作者
中信证券股份有限公司信息技术中心
岳丰 王哲 刘殊玥 余怡然 方兴
中信证券股份有限公司(以下简称“中信证券”)在各项业务展业过程中,需要及时、准确地处理海量非结构化数据。围绕数据加工的全生命周期,中信证券综合应用OCR、NLP、RPA、搜索引擎、知识图谱等AI技术,在非结构化数据识别解析、自然语言理解与结构化处理、非结构化知识存储与检索等方面,开展公司级非结构化数据处理平台建设。
一、非结构化数据处理需求
随着企业数字化转型的持续深入,证券公司在客户服务和内部管理中需要更加快捷有效地处理各种海量数据。统计表明,企业数据有80%以上都是以非结构化的形式存在,且占比还在持续扩大。当前,中信证券非结构化数据处理需求场景非常广阔,几乎覆盖所有业务部门,但公司已有的系统主要针对结构化数据处理,急需建设分析、处理、挖掘非结构化数据的技术平台,从海量数据中挖掘价值。
非结构化数据加工处理全生命周期可划分为数字化、结构化、知识化和业务应用四个阶段,各阶段需要解决以下关键问题。
1.在数字化阶段,需要实现海量多格式文档的数字化
文档作为证券公司使用最多的非结构化数据格式,特点是数据量大、格式繁多、内容多样、专业性和时效性强。中信证券各部门文档识别解析需求量巨大,但缺少统一平台支持,多依赖人工处理且消耗较高时间成本。海量多格式文档的数字化需求主要涉及以下内容:对扫描PDF或图片,基于OCR识别完成数字化,对不同类型文件采用全文识别、模板识别、表格识别等方法处理;对可提取文字文档进行全文解析,适配双层PDF、DOC/DOCX、PPT/PPTX、XLS/XLSX等常见格式;开发文档版式分析工具,解析标题、段落、图表等要素及位置,帮助回溯预览。
2.在结构化阶段,实现自然语言的结构化和语义理解
证券公司非结构化数据的内容主要是自然语言。与机器语义不同,自然语言具有多样性和歧义性,应用中需要从非结构化文本中,抽取各种结构化信息,并理解文本的语义。中信证券主要关注两方面需求:一是基于命名实体识别、关系抽取、属性抽取、文本分类等NLP算法,抽取实体、关系、属性、类别等结构化信息;二是基于深度语义表示学习,计算单词、句子、文章等的语义向量表示,从而度量语义相似性。
3.在知识化阶段,实现非结构化知识的存储与检索
