2023年4月8日~9日,由InForSec、南方科技大学斯发基斯可信自主系统研究院、清华大学网络科学与网络空间研究院、复旦大学软件学院系统软件与安全实验室、国科学院计算技术研究所处理器芯片全国重点实验室、中国科学院软件研究所可信计算与信息保障实验室、中国科学院大学国家计算机网络入侵防范中心、浙江大学NESA Lab、山东大学网络空间安全学院、百度安全、奇安信集团、蚂蚁集团、阿里安全等单位联合主办的“InForSec 2023年网络空间安全国际学术研究成果分享及青年学者论坛”在南方科技大学成功召开。来自清华大学、复旦大学、浙江大学、北京邮电大学、中国科学院大学等66所高校及科研院所的230余人现场出席会议,900余人通过视频会议系统及直播系统参与了本次论坛。
我们将对会议精彩报告进行内容回顾,本文分享的是蚂蚁天穹实验室安全专家陈耀光的报告——《面向序列变异的数据库Fuzzing技术》。
陈耀光安全工程师首先介绍了面向数据库系统的自动化漏洞挖掘技术研究的实践意义。数据库作为承载用户数据的底层系统,其安全性和稳定性非常重要,数据库中如果存在漏洞,攻击者可能通过漏洞直接获取到用户的隐私信息和敏感数据。目前市场上存在大量国际及国产数据库,包括拥有数十年历史的MySQL、Oracle数据库、国产自研的OceanBase数据库等等,这些数据库由数百万行代码构成,如何高效自动化的挖掘数据库系统中存在的漏洞一直是行业亟需解决的难题。为此,陈工程师提出了他们团队研发的面向序列变异的数据库系统模糊测试技术方案。

紧接着,陈工程师介绍了数据库系统的特点以及现有模糊测试工作的关注点与局限性。数据库的一大特点是存在很多语句(statement),主要包括ddl、dql、dml、dcl四大类型。目前数据库模糊测试变异方式主要包括生成式和变异式,之前的一些工作主要关注如何生成语法语义正确的数据库测试用例,但是忽略了在大型数据库系统中语句类型组合的重要性。生成式需要预先定义一些生成规则,比如,SQLsmith主要是生成各类SELECT语句,所以其探索的程序空间十分有限;变异式从已有的一些种子中随机选取作为变异的基础,但他们主要关注序列内部的变异,比如Squirrel在变异的时候不会改变statement类型,而是专注于变异statement内部的语法语义结构。

随后陈工程师通过一个例子指出相同语句的不同顺序组合会影响程序执行路径,可以帮助探索更多的数据库程序路径执行空间。

在意识到该现象后,陈工程师指出想要生成丰富而有效的SQL执行序列存在3个主要挑战:
1.SQL执行序列组合的可能性巨大。以PostgreSQL数据库为例子,PostgreSQL有188种的SQL statement类型,如果一个测试用例含有20个SQL statement,总的可能性有3×10^45,对于模糊测试工具Squirrel而言,经过实验1秒能执行10–60个用例,要执行一轮所有的用例需要超过10^35年。
2.有很多SQL执行序列是无意义的。比如在 “CREATETABLE t2 (v0 int)“ 语句执行之前先执行 ”SELECT * FROM t2“,因为存在语义错误而导致总体代码覆盖率很低。另外有些SQL序列之间没有很强的关联,比如一条创建表的语句和一条修改权限的语句可能完全不相关,他们之间的序列组合不会带来覆盖率上的明显提升。
3.随机生成的测试用例可能并不适合用来进行模糊测试。一个测试用例中不是SQL执行序列越多越好,实验测试证明一个含有945个SQL语句的测试用例,其中重复调用了数百次INSERT语句,这些语句有类似的行为和代码覆盖,对代码覆盖率的增长没有太大作用,反而大大降低了执行速度。
为解决这些挑战,陈工程师提出基于变异的方式,主动生成丰富的SQL语句序列。

