今天分享的论文的主题是对大型公共DNS解析器缓存的探测和测量,研究团队来自于加州大学圣地亚哥分校。该论文设计并优化了针对大型公共DNS解析器的缓存探测工具:Trufflehunter,可对罕见或敏感域名使用的普遍性进行评估。作者对目前4个主流大型公共DNS解析器的缓存架构进行了分析,并对一些敏感域名进行了测量。该论文发表于2020年网络测量领域国际顶级会议ACM IMC(录用率:54 / 216 = 25%)。

01【背景介绍】
域名系统(DNS)负责将域名映射为IP地址,是互联网非常重要的基础设施,几乎所有互联网应用都依赖于域名系统。随着互联网体系的发展,域名解析的需求也愈发旺盛。因此,大型公共DNS服务也越来越流行,例如被人们熟知的Google Public DNS(GPDNS)“8.8.8.8”。
与传统的开放DNS解析器相比,大型公共DNS服务有着独特的性质。其一是作为面向全球、规模庞大且快捷专业的DNS服务,其用户规模非常庞大,所承载的解析需求也十分巨大[1];其二是大型公共DNS服务为了实现负载均衡,往往有着复杂的缓存架构。这些DNS服务的缓存并不是整体、连续的,而是由诸多零散的DNS缓存所构成[4,5]。具体而言,它由众多的独立服务点(PoP,Points-of-Presence)组成。如图表1所示,用户的查询首先通过IP Anycast被路由到遍布全球的PoP中的一个;在PoP内,查询通过负载均衡被分配到前端缓存池中;如果负责处理查询的前端缓存并没有所查域名的结果,将再次通过负载均衡将请求转发到后端解析器池中的一个;最终,后端解析器执行递归查询获得结果,在回复结果的同时,请求处理路径之上的缓存也都会被填充。

图表1:公共DNS解析器响应过程
由于大型公共DNS服务的缓存节点众多且彼此独立,其对某个域名的缓存数量也可以作为衡量域名流行程度的评价标准。当一个域名越流行,用户对该域名的查询需求也就越多,其在大型公共DNS服务中的缓存数量也会更大。尤其是对于一些恶意或者敏感的域名,窥探大型公共DNS服务的缓存可以提供一个活跃用户数量的下限,以评估其危害的程度。同时,公共DNS的共享属性,也避免了因为缓存窥探行为损害用户隐私。
不过,由于大型公共DNS解析器缓存架构相对复杂,对其进行缓存窥探是极具挑战的工作。每个缓存探测的探针所得到的结果只包含了一个PoP中一个缓存的状态,但测量者并不知道结果来自于哪个缓存,也不知道来自于哪个PoP。论文的主要贡献便是开发了工具Trufflehunter,利用TTL信息和结果优化方法实现了对大型公共DNS解析器缓存情况的窥探,并利用该工具,基于对4大主流公共DNS服务的分析,评估了部分域名的使用普遍性。
