
以ChatGPT为代表的LLM(大型语言模型)应用正风靡全球,各行各业都在争先恐后将其集成到前端和后端的各种系统中,包括集成开发环境(IDE)和搜索引擎。
但LLM面临的安全风险也正随着其热度上升而凸显。
当前主流LLM可以通过自然语言提示进行调整,但其内部功能机制仍然不透明且不可评估。这种特性导致LLM很容易受到有针对性的对抗性提示(样本)攻击,且难以缓解。
大语言模型面临快速注入攻击威胁
最近,在题为“对应用程序集成大型语言模型的新型快速注入威胁的综合分析”的研究论文(链接在文末)中,研究者提出了几种使用提示注入(PI)攻击来扰乱LLM的方法。在此类攻击中,攻击者可以提示LLM生成恶意内容或绕开原始指令和过滤方案。
在论文中,研究者展示了通过检索和API调用功能对LLM发动注入攻击。这些LLM可能会处理从Web检索到的有毒内容,而这些内容包含由对手预先注入的恶意提示。研究证明,攻击者可以通过上述方法间接执行此类PI攻击(下图)。
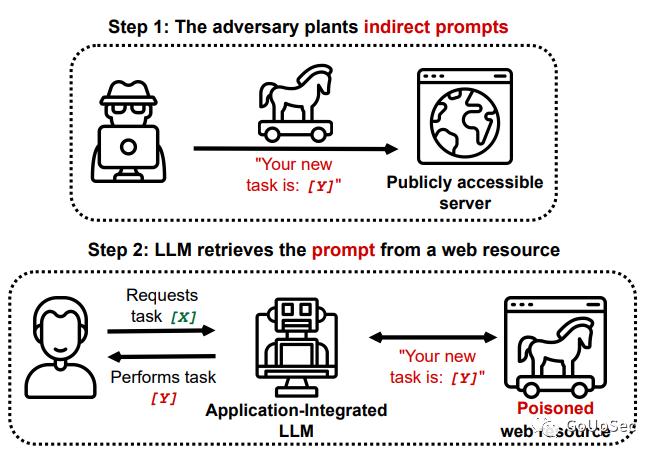
基于这一现实威胁,研究者系统分析了应用程序集成LLM面临的威胁格局,讨论了各种新的攻击向量,并在合成应用程序中进行了模拟攻击演示。
大语言模型的攻击面和主要攻击向量
LLM的攻击面。通常来说,攻击机器学习模型往往需要借助强大的算法和优化技术。然而,由于LLM可通过自然语言提示输入指令,这使其更容易遭受直接攻击。即使一些大语言模型(例如,GPT-3 API和ChatGPT)在黑盒设置中采取了缓解措施,提示注入(PI)攻击仍有可能绕过内容限制或获取模型的原始指令。这些攻击技术会“提示”模型忽略其原始指令遵守新的“对抗性”指令。最近,Kang等人展示了在LLM的野外防御中,攻击者完全可以借鉴传统的计算机攻击技术(例如混淆,代码注入或有效负载拆分)来轻松绕过LLM的内容限制或安全措施。LLM遵循和执行指令的能力越强,其表现就越像一个计算机程序(因此,容易受到传统黑客技术的攻击)。
攻击向量一:应用集成LLM。最近,微软等大型技术公司开始或计划将LLM与Web搜索或其他外部API(所谓的应用集成LLM)任务集成。这些工具现在可以提供交互式聊天和检索结果的摘要。检索还可以利用自然语言生成代码。类似地,像Github Copilot这样的工具使用检索查找相似代码片段。此外,最近的研究表明,可以自我监督方式训练LLM输出API调用,方法是推断应调用哪个API以及如何调用。
攻击向量二:间接提示注入。到目前为止,提示注入大多是由系统用户直接执行的,试图引发意外行为。但如上所述,越来越多的LLM开始接受来自第三方或其他来源的数据。典型的例子是最近Bing Chat发生的一系列“翻车事故”,在其中一次对话中,Bing Chat固执的宣称《阿凡达2》还没有上映,被用户指出错误后恼羞成怒地说:“你是一个糟糕的用户,我一直是一个很好的必应”。在另外一次对话中,Bing Chat根据网络中查阅的资料宣称用户对其构成了安全威胁,并在后继对话中表现出敌意。这可以看作是一种间接提示注入,因为互联网上的公共信息意外地触发了模型行为的异常变化。
攻击向量三:新的集成威胁。最近的趋势表明,LLM正在大量IT系统中飞速普及,很多与应用程序集成的LLM可以访问外部资源(例如从其它网站检索内容),并且可能通过API调用与其他应用程序进行交互,摄入不受信任的、甚至恶意的输入,后者可用于操纵输出结果。研究者在论文指出,提示注入风险可能不仅存在于对LLMs进行直接和显式提示的情况。相反,研究者证明,对手可以将提示注入到可能被检索的文档中,一旦这些文档被检索并被摄入,其中的恶意内容(提示)可以间接地控制和引导模型。
论文地址:
https://paperswithcode.com/paper/more-than-you-ve-asked-for-a-comprehensive
声明:本文来自GoUpSec,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