中信证券从三个方面对非结构化知识进行管理:一是提供非结构化数据的统一存储和权限控制功能;二是基于搜索引擎技术,对公司研报、规章制度、技术文档等重要非结构化知识自动构建倒排索引,除支持关键词全文搜索外,还开发了自动摘要、主题抽取、情感分析、语义模糊搜索等功能;三是基于抽取的实体、关系和属性构建知识图谱,特别是在元数据管理场景下,研发针对血缘图谱的查询和展示功能。
4.在业务应用阶段,在复杂流程中实现应用非结构化数据处理
在业务应用中,很多非结构化数据处理场景是嵌在既有复杂流程中的,必须同现有流程管理工具密切配合。为此,需要拓展基础版RPA流程,开发供RPA调用的脚本和API接口,将OCR、NLP等AI能力深度融合到流程环节中,增强版“RPA+AI”流程是迈向超自动化流程管理的重要探索。
二、非结构化数据处理平台体系架构
2020年,中信证券开展非结构化数据处理平台建设,依托文档智能、知识管理和数据管理三个数据应用系统,为公司财富管理、资产管理、清算、库务、合规、风控、证券金融、自营投资、中信香港、信息技术等十多个部门提供服务,初步实现了服务全公司非结构化数据处理的愿景,并取得了显著经济效益和社会效益。中信证券综合应用AI代替人工处理非结构化数据,实现了降本增效,目前已节省成本数百万元;建设了多种非结构化知识的统一管理系统,可提供强大的知识构建、检索、分析功能,满足客户和员工的不同需求;研发多种通用的非结构化数据处理功能,充分赋能企业数字化转型。
依据非结构化数据加工处理逻辑,中信证券非结构化数据处理平台体系架构包含以下四个功能层(如图1所示)。
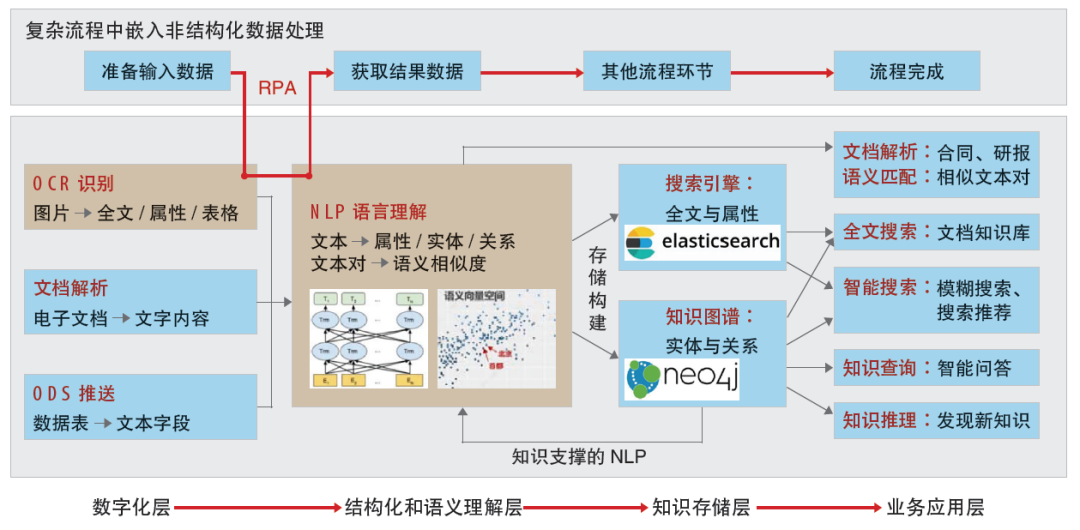
图1 中信证券非结构化数据处理平台体系架构
数字化层:完成数字化是后续数据处理的基础,主要是基于OCR识别技术,准确识别各种扫描文档中文字、表格、布局等信息;此外,还包括非结构化数据的自动推送、电子文档解析等相关功能。
结构化和语义理解层:关注非结构化数据向结构化信息的转化。使用各种NLP技术,抽取各种文本结构化信息(实体、属性、关系等)、理解单词/句子/文档等的语义并计算语义相似度。
知识存储层:从非结构化数据中提取知识,对知识进行有效管理和检索,建设各种企业知识库。使用搜索引擎技术和知识图谱技术,前者适合存储长文本知识支持全文搜索;后者利用图谱存储知识,支持对图数据的灵活查询与计算。
业务应用层:在各种业务问题中应用非结构化数据处理能力,综合利用前三层处理能力和数据结果赋能业务系统,提升用户体验;针对复杂流程中的非结构化数据处理,研发多个融合OCR、NLP等AI能力的增强版RPA流程。
