作者:中国工商银行金融科技研究院数字化银行实验室
信用卡欺诈对许多金融机构来说是一个棘手的问题,尽管金融机构基于机器学习算法构建了各种欺诈检测系统,部分欺诈者仍然可以避开欺诈检测,因为这些系统通常不包含有关对手了解欺诈检测机制的信息。为了将欺诈者不断扩充的知识库信息纳入自适应欺诈检测系统,本文基于信用卡欺诈检测动态模型研究项目(以下简称“项目”),探索使用博弈论对抗学习方法来模拟欺诈者的最佳策略,并先发制人地调整欺诈检测系统,提升其应对潜在威胁的能力。
金融机构可以通过对欺诈者的可能策略进行建模来先发制人地重新训练模型,这种动态模型在检测信用卡欺诈交易方面优于静态模型。随着博弈轮次的增加,对抗性学习模型与静态欺诈模型的AUC(Area Under Curve)分数逐渐拉开差距,由此可证,通过了解自身模型的弱点,对抗性模型能够优先调整分类器,以提供更好的防御机制来检测欺诈行为,这为金融机构提升信用卡欺诈检测系统性能提供了探索的方向。
项目使用逻辑回归分类器进行欺诈检测,最初根据未检测到的欺诈交易的数量确定欺诈者的最佳策略,并假设其在未来的交易中使用该策略,以改进最初的分类器。测试结果显示,与金融机构通常使用的静态模型相比,这种基于对抗框架的动态模型在多次迭代后能在验证集上产生更高的AUC分数,即模型正确率更高。
一、问题引入
在金融行业的许多领域,基于机器学习算法的分类系统正逐步建立,用于打击欺诈和其他恶意行为。目前,常规的欺诈检测系统已开始利用大量常见的机器学习算法,如逻辑回归、支持向量机、随机森林模型、神经网络、遗传算法、隐马尔可夫模型及无监督类型算法,这些模型在检测欺诈方面最初都是有效的。然而有些欺诈者依旧能够逃避系统的鉴别,由此导致的违规行为每年给金融机构造成巨大的经济损失,并损害金融机构的声誉。这是因为,在金融机构建立欺诈检测系统的同时,欺诈者也在探索分类系统以生成未被检测到的欺诈交易。例如,欺诈者可以购买数千个信用卡卡号,用于测试和学习金融机构建立的欺诈检测系统,进而调整欺诈策略。此时,如果不重新采集样本进行训练,欺诈检测系统的性能可能会随着欺诈者欺诈策略的调整而逐渐下降,同时欺诈检测系统的维护成本也会随之提高。
目前,虽然金融机构部署了许多欺诈检测系统,但很少有系统在尝试改进防御时主动结合欺诈者的潜在策略。一种合理的推测是:了解欺诈者的最佳策略有助于部署更健壮的系统并创建自适应模型。因此,项目研究的目标是研发一种自适应的、持续改进的模型,以预测欺诈者的最佳策略并先发制人地与之对抗,从而提高该模型在欺诈检测中的性能,使其优于目前使用的其他模型。
二、研究思路