02【研究方法】
1. 缓存探测与辨别
Trufflehunter在缓存探测方面与传统方法没有本质区别,都是在不设置期望递归(RD)标志的情况下查询一个特定的域名。这种方式可以防止后端解析器执行递归查询,从而根据结果确定缓存中是否有所查域名的记录[2,3]。
与此同时,响应中还会包含记录的TTL,这是区分是否来自同一缓存的关键。TTL是一个秒级单位的数值,随着时间的流逝而不断减小。所以,如果横轴为时间,纵轴为TTL的值,那么缓存TTL的变化应该是一条斜率为-1的线(TTL Line)。理论上,源自同一缓存的响应都会分布在同一条TTL Line上,因此TTL Line的数量也就对应了独立缓存的数量。
2. TTL Line识别优化
由于DNS响应中TTL只精确到秒,响应中的TTL值和探针维护的TTL Line之间可能存在亚秒级的测量偏差,出现如图表2所示的3种情况:(1)探针和缓存的TTL在解析器生成响应和响应到达探针主机之间保持不变,为理想状态下的正确情况。(2)生成响应和探测主机收到响应的亚秒级偏差使TTL值递减,导致TTL Line识别不准确。(3)探针和解析器时钟不同步,导致TTL测量不准确。
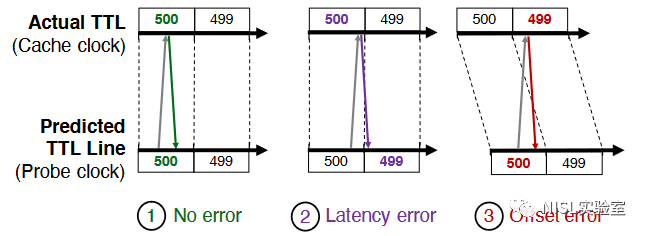
图表2:TTL Line的错误匹配情况
为避免上述问题,文章给出了启发式的方法:如果来自缓存探测的TTL位于同一TTL Line,则假定没有错误;如果一组TTL值位于两个相邻的TTL Line(相隔一秒),则假设其中一个出现错误并将其删除;如果TTL位于三条或更多相邻的TTL Line,每条线相隔一秒,则删除该组的第一条和最后一条线,理由是,第一条TTL Line可能由于TTL高估导致,而最后一条线可能由于TTL低估导致,但中间线上的TTL将至少包含一个正确的测量值。
3. PoP识别
在使用TTL Line 区分结果是否来自不同缓存的基础上,还需要明确结果来自于哪个PoP。文章研究了OpenDNS、Quad9、Cloudflare和GPDNS四家公共DNS服务商,这些公共解析器都可以通过特定的查询请求来确定响应来源。以GPDNS为例,用户可以首先通过查询“locations.publicdns.goog.”的TXT记录,获得IP网段与位置的映射关系;随后通过查询“o-o.myaddr.l.google.com”的TXT记录获得负责解析的具体地址,根据映射关系即可确定来源。
4. 数据收集