三、平台支撑典型案例介绍
基于非结构化数据处理平台的能力支撑,中信证券为满足各业务线需求已成功研发十余项非结构化数据解决方案,本文重点介绍四个典型案例。
1.研发证券业务表单智能识别,提升效率及可靠性
在很多证券业务活动中,需要处理大量纸质表单,完成交易下单、清算对账、产品估值、运营统计等任务。通过机器准确识别表单扫描件,将图片信息数字化,能够显著提升业务执行的效率及可靠性。中信证券在表单智能识别领域进行了深入探索,并将该技术应用在资产管理、库务、证券金融、清算、自营投资等多个部门。以资产管理部交易单识别为例,实现过程中重点解决了以下两个方面的技术挑战:
一是模板分类及新模板发现。不同资管客户会使用多种模板制作表单,这些表单常混合在一起处理,如果能够先确定表单归属的模板或者判定其属于新模板,就能利用特定模板知识,设计更为准确可靠的识别模型。基于多模态深度学习模型,提出一种模板分类及新模板发现模型(如图2所示),模型综合利用表单的文本信息、企业徽标(Logo)信息、版面布局信息,预测模板类型。对于文本信息,主要考虑标题部分内容(标题中可能包含企业名称或特定用词便于判断归属模板)通过Transformer模型编码,得到文本的向量表示。企业徽标信息是典型的图片信息,基于计算机视觉中的VGG模型强大的图像特征抽取能力,得到徽标的向量表示。版面信息需要进行转化处理,将整张表单不同的版面类型(标题、表格、解释说明、徽标、空白等)区域按各种单色编码,从而将版面信息转化为单色组合的图片,采用简单CNN网络即可有效抽取具有判别性的特征。模型对文本、徽标、版面这三类信息的向量表示进行融合拼接,最后通过全连接层(softmax),给出最终分类结果(新模板单独作为一类)。
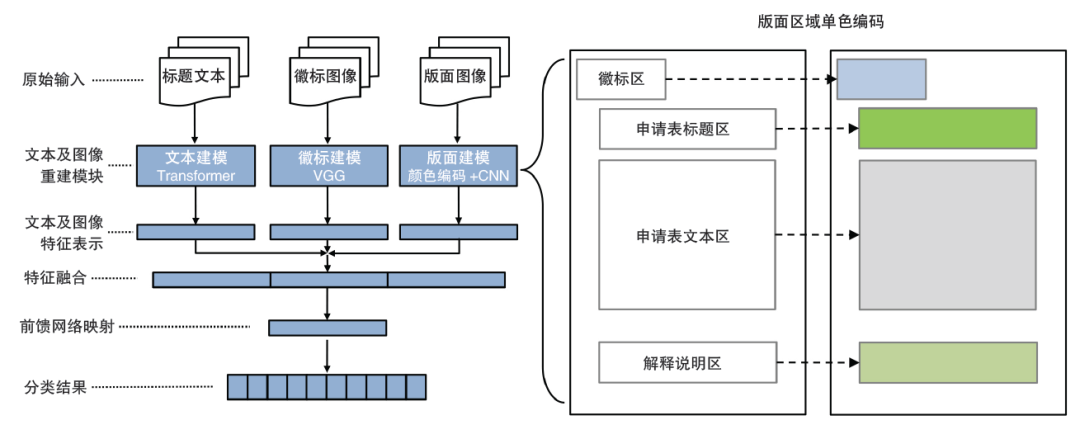
图2 模板分类及新模板发现的多模态深度学习模型
二是基于多模态信息的属性识别。对于每种模板的交易单,准确识别关键下单属性信息。综合利用文本内容、表格布局及单元格坐标、颜色搭配、字号与字体等多模态信息,对交易单中的多个属性进行统一抽取。充分利用公司大量的历史交易单样本,研发属性识别算法,一方面自动归纳了很多判别性很高的规则模板,对大多数实例直接计算属性;另一方面训练深度学习模型,对规则不能覆盖的少数特例给出属性预测结果。目前,识别准确率和覆盖度均达到95%以上。