本文发表于《指挥信息系统与技术》2022年第5期
作者:隋远,段然,白正
引用格式:隋远,段然,白正. 基于XGBoost的船舶仿冒行为监测方法 [J]. 指挥信息系统与技术,2022,13(5):60-65.
摘要
针对水上安全监管中无法有效识别船舶类型的问题,提出了一种基于XGBoost的船舶仿冒行为监测方法。首先,利用船舶历史航迹数据计算得到不同类型船舶的航迹特征;然后,利用XGBoost算法对船舶航迹特征进行训练得到船舶分类模型;最后,提出了一种船舶类型自动检测流程,实现了船舶仿冒行为监测。试验结果表明,该方法对船舶类型分类判断具有较高的分类准确率、较快的训练收敛速度和较高的分类判断效率。
0 引言
随着我国沿海和内河等水域内航行的船舶数量不断增加,涉水部门的监管压力越来越大,为了有效实施船舶的动态监管,涉水监管部门需获得船舶的名称、类型、位置和速度等信息。船舶名称和类型等信息主要依靠船载船舶自动识别系统(AIS)来获取,其中部分船舶(尤其是渔船)存在AIS上报信息不准确的情况。部分渔船在禁渔区或休渔期间,为了经济目的违规开展作业,同时为了逃避处罚而故意上报错误的船舶类型,这对船舶动态管控造成了负面影响。此外,渔船类型仿冒行为存在巨大安全隐患,2016—2018年,全国共发生一般等级以上碰撞事故223起,其中商船和渔船碰撞事故80起,占比35.9%。因此,有效识别仿冒渔船对防范商船和渔船碰撞具有重要意义。
在国际海事组织(IMO)和国际航标协会(IALA)等机构的努力下,正式提出了AIS标准,并强制各船舶安装AIS。AIS数据由船舶在行驶过程中周期性广播产生,具有海量性、时空性和小记录频繁更新特点。正常情况下,在航A类船载设备的AIS数据上报周期小于10s,航速大于2节的B类船载设备的AIS数据上报周期小于30 s,因此AIS数据是海量的。实际船舶监管中,当船舶上报的类型无法采信时,监管人员只能凭经验进行船舶类型估计,其效率和准确率均较低,故该工作方式亟需改进。AIS报文包含了船舶唯一编码海上移动服务标识(MMSI)和船舶类型,以及经纬度、航向、速度与时间戳等信息,不同船舶的AIS数据具有不同特点,这为不同类型船舶的航行特征学习提供了数据基础。本文提出了一种基于XGBoost的船舶仿冒行为监测方法,利用船舶历史航迹数据生成分类特征,训练生成船舶类型的分类模型,对实时航行船舶进行类型预测,从而实现船舶仿冒行为的自动监测。
1 船舶类型分类算法
利用船舶历史航迹数据进行船舶类型判断是有监督学习中的分类问题,目前较典型的算法包括深度学习和提升学习等算法。深度学习善于处理人工难以提取特征的复杂数据(如图像和语音等),而对于已确定特征,深度学习将输入数据在高维空间进行复杂变化以获得分类模型,若变换过程失败,反而会让数据更加交织在一起。提升学习是一种集成学习(EL),其基本思想是将预测精度不高的弱学习器集合成精度高的强学习器,使用弱学习器对样本进行训练,对那些分类错误的样本赋予更大的权重并重新训练,直至得到一个满意的分类模型,常见算法包括Adaboost算法、梯度提升决策树算法(GBDT)算法以及XGBoost算法。由于提升学习善于处理已确定特征的问题,并可提高学习系统的效率,而船舶历史轨迹数据包含速度、位置和航向等确定的特征数据,因此采用提升学习算法可取得更高的学习效率以及成功率。
本文旨在研究一种能够满足海量船舶实时类型判断的方法,这就要求相关算法具有较高的判断准确率和效率。Adaboost算法在每一轮迭代时,对前期分类错误的样本增加权重值以达到提升学习的目的,但由于其对噪声样本过于敏感,而船舶上报数据中存在一定的错误信息,因此Adaboost算法无法更好地完成相关工作。GBDT算法预测准确率高,可较好地处理异常值,但由于GBDT算法在训练时每轮迭代未进行并行化处理,因此在面对海量数据集进行训练时其消耗时间是不可接受的。XGBoost算法可看成是GBDT的工业化改进版本,对噪声数据容忍度较高,且通过在树结构划分时使用近似贪心算法对数据进行排序确定划分点,实现了特征粒度的并行计算,相比于GBDT算法可大幅提升计算速度;XGBoos算法在GBDT基础上增加了正则化项,避免了过拟合;XGBoost算法的目标函数拟合使用二阶泰勒展开,比GBDT的一阶展开更精准,且计算速度更快;XGBoost算法借鉴了随机森林方法,支持在训练时进行样本抽样和列抽样,可增强模型的泛化性。综上,本文将XGBoost算法作为船舶类型判断的基础算法。
2 特征生成
2.1 特征选择


