今天分享的论文主题为针对图神经网络的推理攻击研究。该工作由来自亥姆霍兹信息安全中心以及诺顿研究组的研究人员共同完成。该论文通过实现三种推理攻击(Inference Attacks),对图嵌入的信息泄露问题进行了研究,并提出一种基于图嵌入扰动的防御机制。该论文已被网络安全领域顶级会议USENIX Security 2022录用(录用率:256/1492 = 17.2%)。

01【背景介绍】
图(Graph)是一种应用广泛的数据表示方式,许多现实世界的网络系统可以用图表示,如社交网络、金融网络和化学网络。由于图的非欧几里得性质,其并不具备其他类型数据(如向量)的一些常见的特征,如坐标和矢量空间,给图数据的分析带来了一定困难。为了解决这个问题,人们提出了图嵌入(Graph Embedding)算法,以在欧氏空间中获得简洁有效的图数据表示[1, 2, 3]。这些算法的核心思想是将图从非欧氏空间转化为低维向量,并将图的信息保存下来,随后节点分类和图分类等下游任务就可以有效地进行。
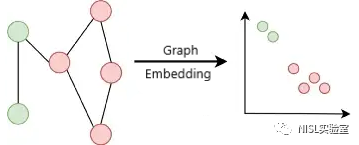
图表1:图嵌入算法示意
为了更好地获得图嵌入,研究人员提出了一类新的深度学习模型系列,即图神经网络(Graph Neural Networks, GNNs),其核心思想是训练一个深度神经网络,聚合邻接节点的特征信息以获得节点的嵌入。利用这些节点的嵌入可以进一步获得图嵌入,从而将整个图压缩成一个向量。
在实际应用中,为便于下游的分析任务,图嵌入向量可能会与第三方共享。例如,数据所有者可以在本地计算图嵌入,并将其上传到谷歌提供的Embedding Projector服务,以直观地探索图嵌入的属性。Facebook、Amazon、腾讯等公司发布了图嵌入系统应用和一些预训练的图嵌入,以方便对图数据的分析和推理。
图嵌入的共享对下游任务开展很有帮助,也已经被广泛使用,但共享过程可能存在安全和隐私问题:已有研究表明,对图像和文本数据使用嵌入在保持数据相似性的同时,也可能会泄露它们在欧氏空间中的敏感信息[4, 5]。而图嵌入的目标也是保持图层面的相似性,那么一个自然的问题是,图嵌入会不会泄露其对应图的敏感结构信息?
02【研究问题】
在本文中,作者通过实现三种推理攻击(Inference Attack),对图嵌入的隐私问题进行了研究:
1.属性推理攻击:目的是推断出目标图的基本属性,如节点数、边数、图密度等。
2.子图推理攻击:对给定的图的嵌入和感兴趣的子图,攻击者的目的是确定该子图是否包含在目标图中。
3.图重建攻击:目的是重建一个与目标图有类似结构属性(如图结构、度分布、局部聚类系数等)的图。
此外,为了防御这些推理攻击,作者进一步提出了一种基于图嵌入扰动的防御机制。
03【研究方法】
攻击建模
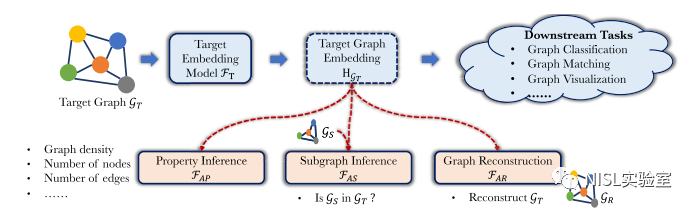
图表2:威胁场景建模
作者对攻击情景的建模是,攻击者从受害者处获得了整个图的嵌入(称为目标图嵌入,可以从Embedding Projector、预训练的图嵌入等来源获得),攻击者的目标是推断出用于生成该图嵌入的图(称为目标图)的敏感信息,目标图嵌入由GNN模型(称为目标嵌入模型)生成。为了训练攻击模型,作者假设攻击者有一个来自与目标图相似分布的辅助数据集,这在具体的应用实践中是合理的。此外,进一步假设攻击者只有对目标嵌入模型的黑箱访问权,例如通过公共API访问或免费在线获取。
属性推理攻击
1.攻击建模:作者的攻击模型将目标图嵌入作为输入,并同时输出目标图的所有感兴趣的图属性(如节点数、边数等)。
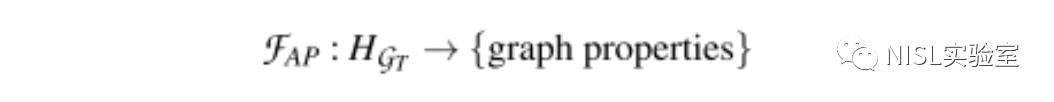 公式1:属性推理攻击模型形式