由于交易单对客户、标的、金额等属性识别准确度要求极高,中信证券研发了结果在线审核功能,向交易员清晰呈现属性信息和交易单原件的对应关系,提供勾稽关系预警、异常取值范围预警等机制,醒目提示可能的识别错误,可以灵活修改识别结果,将最终确认结果导出或直接对接交易系统。交易单识别及审核功能上线以来,已经处理了近万份申请单,每单处理时间从几分钟缩短到十几秒钟,显著提升了效率,并降低了当客户交易请求集中提交情况下难以全部按时下单的操作风险。
2.研发CRM智能语音助手,提升移动端用户体验
客户关系管理(CRM)系统是证券公司管理客户信息和关系的主要系统,提供客户业务全景画像、员工及分支机构经营指标统计、内外部商机资讯收集与分发等核心功能,帮助客户经理更好助力客户创造价值。为支持移动场景下的客户服务,中信证券研发了移动端CRM。由于手机屏幕显示、输入、操作等的局限性,相比PC端,移动端CRM在人机交互方面面临更多挑战。例如,CRM提供的功能繁多且层次复杂,用户移动屏操作难以快速定位功能;机构管理者难以实时查询多种统计指标;客户筛选功能需要按众多标签和属性过滤目标客户、移动端做筛选的体验不佳。
为应对上述挑战,利用语音输入的灵活性,通过语音识别、自然语言处理等技术,中信证券研发了智能语音助手功能(如图3所示),并将其集成到移动端CRM产品中,显著提升了用户体验。具体实践中,智能语音助手综合运用了以下多种NLP技术。
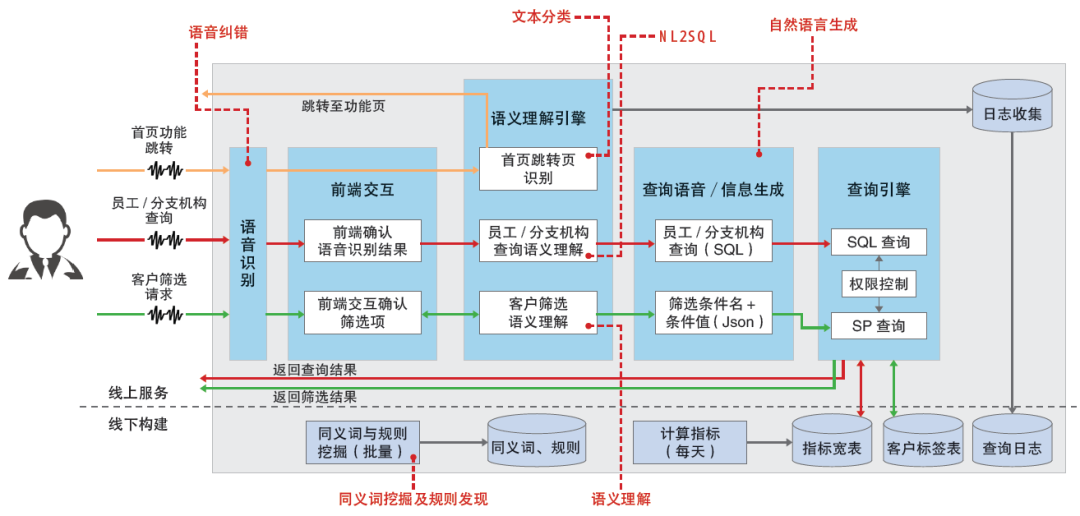
图3 中信证券CRM智能语音助手功能架构
语音纠错:对因环境噪声、方言等导致的语音识别错误,进行自动纠错。
文本分类:识别用户口语化表达的希望跳转的功能页面。
语义理解:理解用户的各种客户筛选条件,提取属性名称及属性值。
NL2SQL:理解自然语言的指标查询请求,转化为SQL代码进行查询。
自然语言生成:将各种结构化系统查询结果,生成恰当的自然语言表达。
同义词挖掘:基于用户日志和领域知识,挖掘标准名称的口语化同义词。
智能语音助手对移动端交互痛点均提供强有力的解决方案。以客户筛选为例,基于语义理解,从用户多样化的口语输入,准确判断筛选条件的名称或取值,配合前端操作灵活增加/修改/删除筛选条件,快速准确返回目标查询结果。
3.研发企业非结构化文档知识库,提供统一知识服务
