原文标题:Open-CyKG: An Open Cyber Threat Intelligence Knowledge Graph
原文作者:Injy Sarhan, Marco Spruit原文链接:https://www.sciencedirect.com/science/article/pii/S0950705121007863发表期刊: Knowledge-Based Systems笔记作者:JSY2019@SecQuan笔记小编:cherry@SecQuan
研究背景和研究介绍
互联网上每日都会生成的难以估量的网络安全信息。在专家分析网络安全形势时,总会参考已有的安全报告、安全告示等。然而,这类安全信息往往是非结构化的。作者提出了现有的信息抽取方式的两个不足之处:一是仅以某些预定义的关系组合或已存在的本体图来抽取信息,从而导致了信息抽取的局限性;二是缺少一种可以有效储存、查询和理解所存信息的数据结构。
作者在该论文中提出了一个基于开放信息抽取系统(OIE)的开放式网络威胁抽取系统框架:Open-CyKG。其可以抽取非结构性APT报告数据,并把这些信息存于知识图谱,后者可进行高效的查询。
研究内容
作者提出的Open-CyKG的大致内容如图。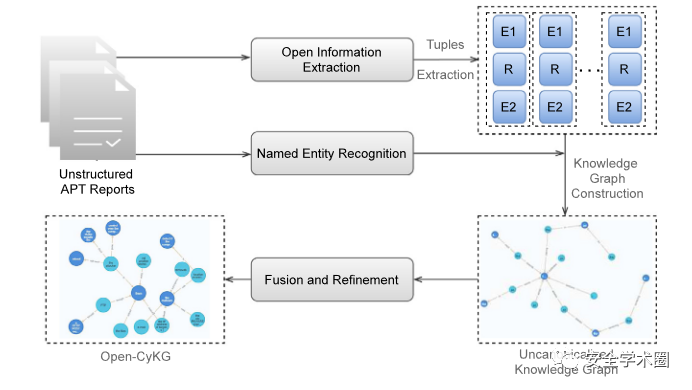
包括三个主要模块:
用于从非结构化的APT报告中提取关系三元组的普通OIE系统
一个使用预定义标签来识别和分类的网络空间安全领域的NER模型
一个知识图谱构建和融合模块
文章所采用的方法
OIE模型
作者采用的OIE模型为采用BIO标注方案的序列标记模型,采用了双向GRU层、注意力机制、TDD层、Softmax层。