“对抗性学习”(Adversarial Learning)主要研究如何通过对手之间的交互,提升当前主干模型的性能,有时也结合博弈论进行建模,是机器学习的一个新兴领域。目前已经有很多学者实现了对抗性场景的不同建模,这些模型在“模型欺骗者”关于分类系统的知识量方面做了不同的假设:有的假设“模型欺骗者”完全了解分类器,这种假设不适用于欺诈检测场景;有的假设“模型欺骗者”对分类器的了解不完整,因此需要引入对抗性分类器逆向工程(Adversarial Classifier Reverse Engineering,ACRE)方法;还有的实施基于斯塔克尔伯格(Stackelberg)博弈论模型,认为要达到平衡,“模型欺骗者”和模型(分类器)都需要以最佳策略进行博弈。
早在2009年就有学者利用博弈论模型、ACRE方法和马尔可夫过程(Markov Process)来模拟欺诈者和分类器之间的交互,他们将博弈论框架扩展到欺诈检测中的真实数据集,进而实施最有效的对抗策略并在多轮游戏中重新训练分类器。
在前沿的动态欺诈检测系统建模研究方面,有一种较为先进的模型采用双层架构,第一层是基于规则的组件,第二层是博弈论组件,将欺诈者的策略建模为两态马尔可夫过程,并使用高斯混合模型(Gaussian Mixture Model,GMM)作为分割多个连续属性的方法以及属性选择方法。
类别不平衡问题同样需要关注。在真实数据集中,欺诈交易的比例通常小于1%,为了解决该问题,有关学者已经提出了几种技术方案,包括少数类的过采样、多数类的欠采样,以及使用成本敏感损失函数。其中一种称为“人工少数类过采样技术”(Synthetic Minority Over-sampling Technique,SMOTe)的过采样方法可用于通过生成欺诈交易的合成实例来平衡类别比例。
借鉴上述研究思路与方法,项目设计采用简单的逻辑回归模型将交易分为欺诈性交易或非欺诈性交易,然后通过一系列游戏来模仿欺诈者的学习过程并抢先重新训练分类器。具体过程是:首先,引入一种自适应欺诈检测系统,该系统利用前馈模型形式的重复博弈并结合SMOTe方法来缓解类别不平衡问题;其次,利用GMM模型分割连续属性的分布空间,作为寻找可能的对抗策略的一种手段;最后,在建模完成后进行多轮迭代,并与静态模型进行对比,对抗性模型在验证集上的AUC分数越高,证明对抗性学习的分类器建模比一般静态模型具有更高的准确率,即该模型更有效。
二、项目实验数据与测试方法
项目实验中使用的模拟数据变量包括欺诈指标(目标变量)、过账结束时账户余额、商家类别代码、授权总数、授权金额(交易金额)、授权未付金额(卡余额)、平均每日授权金额、销售点进入方法、是否重复授权、客户与商家之间的物理距离。上述变量被选为欺诈者在尝试实施未检测到的欺诈时可以合理影响的属性。为了给对手建模合理的策略,变量必须由对手控制。例如,欺诈者可能采用的一种策略是快速向某张卡上充值一大笔钱,然后停止充值。因此,与交易金额相关的变量可以说明对抗性学习算法中的这种策略。