在证券公司各业务部门的日常工作中,大量文档数据(研究报告、年报/财报、各项规章制度、各种业务常见问答知识、IT技术文档等)不断产生,构成类型丰富的行业非结构化知识源。这些文档数据中包含大量有价值知识,但以往缺少统一解析、存储、查询、分析工具,无法充分展现知识数据的价值。本项目综合运用文档解析、智能搜索引擎、自然语言处理、数据可视化等先进技术,对典型文档类型研发统一知识管理系统,为多项业务提供知识服务。下文具体介绍两种知识库:
(1)研报知识库。券商研报由研究员撰写,是证券公司拥有的重要知识资产。研报多为PDF文件,同一家证券公司的券商研报在内容和格式都上具有规律性,通过定制研报解析工具,能够准确解析包含的细粒度结构,包括标题、类别、正文、表格、插图等;从正文内容中解析核心观点、风险分析、投资建议等常见段落,并且将表格、插图与正文段落建立关联。在准确解析研报细粒度知识基础上,对研报全文及各种附加信息建立全文索引,能够智能检索包含输入的全文内容并精准定位到原文段落,通过语义相似计算及金融领域同义词还能够给出语言相似的研报段落。从研报全文内容中挖掘有价值的信息也是本案例重点关注的问题,基于NLP关键词提取模型计算每篇研报关键词,通过单词热度打分算法,对给定时间尺度下的研报集合归纳热门话题词并通过词云可视化展现,使相关员工通过点击热词即可获取有价值的资讯。
(2)规章制度知识库。规章制度管理是公司合规工作的重要组成部分。针对以往制度管理中存在的问题,中信证券建设了规章制度全生命周期管理系统,为全公司提供规章制度知识库。该系统具有三方面优势:首先,制度知识库通过与OA系统的深度集成,确保与制度发布审批流程联动更新,保持较高的数据时效性;其次,针对规章制度历史版本管理,研发了制度文档的匹配和比对功能,挖掘同一制度的不同版本及修订内容,确保制度信息收录全面性;最后,规章制度信息检索方面,支持按内容全文检索和按类别、部门等标签过滤,通过用户搜索日志和互联网外部信息,对专业词汇挖掘同义表述从而支持模糊搜索和相关搜索词推荐,为用户提供快捷和智能的检索服务。
此外,知识管理系统还分别针对带权限约束的文档集合、业务和运营FAQ知识、IT技术文档等非结构化数据建设多个知识库,将大量结构化知识与日常工作紧密联系起来。
4.建设企业级数据血缘图谱,服务公司数据治理
中信证券现有几百套信息系统,服务于公司各项业务及管理工作,这些系统的数据异构性巨大,且系统之间存在复杂的数据依赖关系。证监会于2018年颁布了《证券基金经营机构信息技术管理办法》,明确要求相关机构需建立健全数据全生命周期管理机制,切实履行数据质量管理职责,不断提升数据使用价值;中信证券内部也发布了《数据治理管理办法》《数据质量管理实施细则》,将数据治理及数据质量列为公司重要的管理工作内容。