论文研究内容包括:首先通过查询一个由研究人员控制的域名,分析TTL的变化以及权威收到查询的情况,实现对4大主流公共DNS服务商缓存架构的探测;其次依靠用户模拟查询的情况和探测结果的比对,评估缓存探测框架Trufflehunter的准确率;最后利用Trufflehunter,对几个敏感域名在4个主流公共DNS解析器上的缓存情况进行测量,评估其使用的普遍程度。具体地,作者使用Ark网络来部署缓存窥探的探针,并使用了RIPE Atlas网络来执行用户查询模拟操作。
03【主要发现】
1. 4大公共DNS解析器缓存架构
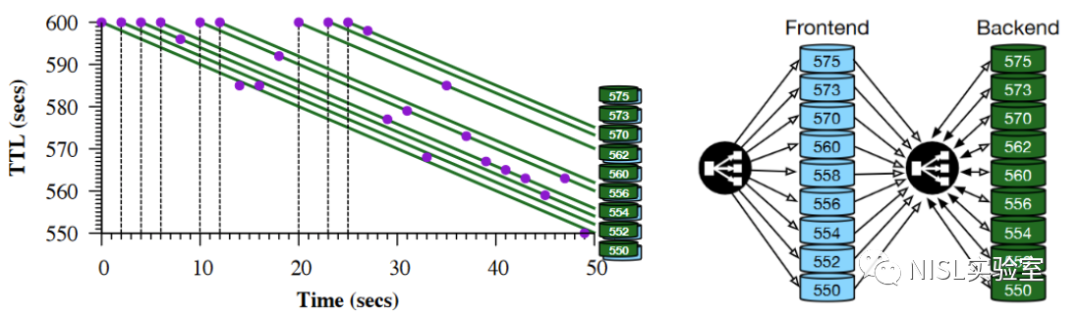
图表3:OpenDNS和Quad9的缓存处理模式以及缓存架构
文章测量发现,OpenDNS和Quad9采用了最直接的缓存处理模式,所观测的每一个包含MAX TTL值的响应,都可观察到对权威解析器的查询。因此,OpenDNS和Quad9的前端没有缓存,查询是由后端解析器解决的。
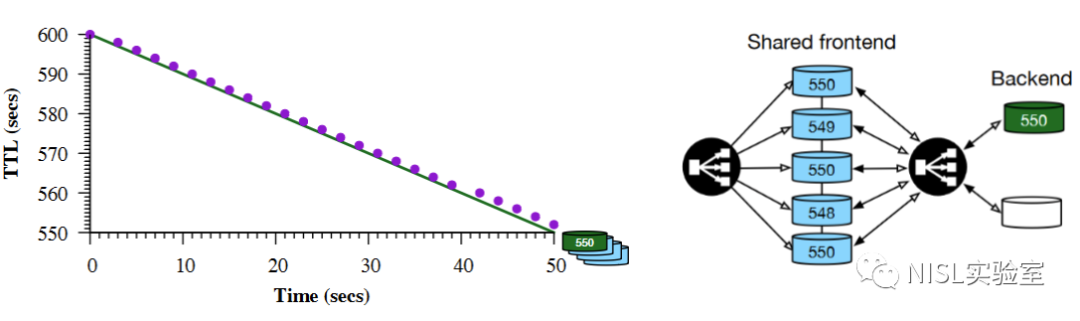
图表4:Cloudflare的缓存处理模式以及缓存架构
对于Cloudflare而言,如图表4所示,所有响应都落在同一TTL Line上,而该Line源自第一次查询。也就是说,Cloudflare的DNS服务使用了共享前端缓存架构的DNS解析器。具体地,Cloudflare使用 knotDNS 的解析器,前端缓存有一个共享的支持数据库。
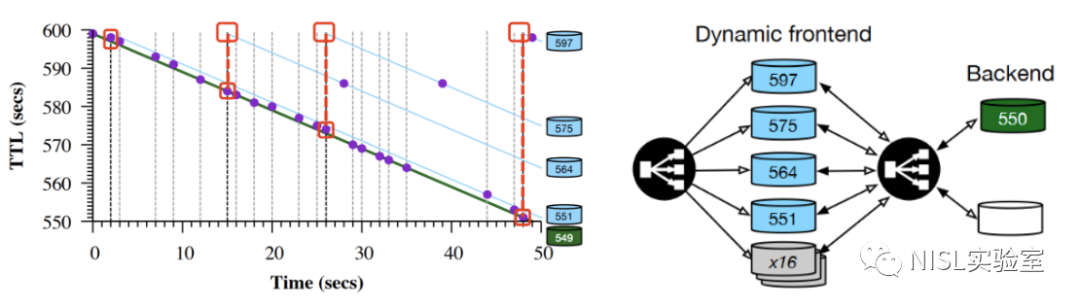
图表5:GPDNS的缓存处理模式以及缓存架构
Google的公共DNS解析器有一个独特的缓存处理模式,当查询到一个不包含域名的前端缓存时,GPDNS似乎会创建一个新的、独立的前端缓存。具体而言,当查询被负载平衡到一个缓存未命中的前端时,它将把查询转发给后端解析器。后端解析器向用户发送查询的响应,然后它将填补前端缓存中的空缓存。但填充的是Max TTL值,而不是后端缓存中缓存条目的当前TTL。因此,每一次对前端缓存的错过都会填充一个唯一可识别的新前端缓存。
如图表5所示,后端解析器的每一次缓存命中都被标记为一条垂直的虚线,该虚线标志着一个前端缓存在那个时间点上被填充了最大的TTL,从图中也可以看到确实有四条TTL Line与虚线在Max TTL处相交。
2. Trufflehunter的准确性评估
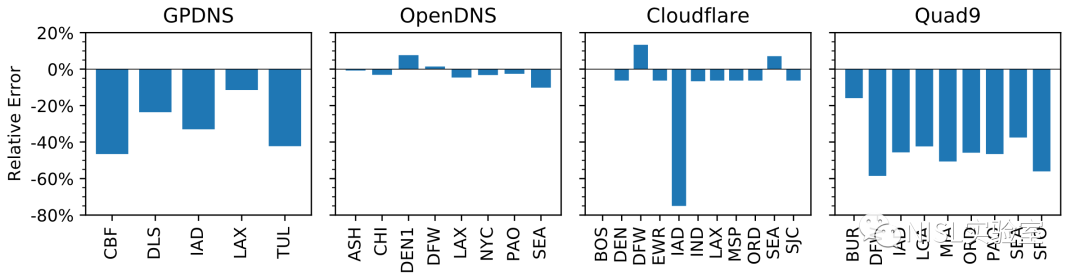
图表6:缓存估计偏差