为了验证项目提出的“欺诈者不断学习和适应分类器”的假设,研究中使用了对抗性学习算法(如图1所示),其算法过程可以描述为重复博弈。在每一轮博弈中,欺诈者会选择一个策略(图1中简化为只有两个策略),金融机构会选择重新训练分类器或使用原来的分类器。
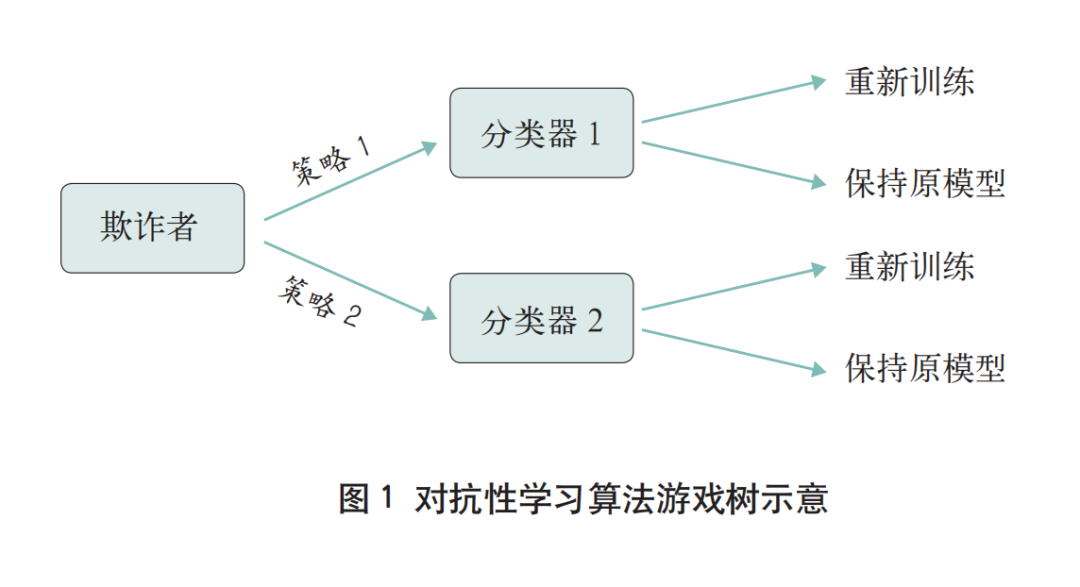
一般的欺诈检测算法无法辨别出欺诈者经常使用的策略(即在游戏树的哪个分支上),因此金融机构在决定是否重新训练分类器时,会忽略此信息。假设欺诈者通过不断测试了解到更多关于分类器的信息后,认为某种欺诈行为不易被发现时,他们将更倾向于执行此种欺诈行为。这些策略可以简单地选择某个变量(例如授权金额),也可以更复杂地包含多个变量。
选择GMM模型作为一种无监督的方式来创建欺诈者可以选择的三种不同策略。这个过程中GMM模型使用了前文数据变量部分列出的、除了不能在GMM模型中使用的非连续变量(欺诈指标、销售点输入方法、商户类别代码和经常性授权指标)以外的所有其他变量。创建三种策略的目的是将交易金额分割为低、中、高三箱,再通过GMM模型应用于整个变量空间。算法将这些策略分配给每个欺诈交易,然后根据当前模型的最高误报率选择最佳策略。最后,算法选择具有最佳策略的欺诈交易子集。
项目使用SMOTe方法,方便从最佳策略数据集中创建合成数据。该算法将这些合成数据添加到下一轮游戏中,以便金融机构抢先重新训练模型,以更好地预测下一轮欺诈交易。此外,项目添加了足够多的合成数据,使得每个数据集都包含大约15%的欺诈交易。尽管原始数据集仅包含约0.1%的欺诈交易,这种欺诈交易的过采样有助于提高分类器的预测能力。
尽管项目适用于几乎所有的分类器,但为了使过程简单透明,本文选择使用具有有限特征的逻辑回归模型作为算法模型。上述对抗性学习算法输入为交易级别数据,输出为每轮游戏的受试者工作特征曲线(Receiver Operating Characteristic curve,ROC)与AUC分数,具体迭代过程如图2所示。
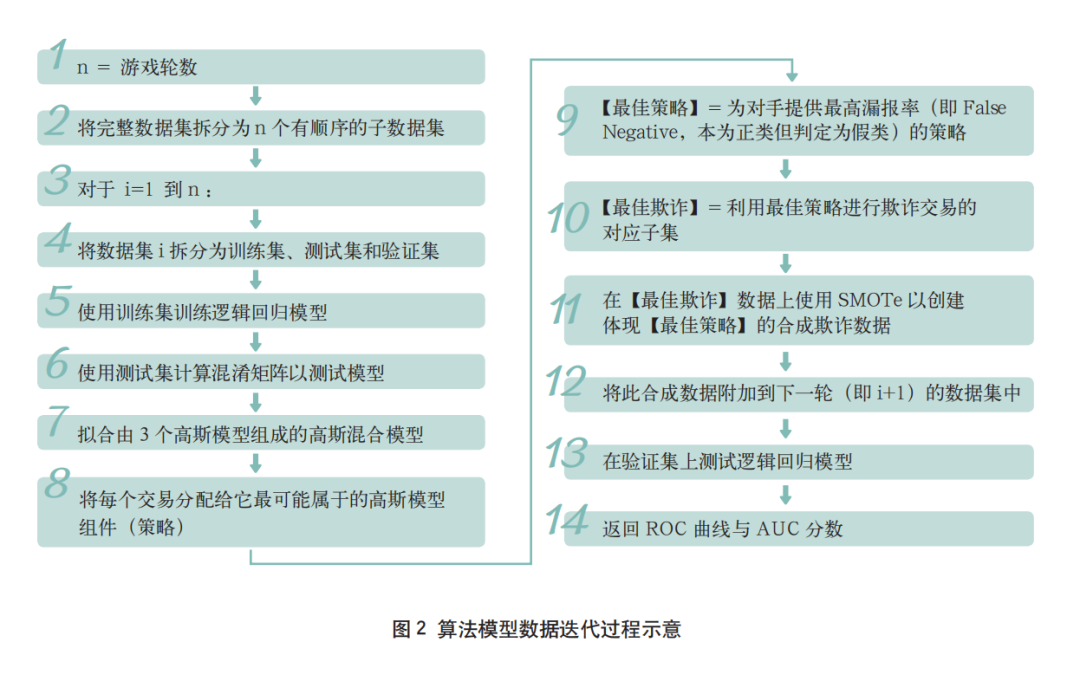
为了验证对抗学习模型的效果,项目以使用分类器保持不变但欺诈者不断适应的极端情况作为对比基线。在基线中,上述算法保持相对一致,唯一的区别是模型永远不会重新训练;最佳策略的过采样与识别仍然存在,说明了欺诈者越来越多地学习常量分类器。为了证明对抗性学习是有效的,对抗性学习模型应该优于分类器保持不变的基线模型。