公式1:属性推理攻击模型形式
2. 攻击意义:GNN的主要目标是从图中学习下游任务的信息,例如,蛋白质的毒性预测。但图的许多属性,如节点数,与下游任务无关。如果属性推理攻击成功,则意味着这些属性被GNN过度学习[4, 5]。当图中包含有价值的信息时,推理出这些属性会直接侵犯数据所有者的知识产权。
3.攻击方法:
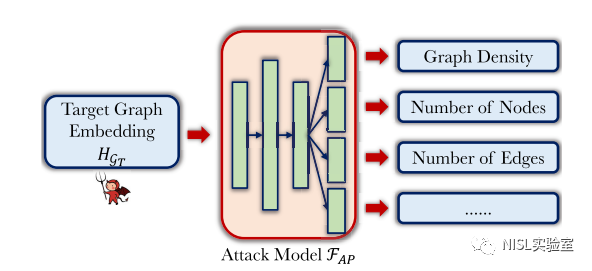
图表3:属性推理攻击模型
作者将攻击模型设计为一个多任务分类模型,其可以同时预测所有感兴趣的图属性,包括一个特征提取器(多个顺序线性层)和多个并行的预测层。作者使用来自目标图相似分布的辅助图数据集和相应的图属性作为训练数据来优化攻击模型。
子图推理攻击
1. 攻击建模:作者的攻击模型将目标图嵌入和一个感兴趣的子图作为输入,并输出该子图是否包含在目标图中。
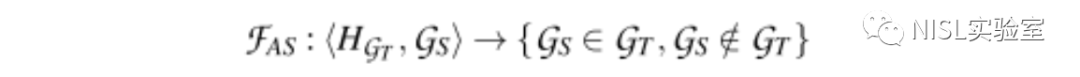 公式2:子图推理攻击模型形式
公式2:子图推理攻击模型形式
2. 攻击意义:例如,攻击者如果获得了化学分子图的图嵌入,就可以推断出一个特定的子图结构是否包含在图中,从而对数据所有者的知识产权和利益构成直接威胁。
3. 攻击方法:
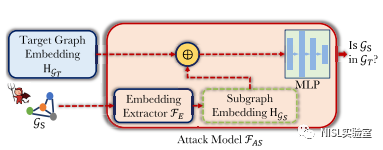
图表4:子图推理攻击模型
作者在攻击模型中集成了一个图嵌入提取器,将子图转换为子图嵌入,然后将目标图嵌入和子图嵌入聚合为一个特征向量,并将其发送到多层感知机中进行二分类。作者通过对辅助数据集中的图进行子图采样生成正样本和负样本作为训练数据来优化模型。
图重建攻击
1.攻击建模:作者的攻击模型将目标图嵌入作为输入,并输出一个与目标图具有相似图统计量(如度分布、局部聚类系数)的图。

公式3:图重建攻击模型形式
2.攻击意义:如果目标图是一个社交网络,那么重建的图将允许攻击者直接获得社会关系相关的敏感知识;如果目标图是一个化学分子图,知道分子的高级结构可能会导致拥有其专利公司的损失。例如,攻击者可以利用重建的分子图来缩小探索空间,从而以比拥有专利公司低得多的成本开发非专利药物。
3.攻击方法:
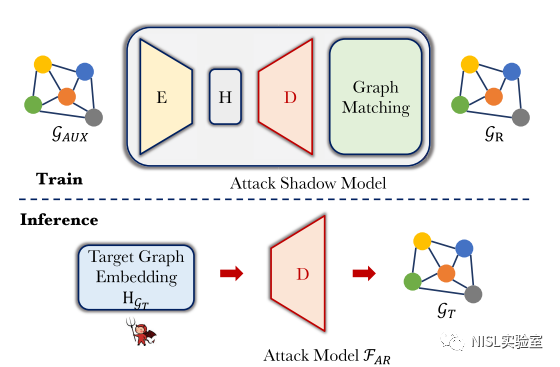
图表5:图重建攻击模型
图重构攻击是最具挑战性的任务,因为需要根据单个向量重建整个图。为此,作者使用一个专门的图自动编码器[6](包括编码器、解码器和图匹配)的解码器部分作为攻击模型。图自动编码器训练完成后,作者将目标图嵌入输入解码器,解码器将输出与目标图具有相似图统计的重构图。不过这种方法存在一定缺陷:训练中的图匹配环节复杂度达到了O(n^4),因此图重构攻击只能用在有几十个点的图数据中。但这对于一些生物化学分子图来说是足够的。作者计划在未来工作中扩大攻击适用的规模,并且在攻击中重建出节点的特征。
防御措施
一个常用于推理攻击的防御机制是在模型的输出中加入扰动[8]。在论文中,作者也提出在与第三方共享之前,向目标图嵌入添加扰动以防御推理攻击。对于给定的目标图嵌入,数据拥有者只向第三方分享图嵌入的噪声版本。

公式4:加入噪声的图嵌入
其中Lap(β)表示从尺度参数为β的拉普拉斯分布采样的随机变量。
但是,在图嵌入向量中加入噪声可能会破坏图的结构信息,从而影响正常的任务。因此,作者通过实验选择了一个合适的噪声水平来权衡防御效果和正常任务的性能。
04【实验结果】
数据集及模型
作者主要在五个常用的公开数据集[7](包括两个生物信息图数据和三个化学分子图数据)和三种图嵌入方法(使用3-layer SAGE实现点嵌入,并分别使用MeanPool、DiffPool、MinCutPool从点嵌入获取图嵌入)上进行了实验,以验证其提出的攻击方法的有效性,使用到的数据集见下表。