对于不同的的公共解析器,Trufflehunter所表现出的准确性不尽相同。其中Quad9的后端解析器中使用到了Unbound,该软件默认不回答禁用了递归期望标志的查询,返回REFUSED,因此导致对大多数PoP的缓存数量都低估了50%以上。而GPDNS则是由于其特有的缓存模式,使得探测很难识别完全。
但整体上来看,Trufflehunter的结果是低于实际缓存数量的。不过,考虑到Trufflehunter的设计初衷是对于某个域名的普遍程度提供一个下限值参考,这种低估的结果是可以被接受的。
3. 敏感域名测量
文章中分别对隐私跟踪软件(Stalkerware),合约作弊服务(Contract Cheating Services)以及误植域名(Typo Squatting Domains)三种敏感服务的普遍程度进行了测量。
隐私跟踪软件:如图表7所示,文章对22个不同的Stalkerware在一个TTL周期中的缓存数量进行了测量,测量持续了近3个月,并将所观测到的最大值进行了统计。透过缓存数量可以看到的GPDNS承担了大部分解析工作,这也从侧面表明GPDNS所承载的域名解析请求量很大。

图表7:单个TTL周期内不同隐私跟踪软件的规模
合约作弊服务:此类域名通常是为学生提供家庭作业、项目甚至是整个课程代做的收费服务。文章对10个流行的合约作弊服务网站进行了测量,按照天为单位统计了网站的访问量,如图表8所示。比较有意思的是,一些服务在5月底时访问量有所减少,可能是因为学校逐步开始了暑假。
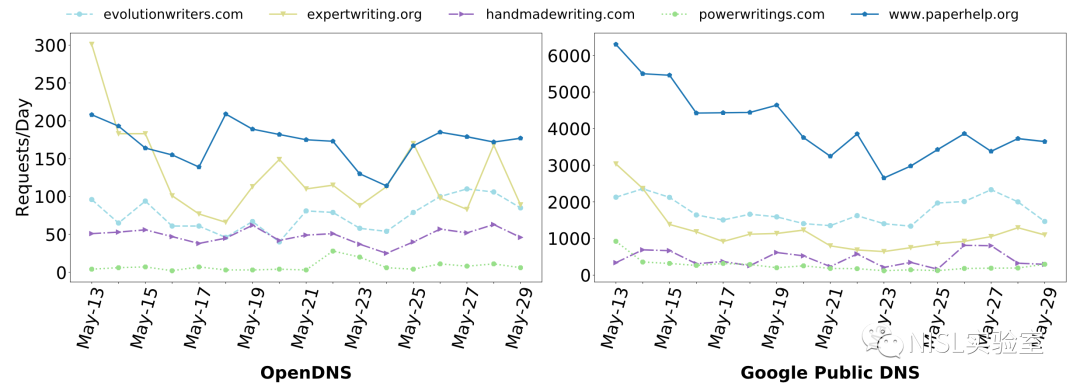
图表8:合约作弊服务每天的网络请求量
误植域名:此类域名是一种域名抢注滥用行为,即注册一个与流行域名相似的域名,并期望用户在浏览器等应用中输入网址时犯下拼写方面的错误。例如,ggoogle.in 便是google.in的一个误植域名。攻击者通过抢注这类域名,可以将用户错误访问后的流量导向自己控制的网站,以便进行钓鱼等欺诈活动。如图表9所示,论文对5个误植域名进行了测量。这5个域名在作者展开测量时已经被注册使用了2年之久,即使出现在一些黑名单上也不足为奇,但其中几个域名仍然表现出了很强的活跃性。
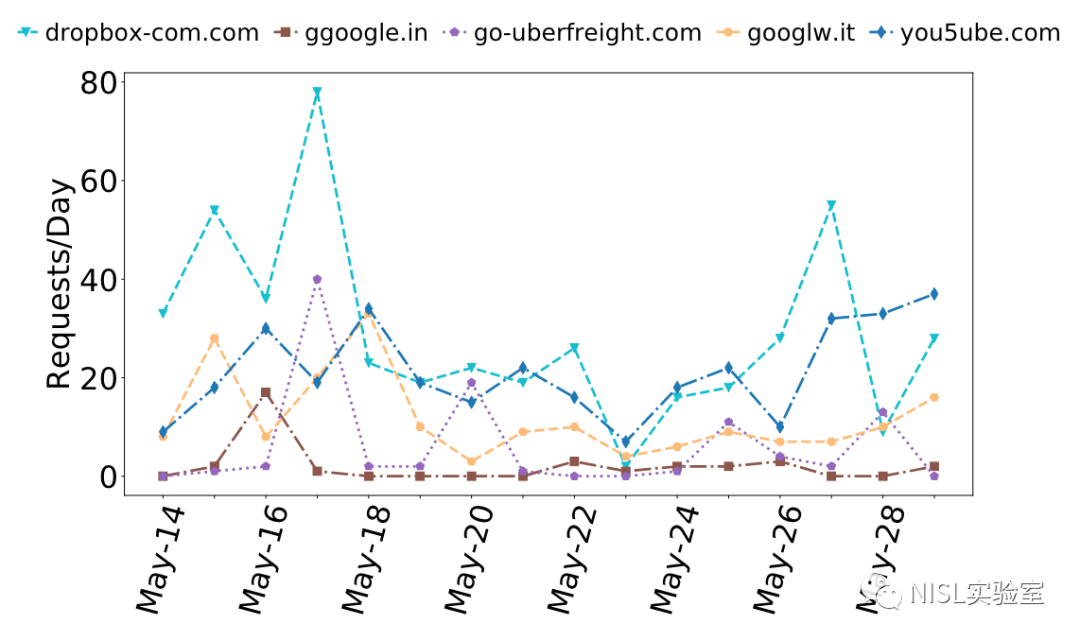
图表9:GPDNS上每天对误植域名的网络请求数
04【总结】
公共DNS解析器分布式缓存的特点,使得研究人员可在不侵害用户隐私的前提下,依然可以利用缓存窥探域名普遍性。论文提出了可行的、面向公共DNS服务的缓存窥探方法,提出了针对性的结果优化措施,形成探测框架Trufflehunter。尽管该方法在准确度上还有着不小的偏差,其仍可提供域名普遍性的最低限度参考值。论文还利用Trufflehunter的测量策略,尝试分析和解读了4个主流大型公共DNS解析器的内部缓存处理模式。
