一直以来,金融与信用二字相伴相生,欺诈则是它们的天敌。随着互联网金融的发展,层出不穷的营销活动和品类繁多的网贷产品让欺诈分子有了更多可乘之机,欺诈成本越来越低,足不出户就可以日进斗金,因此金融、电商、航空、游戏等“离钱近”的领域纷纷沦为重灾区。
在云计算、大数据、互联网金融快速发展的环境下,安全企业与黑产之间正在形成“矛与盾”的攻防对抗,双方不断在技术研究、资源拓展层面展开较量。为了遏制欺诈活动,金融机构和互联网公司都会构建自己的反欺诈团队和防范系统,通过各种规则和预测模型将欺诈分子拒之门外。
然而,道高一尺,魔高一丈,再严密的规则也难免会有漏洞,加之欺诈手段日新月异和团体欺诈盛行,采用传统的反欺诈工具总是略显被动。因此,关系图谱的实践应用将充分发挥它的潜能与价值。关系图谱简单来说,就是描述个体及个体之间关系的图,其之于反欺诈,就如同飞机之于军队,可以从更高的维度去侦测和打击对手。
什么是关系图谱
关系图谱是一种基于图的数据结构,由节点(Point)和边(Edge)组成。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。
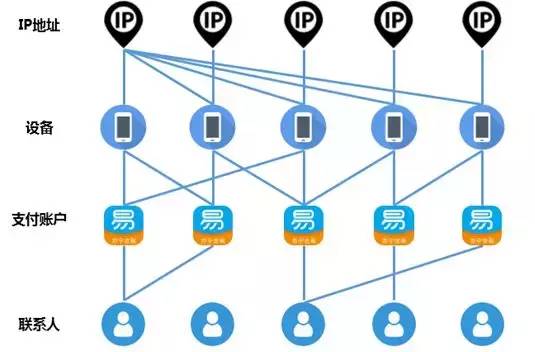
下图给出了一个移动支付场景的关系图谱示例,个体类型可以包括IP地址、设备、支付账户、账户联系人等,个体之间也可以存在不同的关系,比如IP登录行为、设备登录行为、联系人登记行为等。
关系图谱的实践应用
(1)全维度的事中侦测
在欺诈检测系统中,诸如登录时间和位置(例如IP地址)之类的行为线索很容易被欺诈分子改变或伪造,但是欺诈分子很难全面地了解他们所在的整个关系网络(例如转账、购物、登录、浏览、还款)。因此,即便欺诈分子尽可能地掩盖了痕迹,也难免会在关系网络上露出马脚,比如上图中的共用设备、共用联系人信息、共用IP等就可以作为可疑特征用于识别欺诈事件。
(2)全局的可视化事后分析
一方面,反欺诈部门分析人员可以根据已定性案件在关系图谱上呈现出来的全局特征,优化风控规则和模型。例如,一个可疑账号可能会登录多个设备,而这些设备往往会被登录多个可疑账号。关系图谱可以非常直观地呈现这种间接的多对多关系。另一方面,也可以挖掘看似独立却存在间接联系的案件之间的关系,识别核心作案人员和其他疑似欺诈分子。
(3)全渠道的标签传播
关系图谱也可以基于现有黑名单,为可疑个体打上相应标签,用于反欺诈规则和风险提示。假设已确认一个黄牛常用手机号,可在关系图谱中把这个手机号直接和间接关联的账户、手机号、地址、银行卡等个体打上“疑似黄牛”的标签,这种路线便是标签传播。

(4)高效的信息检索
传统的数据存储通常基于关系型数据库,比如转账、登录等各种关系分别存储在不同的表中,想要抽取多级关系信息则需要连接多个表才能实现。而关系图谱一般存储于图数据库中,常用的图数据库如neo4j、orientDB等。
当关系深度较小时,比如深度为2(类似查询朋友的朋友这种关系),关系型数据库和图数据库的性能相当;当关系深度超过2时,关系型数据库所需的查询时间达到图数据库所需时间的上百倍甚至上千倍,这时图数据库的性能优势就非常明显了。
构建关系图谱的关键点是什么
目前构建关系图谱的一个重大挑战在于用户的行为数据是割裂的,散布在政府机关、传统金融机构、运营商和互联网公司的数据中心,任何一方都很难获取用户端到端、全渠道的数据,缺失关键信息则会显著影响侦测欺诈行为的效果。可以说,数据决定了关系图谱作用的上限,而图谱的本体设计和相关图算法都要基于原始数据。

在大数据时代,很多数据都是未经处理过的非结构化数据,比如文本、图片、音频、视频等,这些数据单元数量庞大,携带的信息众多,有用信息与无用信息鱼龙混杂,难以辨识。特别在互联网金融行业里,怎么从这些非结构化数据里提取出有价值的信息是一件非常有挑战性的任务,因此,这就需要与机器学习、数据清洗挖掘、设备指纹、自然语言处理等相关技术综合运用起来,搭建反欺诈规则模型,将更有效地分析复杂关系中存在的特定的潜在风险。
一方面,只有当大部分数据所有者将数据共享出来、打破数据孤岛,让数据沉淀达到一定的体量,才能真正配合技术实现行业风险的降低,让欺诈者无处遁形。另一方面,关系图谱还需要充分利用已有数据,比如时间序列信息,构建动态关系图谱(如下图)来更有效地预测和识别欺诈风险。

随着物联网的技术发展和场景丰富,一个人的所有行为可能都将被数字化并映射到关系图谱上,那么,在反欺诈的拉锯战中,正规军能否战胜黑产军团呢,我们拭目以待吧。
(内容参考自苏宁财富资讯,倪伟渊 苏宁金融研究院高级研究员)
声明:本文来自金融科技安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