该模型以嵌入后的内容做输入,输出为所有tag的独立概率。
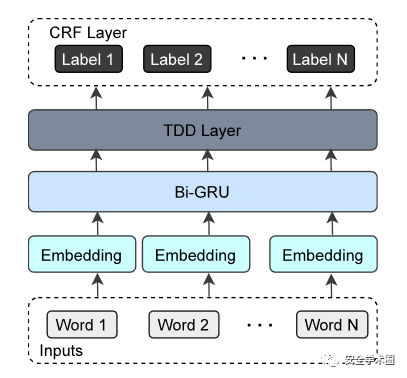
网络安全领域的NER
作者采用了与OIE模型相似的模型构造。文章提出的NER模型同样为BIO标注方案的序列标记模型,主要由四层组成。
知识图谱的构建和规范化
作者设计了一个知识图谱建立模块,其包括三元组去重、实体消歧和删去组成成分无一在NER阶段被分配任何实体标签的三元组。
对于实体消歧,作者提出了一种使用上下文词嵌入的方式来捕捉实体语义的方式来进行实体融合。首先,对实体中的所有主体的词嵌入进行平均,然后根据余弦相似度采用层次聚类(HAC)对实体进行聚类。在聚类结果的每个簇中,计算所有生成元素的嵌入平均值,并以每个元素在输入中的出现次数加权。该簇加权平均值距离最小的实体作为该簇的实体。
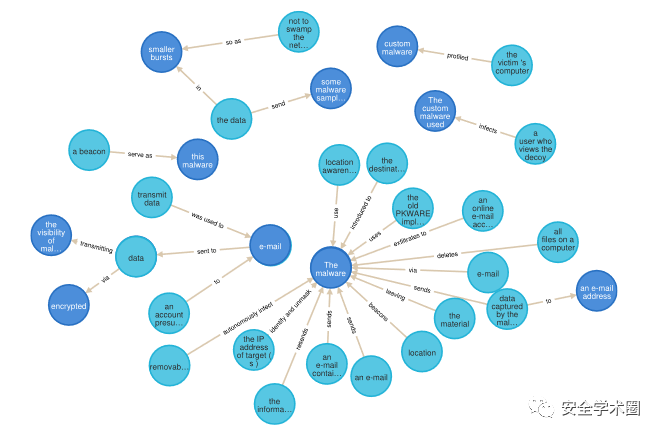 图:规范化之前
图:规范化之前 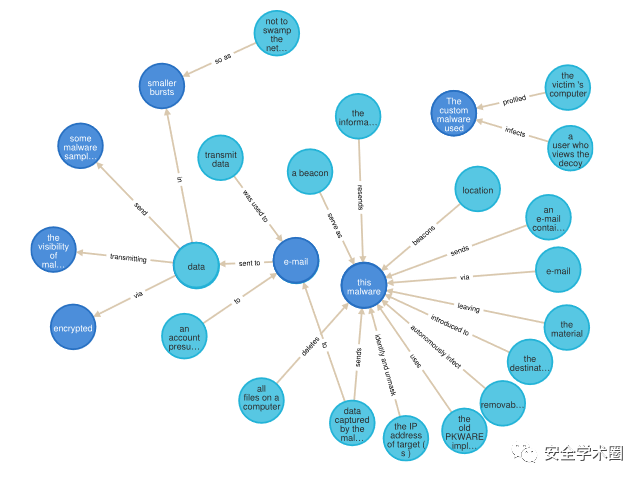 图:规范化之后
图:规范化之后
实验及结果
对OIE模型的实验
作者采用了MalwareDB数据集作为训练OIE模型的数据集。其含有来自29个APT报告的6819个句子,其中1910个可用作OIE的训练的句子。
该OIE模型被与之前提出过的几个模型相比较,并进行了网格搜索以优化参数。其表现结果如下表。

对NER模型的实验
作者采用了两种不同的数据集,分别包括不同的标签。分别为Microsoft Security Bulletins和[1]所采用的数据集。前者包括微软的软件缺陷、漏洞、补丁和减灾信息,后者包括不同的CTI报告。
文章将数据集以80%、18%和2%分开作为训练、测试和验证比,并用5-fold验证,与先前提出的几个模型相比较,结果如下表。
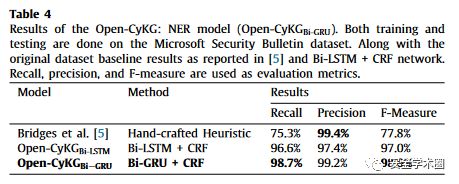 表:以Microsoft Security Bulletins作为数据集
表:以Microsoft Security Bulletins作为数据集 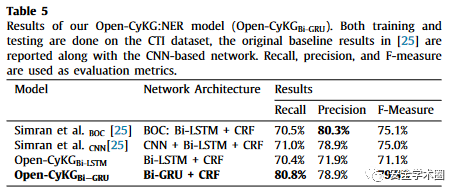 表:以CTI作为数据集
表:以CTI作为数据集
对知识图谱标准化的评估
作者手动构建了一个标准的聚类簇,代表了真实值。随后通过macro, micro和pairwise三个指标来衡量标准化的程度。
其结果如下表。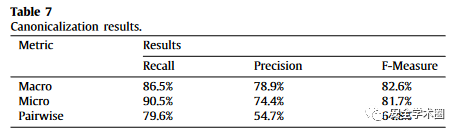
样例查询
最终,作者提供了两个查询样例。其一是较为宽泛的问题,其二是较具体的针对水坑攻击的问题。作者以这两个问题来展示实体融合方案的效果。

参考文献
[1]Gyeongmin, Chanhee, Jaechoon, et al. Automatic extraction of named entities of cyber threats using a deep Bi-LSTM-CRF network.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