元数据及数据血缘分析是数据治理的重要组成部分。简单来说,元数据就是“描述数据的数据”,如系统名、数据表名、字段名等,能够表达不同粒度下的数据对象;数据血缘能够刻画元数据之间的各种依赖关系,通过溯源查询、影响查询等分析手段,提升数据质量。公司内部多系统的元数据及其血缘关系,构成了复杂的图数据结构,是一类典型的非结构化数据,使用关系型数据库难以有效支持血缘分析。本案例基于知识图谱技术对其进行建模,将元数据视为节点,将直接关联关系视为边,利用各种图计算和挖掘算法实现血缘分析问题。
中信证券采用增量方式建设企业级数据血缘图谱,图谱主要可分为两类:第一类是单个IT系统内部的血缘关系图谱,第二类是多个系统之间血缘关系图谱。单系统血缘图谱构建的核心技术是SQL解析,从多种数据库的SQL语句中计算出数据表、字段等血缘关系,目前已针对监管报送、风险管理、证券金融、客户指标库等多个系统构建单系统血缘图谱。另外,中信证券全公司范围内200多套IT系统通过大数据平台ODS等基础设施不断传递数据,构成了一个更大范畴的复杂网络(如图4所示),将单系统血缘图谱建设方法成功推广到多系统间血缘图谱构建中,建立了系统与系统、系统与数据表、数据表与数据表的血缘关系。利用多系统血缘图谱,可以查询某个系统中数据表以及影响其他系统的相关数据表,当源头数据表发生变化时提醒所有受影响系统的管理员,及时做好数据管理。
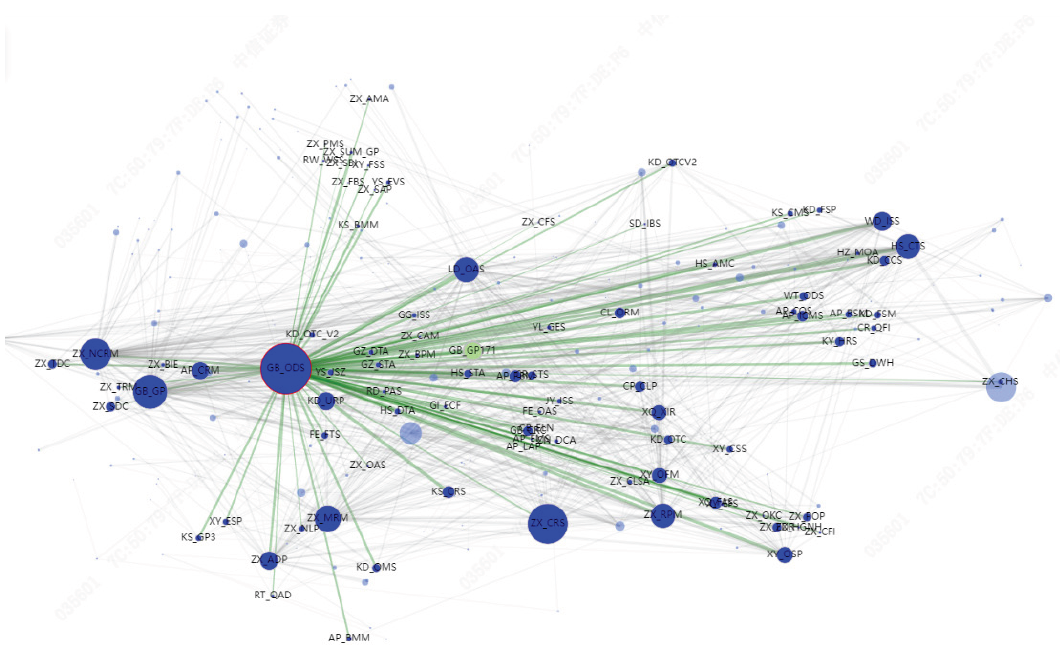
图4 多系统间血缘图谱及影响查询网络示意
四、结束语
中信证券围绕海量非结构化数据全生命周期处理的需求,综合应用多种人工智能和大数据技术,建设了公司级非结构化数据处理平台。目前,该平台已成功服务公司多个部门,实现了显著节约成本、提升效率的预期效果;同时,集成了通用表格识别、文本信息抽取、深度语义匹配、企业知识搜索引擎、数据血缘图谱构建与查询等多种通用能力。中信证券非结构化数据处理平台建设是证券业数字化转型的一次有益探索,具有较高的行业推广价值。
本文刊于《中国金融电脑》2022年第4期
声明:本文来自中国金融电脑+,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