陈工程师为他们的工具起了一个很有趣的名字叫LEGO(“乐高”),并介绍了其内在工作的基本思想是从已有的测试用例中学习SQL语句关系规则,基于高质量的关系重新生成变异种子。
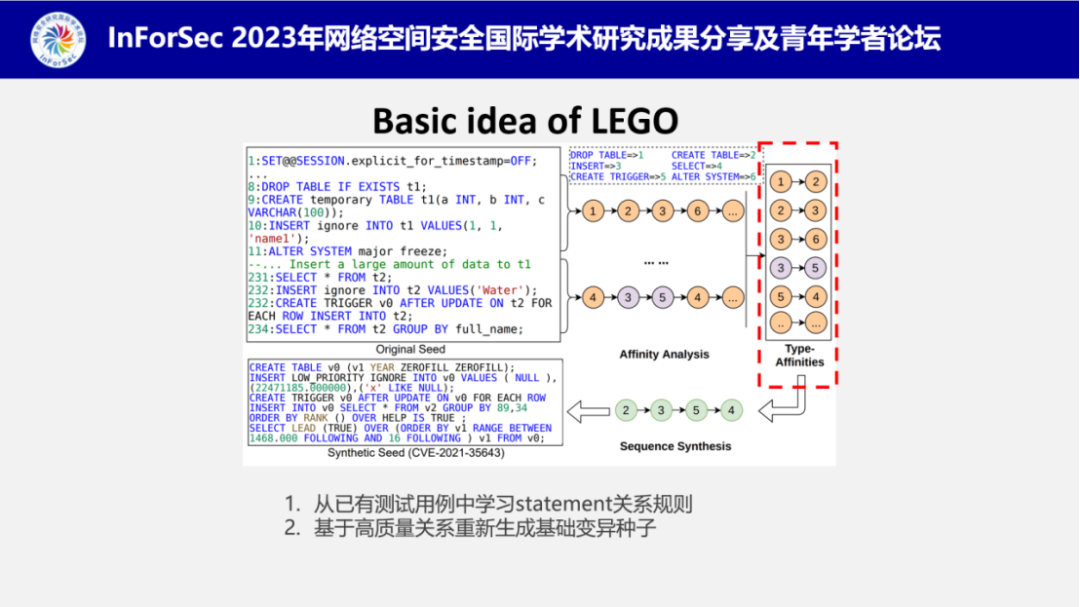
接着,陈工程师介绍了LEGO的工作流程,其核心模块包括主动亲疏性分析(Proactive affinity analysis)和渐进式序列生成(Progressive Sequence Synthesis)。
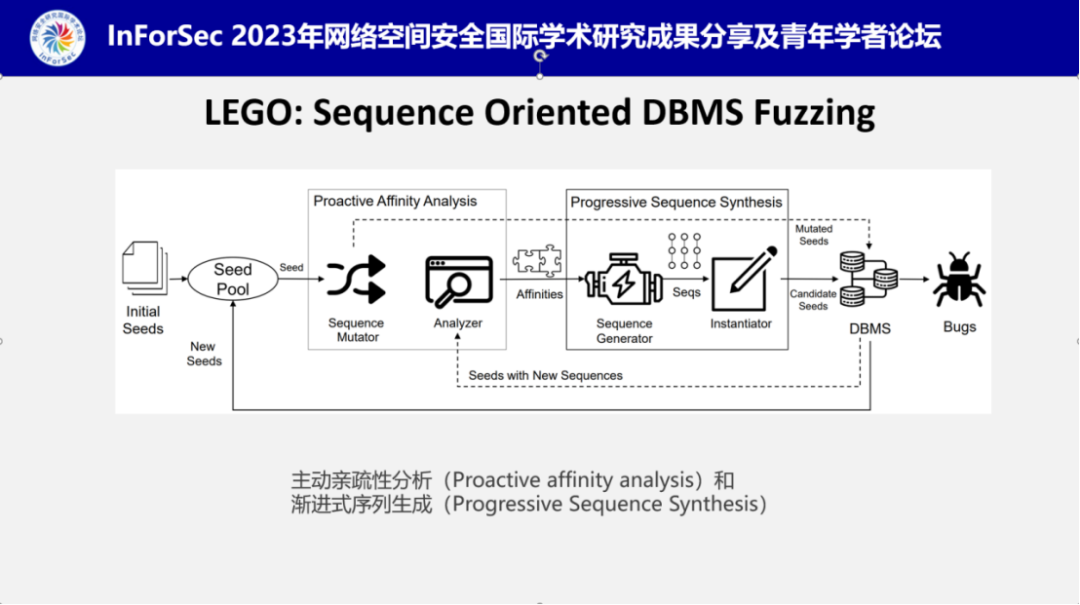
在了解了LEGO的整体工作流程后,陈工程师展开介绍了两个核心模块的工作细节。首先是语句类型亲疏性分析,陈工程师介绍到他们通过相邻语句之间的时序关系判断语句类型之间的亲和性,例如如果一个语句紧跟着另一个语句,那么就认为这两个语句之间的类型存在亲和性,用(type1, type2)表示,基于此可以生成相邻statement之间的有向对。之后再基于这些有向对进行基于序列的变异,主要包括替换、插入及删除三大类操作,如果操作后的序列输入发现了新的路径分支,则分析是否是由修改的类型亲和性所导致的,如果是,则保存该类型亲和性,最终得到一组高质量的类型亲和性(Type-Affinity)。