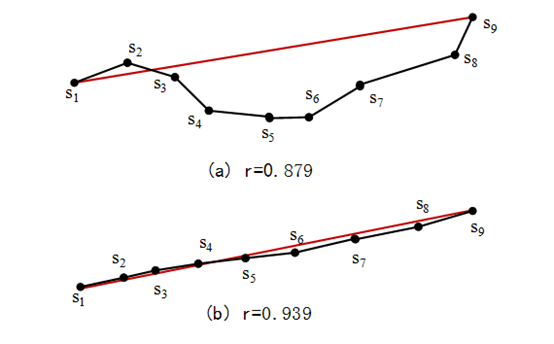
图1 不同航程比条件下的船舶航程曲线对比


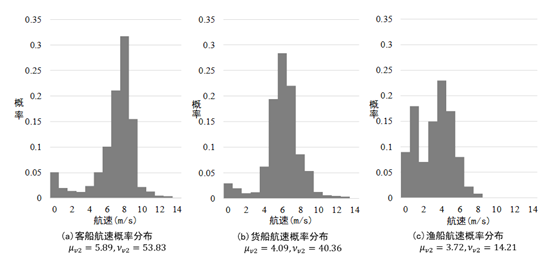
图2 3种船舶航速概率分布及2阶中心矩原点矩示意图

使用0.5 m/s2作为离散化单元来统计客船、货船和渔船随机一段航迹的加速度概率分布,并计算3种船舶航迹的峰度和偏度。3种船舶航速差概率分布及峰度偏度示意图如图3所示,可见,不同类型船舶的连续速度差峰度和偏度有明显区别。
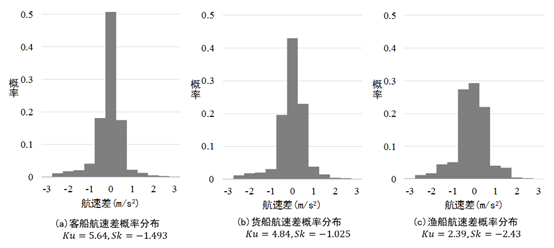
图3 3种船舶航速差概率分布及峰度偏度示意图
2.2 特征计算

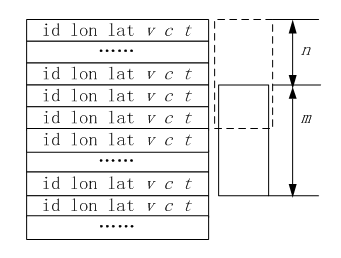
图4 滑动窗口特征计算示意图

3 船舶仿冒行为监测方法
基于XGBoost的船舶仿冒行为监测方法(本文方法)包括以下3个步骤:1) 对船舶历史数据中连续航迹动态点数据进行处理以生成特征数据集;2) 通过提升学习算法构建分类器,训练生成不同类型船舶的航行特征模型;3) 通过船舶特征模型对实际船舶目标实时计算的分类特征进行类型判断。本文方法整体流程如图5所示。
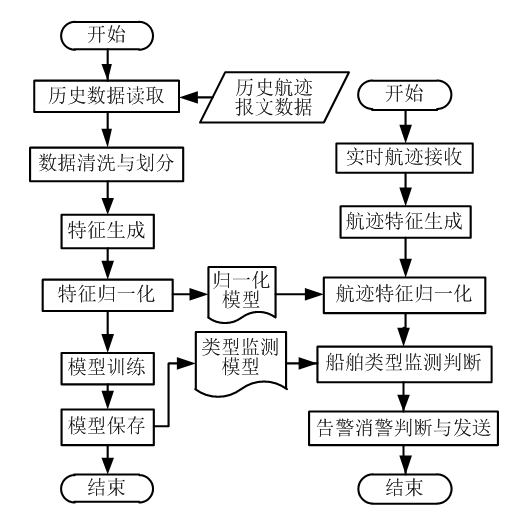
图5 本文方法整体流程
3.1 模型生成
为提升XGBoost算法模型的分类精度,本文使用二分类方式进行模型训练。每次模型训练均使用渔船及另一种需判断类型的船舶作为,其中,渔船为负样本,另一种船舶为正样本。为有效检测出仿冒其他船舶的渔船,本文对集成学习的评估函数进行了扰动修改,增加了对应类型的权重,加速了训练迭代过程。实践中,可在计算评估函数值时对判断错误的渔船样本增加权重,以增加错误判断渔船类型时评估函数的值,使得模型训练更加倾向于减小渔船误判率。渔船误判率公式如下:

XGBoost算法模型生成步骤如下:
1) 按船舶类型对全部数据进行划分,每种类型的船舶报文数据去除异常点后,按船舶id和时间2个值由小到大进行排序,并将排序后的船舶类型数据分别存储为文件。
2) 读取一种类型船舶数据并进行航迹分割,前后2条报文数据满足以下任一条件则进行1次分割:船舶id不同;时间差超过300 s;距离超过500 m。
3) 对分割后的类型船舶连续航迹进行数量筛选,去除其中航迹点数量少于60个点的连续航迹;
4) 取一段航迹,设置大小为60且步长为5的滑动窗口进行特征计算,对全部连续航迹数据完成特征计算后将特征值存入样本文件。
5)重复步骤2)~4)对全部船舶类型的报文数据进行处理并完成特征值计算,得到所有类型船舶的特征样本。
6) 读取渔船和另一种船舶的样本文件,将渔船作为负样本并将其他船舶作为正样本,生成对应的二分类标签,样本均衡后将样本文件混合。
7) 将样本进行归一化处理并保存归一化模型,选择归一化后样本的90%用于模型训练,10%用于模型评估。
8) 构建XGboost分类训练器,设置分类器超参数及训练终止条件,将训练样本输入分类器进行模型训练,使用式(9)作为评估函数对评估样本进行评估。
9) 重复步骤8)对分类器超参数进行调整,使评估函数值最低,保存此时训练得到的模型。
10)重复步骤8)~9)对除渔船外的全部类型船舶数据进行处理,完成全部船舶与渔船的二分类模型训练,得到分类模型和归一化模型。
3.2 仿冒监测
本文方法对船舶进行仿冒监测时,需先接收和记录实时船舶航迹报文并计算生成实时船舶航迹报文的待判断特征样本,再输入分类模型进行判断。例如,若上报类型为非渔船的船舶特征被分类模型预测为渔船,则该船舶判定为可能是渔船仿冒。采用本文方法生成实时特征样本的步骤如下:
1) 对于AIS上报船舶类型为非渔船的船舶,记录其航迹点报文;
2) 读取船舶的历史航迹点报文,如果满足长度超过60个点、连续航迹点之间时间差不超过300 s以及距离差不超过500 m等条件,则计算1次特征;
3) 对于满足步骤2)的船舶,利用2.1节中公式计算最近60个历史航迹点的航程比、航迹重心和时间中值,计算最近60个历史航迹点航速序列、航向序列、连续航速差序列和连续航向差序列离散化统计后的中心矩与原点矩以及峰度与偏度;
4) 对于步骤3)计算得到的特征,使用3.1节中步骤7)得到的归一化模型进行归一化,得到最终用于类型判断的特征。