原文链接
https://cseweb.ucsd.edu/~schulman/docs/imc20-trufflehunter.pdf
开源工具链接
https://github.com/ucsdsysnet/trufflehunter
参考文献
[1] Giovane C. M. Moura, Sebastian Castro, Wes Hardaker, Maarten Wullink, and Cristian Hesselman. 2020. Clouding up the Internet: How Centralized is DNS Traffic Becoming?. In Proceedings ofthe ACM Internet Measurement Conference (Virtual Event, USA) (IMC ’20). Association for Computing Machinery, New York,NY, USA, 42-49.
[2] Paul V. Mockapetris. 1987. Domain names - concepts and facilities. RFC 1034(1987), 1–55.
[3] Paul V. Mockapetris. 1987. Domain names - implementation and specification.RFC 1035 (1987), 1–55.
[4] Giovane C. M. Moura, John Heidemann, Moritz M ̈ uller, Ricardo de O. Schmidt, and Marco Davids. 2018. When the Dike Breaks: Dissecting DNS Defenses During DDoS.
[5] Lior Shafir, Yehuda Afek, Anat Bremler-Barr, Neta Peleg, and Matan Sabag. 2019. DNS Negative Caching in the Wild. In Proc. ACM SIGCOMM Conference Posters and Demos.
许威,编辑&审校|张一铭、刘保君
声明:本文来自NISL实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