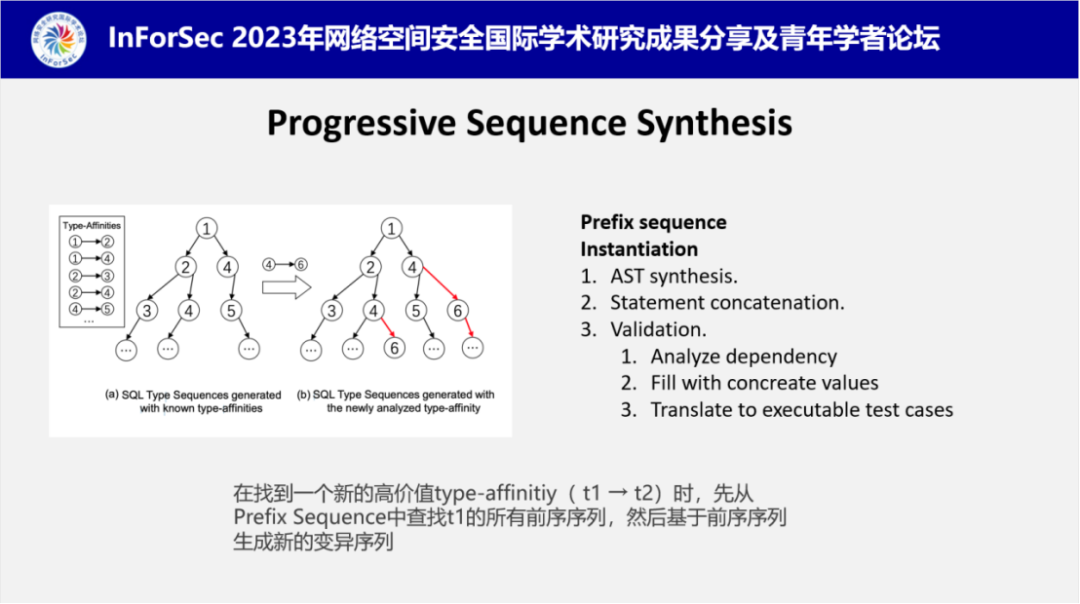
在获取到高质量的type-affinities之后,接下来是根据已有的type-affinities逐步合成新的变异样本,对于新发现的type-affinitiy,LEGO在序列生成时会优先生成含有此类type-affinitiy的语句。
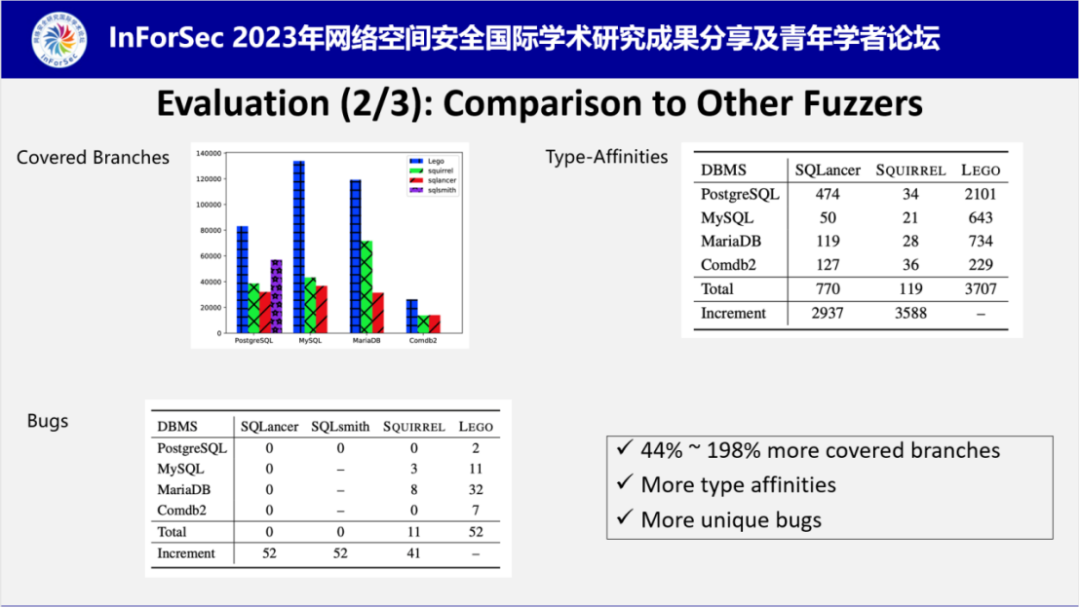
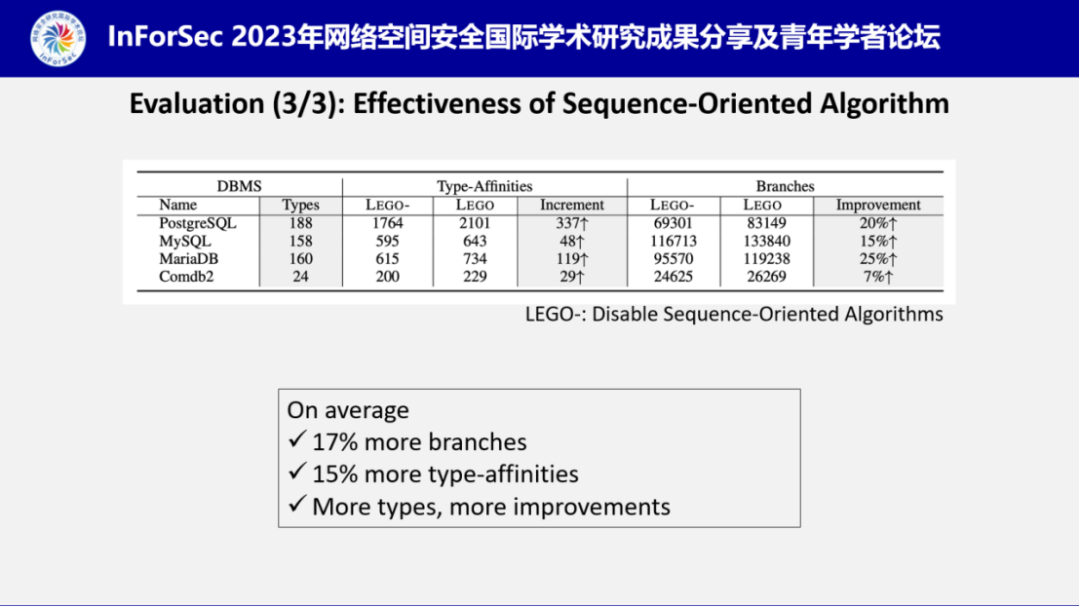
在细致介绍了LEGO的核心工作原理后,陈工程师介绍了其从三个角度对LEGO进行的实验测试。第一个是漏洞发现能力,LEGO在4个数据库中一共发现了102个Bug,获得22个CVE编号,其中高危漏洞8个,中危漏洞8个。

第二个角度是与其他模糊测试工具的对比实验。实验结果证明LEGO能够覆盖更多的代码,发现更多的独特漏洞。
第三个角度是其面向序列变异算法的有效性。通过部署使用和不使用该算法的模糊测试工具进行实验,证明该算法平均能够提升17%的分支覆盖率和15%的语句类型亲和性识别结果。
最后,陈工程师对该研究工作内容进行了总结,并且还代表蚂蚁天穹&光年实验室对相关研究方向的学者和同学发出合作邀请。


演讲者简介
蚂蚁天穹实验室安全专家,目前负责蚂蚁基础设施的蓝军安全攻防建设,主要研究方向为代码安全、隐私保护、漏洞挖掘等 ,曾获得过Google、Samsung、Oracle等公司的公开致谢,在hitcon、isc等国内外安全会议上发表过演讲,参加过xpwn、geekpwn、天府杯、信创安全等多个破解大赛。
声明:本文来自网安国际,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