图6 仿冒行为监测流程
4 试验结果与分析
4.1 试验设计
为从历史数据中筛选出渔船、客船、货船和油轮等类型,本文进行了仿真试验。仿真试验的操作系统环境为CentOS 7.4,开发语言为Python 3.6,XGBoost算法包版本为Python API 0.81。训练平台的中央处理器(CPU)为Intel Xeon E5-1620 3.5 GHz,内存为32 GB。试验数据为某海事区域连续2个月的AIS数据,共约9千万条数据,其中90%的数据用于训练模型,10%的数据用于验证模型。本文进行了以下2个试验:
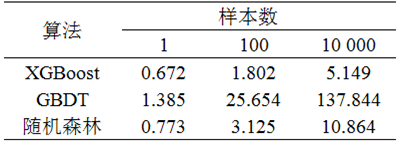
1) 试验1:使用全部AIS数据,通过XGBoost算法、GBDT算法和随机森林算法构建分类器,使用本文方法生成训练和评估特征样本,并训练生成分类模型。每次模型训练均使用十折交叉进行验证。该试验对比了3种算法的训练时间、模型大小和模型准确率,以及每种算法模型对随机样本的检测判断速度。
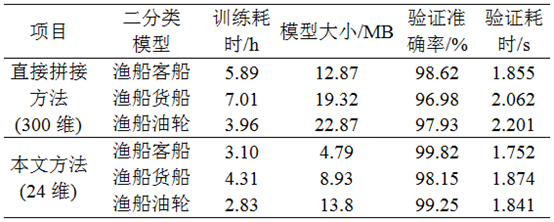
2) 试验2:使用全部AIS数据,通过滑动窗口方法将数据中连续60个点的经纬度、航速、航向和时间数据项直接拼接成300维的特征,与本文方法生成的24维特征进行对比。每次模型训练均使用XGBoost算法构建分类器对超参数进行调整,并使用十折交叉进行验证。试验对比了直接拼接方法(300维)和本文方法(24维)的模型训练速度、模型尺寸、分类准确率,以及对验证集样本的分类判断耗时。
4.2 结果分析
试验1中,使用3种算法对模型进行训练,其试验结果数据对比如表1所示,其中二分类模型包括渔船客船、渔船货船和渔船油船。由表1可知,XGBoost算法在模型准确率上与GBDT算法接近,但其训练速度快于GBDT算法;XGBoost算法与RandomForest算法训练速度接近,但准确率略高,且模型尺寸较小。本文使用3种算法训练得到的模型对样本进行类型预测,并对样本分类判断耗时进行了分析。不同样本数下的检测耗时如表2所示。由表2可知,XGBoost算法无论是在小规模还是在大规模数据的检测判断方面,其效率均优于GBDT算法和RandomForest算法,是实时船舶类型仿冒监测的理想算法。
表1 3种算法试验结果数据对比

表2 不同样本数下的检测耗时
试验2中,使用直接拼接方法(300维)和本文方法(24维)训练和验证样本,并使用XGBoost算法构建分类器,试验样本数为100。2种特征生成方法试验结果对比如表3所示。可见,与直接拼接方法相比,本文方法在进行船舶类型分类判断时具有更高的分类准确率、训练收敛速度和分类判断效率,可实现对船舶仿冒行为的有效监管。
表3 2种特征生成方法试验结果对比
5 结束语
针对部分船舶通过篡改AIS设备信息来仿冒其他船舶的违法行为,设计了一种基于XGBoost的船舶仿冒行为监测方法,并进行了试验验证。该方法接入实时船舶数据后,能够检测出仿冒船舶的航行特征与被仿冒类型船舶的航行特征不相符,并生成船舶仿冒行为预警。试验结果表明,本文方法提取的特征对客船、货船和邮轮之间的区别不明显,后续将对更多类型船舶的特征进行分析,使本文方法对其他类型船舶进行准确分类。
相关文献推荐
隋远,段然,朱德理. 基于深度孪生网络的船舶名称匹配方法[J]. 指挥信息系统与技术,2022,13(3):32-35.
张桂林,吴蔚,徐建,等. 基于规则引擎的海上编队目标识别推理[J]. 指挥信息系统与技术,2022,13(3):28-31.
杨旺奇,刘俊,陈振,等. 基于深度学习的船舶标识号识别方法[J]. 指挥信息系统与技术,2022,13(1):58-63.
戚志刚,赵玉林,徐英桃. 航母编队指挥信息系统海战场环境需求及其应用[J]. 指挥信息系统与技术,2021,12(2):32-37.
郭钽,徐建安,刘锐. 空运大型方舱车纵向通过性计算与运动学仿真[J]. 指挥信息系统与技术,2021,12(4):97-102.
周烨,俞剑,崔化超,等. 基于数值计算的水下目标回波仿真[J]. 指挥信息系统与技术,2020,11(6):87-90.
张晔,樊午洋,化青龙,等. 基于三维模型的SAR 舰船仿真与运动状态识别[J]. 指挥信息系统与技术,2020,11(4):89-95.
朱辉,周洋,邵玮炜. Φ‑OTDR分布式光纤传感器的振动应变监测[J]. 指挥信息系统与技术,2020,11(2):74-79.
韩晓宁,张由余,王君. 智慧船舶交通管理系统发展与应用[J]. 指挥信息系统与技术,2019,10(4):8-13.
赵为春,潘乐义,侯惠峰. 空管信息网传输性能监测与故障定位技术架构[J]. 指挥信息系统与技术,2019,10(1):13-18.
声明:本文来自防务快讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
