机器之心报道
近一段时间以来,对话式 AI 模型 ChatGPT 的风头无两。有人用 ChatGPT 写代码、改 bug;还有人用 ChatGPT 写神经网络,做到了一字不改结果很好用。然而,ChatGPT 在学校作业、论文发表等领域引发了人们广泛的担忧,并采取了相应的措施。
1 月初,纽约市教育官员宣布禁止学生在公立学校使用 ChatGPT 的消息引发了争论;人们对 ChatGPT 的担忧已经蔓延到了 AI 学界自身,全球知名机器学习会议之一的 ICML 最近也宣布禁止发表包含由 ChatGPT 和其他类似系统生成内容的论文,以免出现「意外后果」。
针对这些反馈,ChatGPT 的提出者 OpenAI 正在努力开发缓解措施,帮助人们检测由 AI 自动生成的文本。OpenAI CEO Sam Altman 提出将尝试水印技术和其他技术来标记 ChatGPT 生成的内容,但又表示不可能做到完美。
大型语言模型的潜在危害,可通过给模型的输出加水印来缓解,即把信号嵌入到生成的文本中,这些信号对人类来说是不可见的,但算法可以从短范围的 token 中检测到。
本文中,来自马里兰大学的几位研究者针对 ChatGPT 等语言模型输出的水印进行了深入研究。他们提出了一种高效水印框架,水印的嵌入对文本质量的影响忽略不计,可以使用高效的开源算法进行检测,而无需访问语言模型的 API 或参数。此外,本文方法可以检测到比较短的合成文本(少至 25 个 tokens),同时使得人类文本在统计学上不可能被标记为机器生成。

论文地址:https://arxiv.org/pdf/2301.10226v1.pdf
本文中提出的水印具有以下属性:
可以在不了解模型参数或不访问语言模型 API 的情况下通过算法检测,因此即使模型不开源,检测算法也能开源。同时得益于 LLM 不需要加载或运行,检测成本低且速度快;
可以使用标准语言模型生成带水印的文本,无需重新训练;
只从生成文本的连续部分检测到水印,这样当使用生成的一部分创建更大的文档时,水印依然可以检测到;
如果不修改生成 tokens 的很大一部分,则无法删除水印;
对已经检测到的水印计算出严格的统计学置信度。
论文作者:我们有 99.999999999994%信心
马里兰大学副教授、论文作者之一 Tom Goldstein 表示:「OpenAI 正在计划阻止 ChatGPT 用户的一些作弊行为,与此同时,我们通过水印输出的方式来辨别是否由 ChatGPT 生成的内容。在一个具有 1.3B 参数的模型中,一种新的语言模型水印框架在仅 23 个单词中检测出了 LLM 生成的文本,我们有 99.999999999994% 信心检测到。」

有人毫不夸张的表示,这篇论文标志着 LLM 剽窃和反剽窃检查器之间的竞赛已经开始。
该方法的出现,也让网友替学生们捏了一把汗,直呼「振作起来,高中生们!」
在方法介绍部分,首先该研究介绍了一种简单的水印方法(hard blacklist watermark),该水印易于分析、易于检测且难以删除。该方法通过生成禁止出现的 token 黑名单来工作。在检测水印中,生成水印文本需要访问语言模型,而检测水印则不需要。拥有哈希函数和随机数生成器知识的第三方可以为每个 token 重新生成黑名单,并计算违反黑名单规则的次数。

除此以外,该研究还使用了一种称为 soft 水印的检测方法,该算法并没有严格禁止黑名单 token,而是在白名单 token 的对数上增加了一个常数 δ,算法如下:

上述水印算法被设计为公开的,其实该算法也可以在私有模式下运行,使用一个随机密钥,该密钥用来保密并托管在 API 上。如果攻击者不知道用于生成黑名单的密钥,那么攻击者就难以删除水印,因为攻击者不知道哪些 token 被列入黑名单。
研究者表示,该水印检测算法可以公开,使第三方(例如社交媒体平台)能够自行运行,也可以保持私有并在 API 后面运行。
实验
实验使用 OPT-1.3B 模型探索了水印效果。为了模拟各种语言建模场景,该研究从 C4 数据集的子集中随机选择文本进行切片和切块。
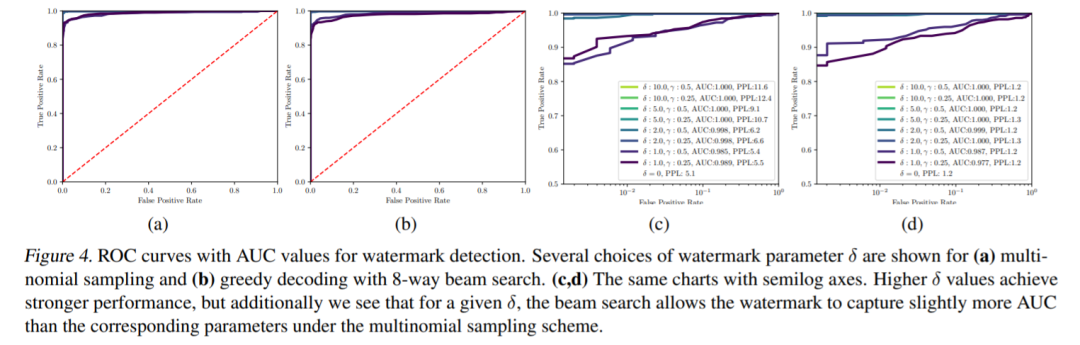
图 2(左)显示了各种水印参数组合的水印强度(z 分数)和文本质量(困惑度)之间的权衡。

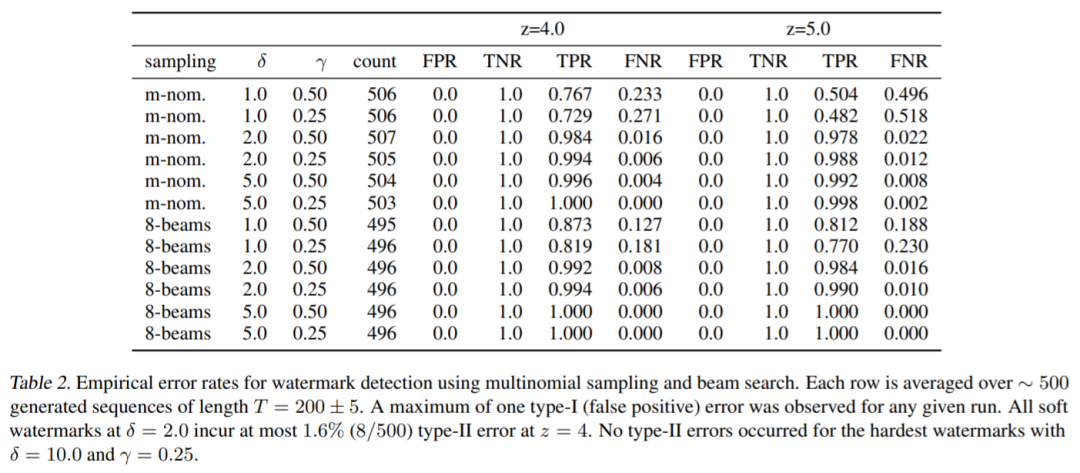
该研究在表 2 中提供了各种水印参数的错误率表,此外,该研究还在图 4 中的 ROC 图表中扫描了一系列阈值。
更多技术细节请参阅原论文。
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