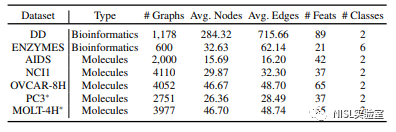
图表6:实验使用的数据集
属性推理攻击
1.实验设置:实验使用攻击准确率,也就是模型正确推理出的图的比例来衡量攻击性能。作者考虑了五个不同的图形属性:节点数、边数、图形密度、图形直径和图形半径,并将每个图形属性的域分成k个桶,从而将攻击转化为一个多分类问题。作者采用随机猜测和直接总结辅助数据集作为基线攻击方法。
2.实验结果:下图表明了攻击性能,其中不同的行代表不同的图形属性,不同的列代表不同的数据集。总的来说,实验结果表明,作者的攻击在大多数情况下都优于两个基线攻击。并且当桶化方案k=2时,在节点数属性上,作者在DD数据集上的DiffPool模型的攻击精度可以达到0.904。

图表7:属性推理攻击实验结果
3.数据集的可转移性:在上述实验中,作者假设辅助数据集来自与目标图相同的分布。为了放宽这一假设,作者还进行了额外的实验,以验证辅助数据集来自与目标图不同的分布时的攻击性能。实验结果表明,此时作者提出的属性推理攻击仍然有效。
子图推理攻击
1. 实验设置:作者使用AUC来衡量攻击性能,并通过三种图采样方法从数据集中获得子图,从而生成正负样本。实验中用于对比的方法直接使用目标模型生成子图嵌入,并单独训练一个二分类器作为攻击模型,以此验证作者在攻击模型中集成嵌入提取器的方法的效果。
2.实验结果:下图说明了攻击性能,其中不同的行代表不同的数据集,不同的列代表不同的采样方法。实验结果表明,作者的攻击在大多数情况下是有效的,特别是当采样率为0.8时。例如,作者在DD数据集和MeanPool模型上用FireForest抽样方法可以达到0.982的AUC指标。并且,本文的子图推理攻击在大多数情况下一直优于基线攻击,特别是当采样率较小时。此外,作者还从特征构建方法、子图采样方法、嵌入模型、数据集等多个方面分析了结果。
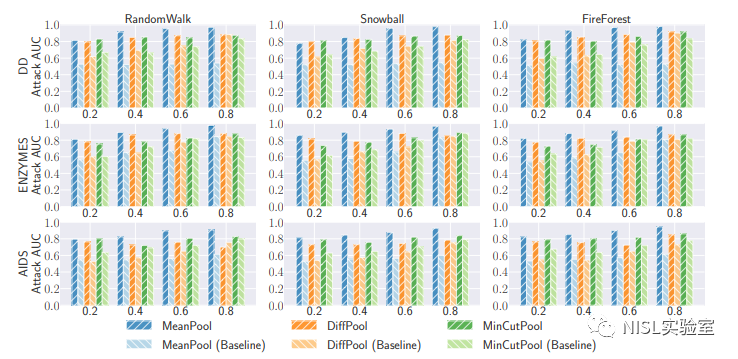
图表8:子图推理攻击实验结果
图重建攻击
1. 实验设置:作者在三个小数据集和三个图嵌入模型上进行了实验,从图同构(使用WL算法近似计算)和宏观图统计量(度分布、局部聚类系数等,用余弦相似度衡量)两方面评估了攻击模型的效果。
2.实验结果:下表说明了攻击模型在图的同构性和图统计量方面的性能。实验结果表明,所提出的攻击可以在这两方面实现高相似性。例如,AIDS和DiffPool上的WL核达到了0.875;AIDS和NCI1数据集上的局部聚类系数分布也可以达到0.99的余弦相似度;并且在所有设置下中介中心性的余弦相似度均大于0.85。对于度分布和紧密中心度的攻击性能略差,但仍能实现余弦相似度大于或接近0.5。
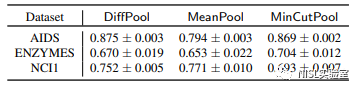
图表9:图重建攻击在图同构性方面的效果
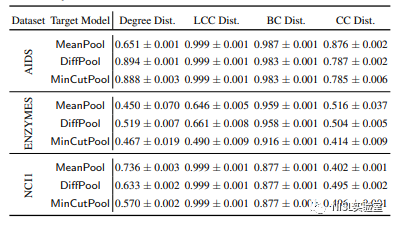
图表10:图重建攻击在图统计量方面的效果
防御措施
1.实验设置:作者通过实验验证了提出的防御措施对所有推理攻击的有效性,以及对正常图分类任务的影响。对于属性推理攻击,作者评估了桶化方案k=2的图密度的性能。对于子图推理攻击,作者考虑了采样率为0.8的RandomWalk采样方法。
