://www.technologyreview.com/2022/12/19/1065306/roomba-irobot-robot-vacuums-artificial-intelligence-training-data-privacy/
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