三、结果
一般分类器包含以下指标:正确的正例(True Positive,TP),一个实例是正类并且也被判定成正类;错误的反例(False Negative,FN),存在漏报,本为正类但判定为假类;错误的正例(False Positive,FP),存在误报,本为假类但判定为正类;正确的反例(True Negative,TN),一个实例是假类并且也被判定成假类。
ROC曲线是以TP率为纵坐标、FP率为横坐标绘制的曲线。AUC值被定义为ROC曲线下的面积,是衡量学习器优劣的一种性能指标。
在实验中,项目选择使用十轮测试。欺诈检测模型在所有十轮游戏中的AUC分数表现见表1。由于对抗性学习分类器可以预测欺诈者的下一步动作,并随着游戏的进行而改进,因此AUC分数从第一轮的0.778增加到最后一轮的0.839,测试结果支持项目的假设,即分类器的性能会随着游戏的进行而提高。
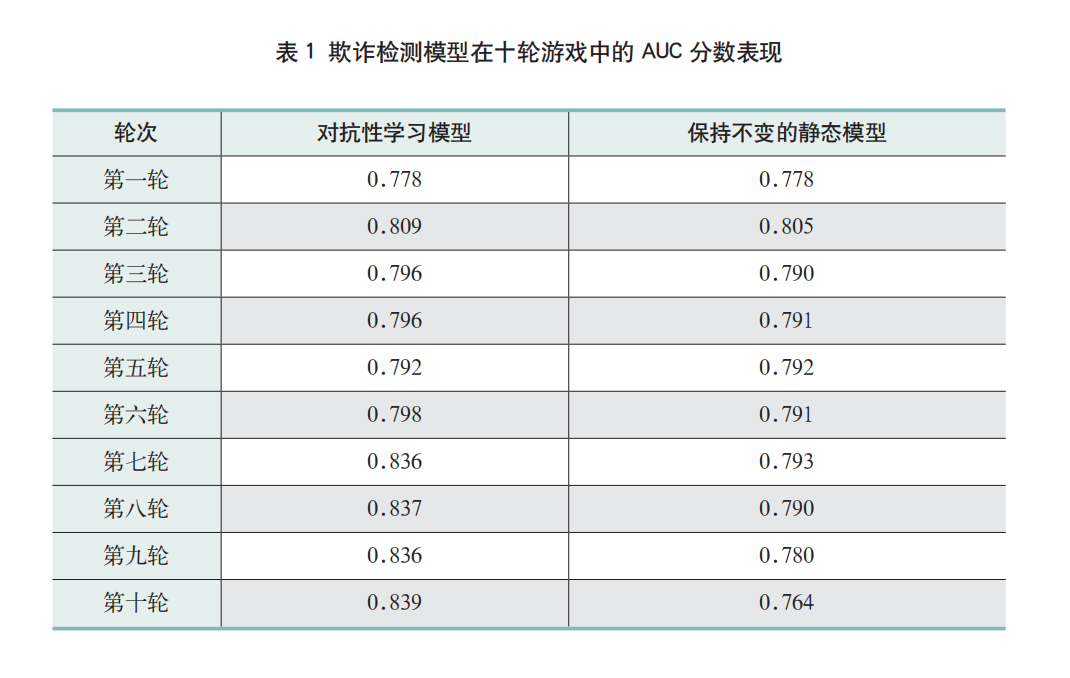
对于一般的分类器,欺诈者需要继续学习一个从未被重新训练过的恒定分类器。随着游戏回合的进行,实验开始前预计会看到ROC曲线向45度急剧弯曲,因为随着对分类器的了解不断加深,欺诈者将逐渐擅长躲避检测。然而,最后并没有看到这种急剧下降的情况发生,AUC分数从第一轮的0.778下降到最后一轮的0.764。这说明对手的学习是有效的,在十轮对抗中静态分类器的性能最终下滑,只是没有预想的剧烈。
在十轮博弈中,可以发现对抗性学习分类器优于非对抗性学习分类器,或至少表现得一样好,这一结论支持了项目的假设,即预测欺诈者的最佳策略确实会改善分类器。虽然在对手学习但分类器保持静态的模型中,模型性能只是略有下降,没有实验前预计的大幅下降,但这些结果依然可以说明在信用卡欺诈检测模型中使用对抗性学习相对于静态模型的好处。
本文提出了一种基于对抗性学习的信用卡欺诈检测动态模型框架。该框架还可以衍生许多值得探索之处,例如,为了区分各种可能的欺诈策略,GMM模型可以被优化以产生更多可能的交易类型区域;使用更多的速度变量,以发现交易的更多特征,实现分类算法改进;将这种对抗性框架应用于不同的分类算法,以了解它与静态模型的对比情况;引入随机性元素以试图混淆对手并破坏他们先前学习的系统知识等。
综上所述,基于对抗学习的动态模型有广阔的应用场景,在信用卡欺诈检测系统提升方面提供了足够大的探索空间,值得银行等金融机构深入挖掘。
本文刊于《中国信用卡》2023年第4期
声明:本文来自中国信用卡,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