2.实验结果:下图说明了对属性推理攻击和子图推理攻击的防御实验结果,其中第一列和第二列分别代表两种攻击的攻击性能,最后一列代表图分类任务的准确性。在每个图中,x轴代表拉普拉斯噪声的尺度参数β,其中较大的β意味着较大的噪声。实验结果表明,当噪声水平增加时,属性推理攻击和子图推理攻击的性能以及图分类任务的准确性都会下降,因为更多的噪声会隐藏更多图嵌入中的结构信息。为了抵御推理攻击,同时保留正常任务的效果,需要合理选择噪声水平。 例如,当将拉普拉斯噪声的标准差设置为2时,子图推理攻击的性能明显下降,而图分类的准确性只是轻微下降。
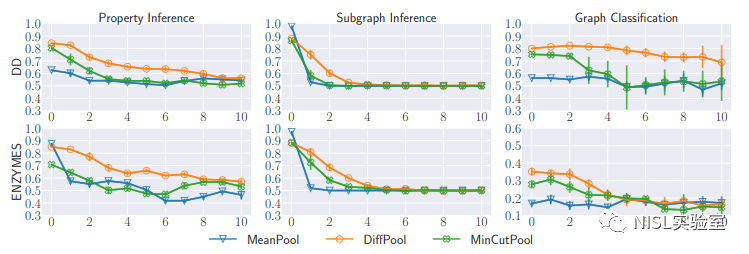
图表11:防御实验结果
05【结论】
本篇论文研究了图嵌入的信息泄露问题。作者提出了三种不同的攻击方式,用于从给定图嵌入的目标图中提取信息,并通过实验验证了攻击效果。作者进一步提出了一种基于嵌入扰动的防御措施,实验结果表明其可以有效地缓解推理攻击,并且在图分类任务中不会出现明显的性能下降。
原文链接
https://www.usenix.org/system/files/sec22-zhang-zhikun.pdf
参考文献
[1] Aditya Grover and Jure Leskovec. node2vec: Scalable Feature Learning for Networks. In KDD, pages 855–864, 2016.
[2] Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. DeepWalk: Online Learning of Social Representations. In KDD, pages 701–710, 2014.
[3] Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. LINE: Large-scale Information Network Embedding. In WWW, pages 1067–1077, 2015.
[4] Congzheng Song and Ananth Raghunathan. Information Leakage in Embedding Models. In CCS, pages 377–390, 2020.
[5] Congzheng Song and Vitaly Shmatikov. Overlearning Reveals Sensitive Attributes. In ICLR, 2020.
[6] Martin Simonovsky and Nikos Komodakis. GraphVAE: Towards Generation of Small Graphs Using Variational Autoencoders. In ICANN, pages 412–422, 2018.
[7] Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. TUDataset: A collection of benchmark datasets for learning with graphs. In GRL, 2020.
[8] Zhikun Zhang, Tianhao Wang, Jean Honorio, Ninghui Li, Michael Backes, Shibo He, Jiming Chen, and Yang Zhang. PrivSyn: Differentially Private Data Synthesis. In USENIX Security, pages 929–946, 2021.
戴鼎璋,编辑&审校|张一铭
声明:本文来自NISL实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
