2023年3月23日,全国安全标准化技术委员会正式发布了国家标准《信息安全技术 个人信息去标识化效果评估指南》(以下简称“《指南》”),其将于2023年10月1日正式生效实施。能否实现个人信息的去标识化对于企业来讲是非常重要的合规义务,因为《个人信息保护法》第五十一条明确要求个人信息处理者应采取去标识化等安全技术措施来履行安全保护义务。目前,国家标准《信息安全技术 个人信息安全规范》(以下简称“《规范》”)明确了去标识化处理的要求,国家标准《信息安全技术 个人信息去标识化指南》(以下简称“《去标识化指南》”)细化了去标识化活动的开展过程,《指南》则为具体评估是否真正实现了有效的去标识化提供了指引,通过细化个人信息标识度分级和评定方法,不断推动个人信息去标识化技术、流程及配套评估措施朝着定量化的精细方向发展。
应 用 标 准
GB/T 37964-2019 《信息安全技术 个人信息去标识化指南》
GB/T 42460-2023 《信息安全技术 个人信息去标识化效果评估指南 》
01 去标识化的含义
1.什么是去标识化?
《指南》第3.3条指出,去标识化是指通过对个人信息的技术处理,使其在不借助额外信息的情况下,无法识别或者关联个人信息主体的过程,与《规范》第3.15条的定义是一样的,且《规范》还进一步指出,去标识化保留了个体颗粒度,采用假名、加密、哈希函数等技术手段替代对个人信息的标识。不过《个人信息保护法》第七十三条规定,去标识化是指个人信息经过处理,使其在不借助额外信息的情况下无法识别特定自然人的过程。相比之下,《个人信息保护法》只强调“识别性”,不能识别个体就实现了去标识化,而《指南》和《规范》这类国家标准则强调“识别性”和“关联性”,不能识别或关联个体才属于去标识化,在一定程度上提高了去标识化的认定门槛。
2.去标识化和匿名化有什么区别?
依据《个人信息保护法》的定义,去标识化信息在借助其他信息的情况下仍有可能识别特定自然人,属于个人信息;而匿名化信息是无法识别特定自然人且不能复原的信息,不属于个人信息。《指南》也特别指出,经去标识化处理后的个人信息并不能完全实现匿名化。去标识化的目的是降低与个人信息主体之间的关联性,去标识化技术更强调的是降低信息的区分度和识别度,使得信息在一般情况下不能对应到特定个体。而匿名化技术则更在意绝对安全的问题,因为匿名化后的信息已不再属于个人信息,且无法与额外信息结合识别出个人信息主体,这种技术必须实现绝对的不可识别。
对比项 | 仅从该信息本身 无法指向特定的个人 | 结合其他信息 也无法指向特定个人 | 处理后的信息 不可能被复原为个人信息 |
匿名化 | √ | √ | √ |
去标识化 | √ | × | × |
3.欧美是如何定义去标识化的?
域外 地区 | 去标识化定义 | 去标识化使用 |
欧盟 | GDPR中的假名化与中国去标识化的内涵更为类似。GDPR第4条5款规定假名化是指在不借助额外的数据的情况下,处理后的个人数据不会识别特定的个人数据主体,但是此类额外的数据需要被单独保存,并受到技术措施和组织措施的约束,以保证个人数据不属于已识别或可识别的自然人。 | GDPR指出,如果数据仅仅是进行了假名化的处理,仍是可识别到具体个人数据主体的个人数据,应遵循GDPR的相关数据处理要求。 |
美国 | CCPA第1798.140 条(h)款规定去标识化是指数据不能直接或间接地合理识别、关联、描述特定的消费者。 CPRA第1978.140条(m)款则将去标识化定义为无法合理地用于推断或关联特定个人,同时强调信息处理者应公开承诺自己不会进行重识别,并通过合同约束接收方也不会进行重识别。 | CCPA第1798.145 条(a)款规定CCPA不规制经过去标识化处理的消费者数据。此外,HIPPA (Health Insurance Portability and Accountability Act)中确立了专家个案审查的去标识化制度,即由专家委员会对单一案例内的数据的可识别性进行判断,通过个案判断来更精确的判断去标识化数据的范围。 |
欧盟认为去标识化处理后的信息仍然为个人信息,需要遵守个人信息处理的相关规则,中国采取了与欧盟类似的立法模式。但是美国的立法模式相对不同,其以促进数据自由流通为导向,故CCPA直接规定其不适用于去标识化处理的个人信息,对这类数据给予了非常大程度的授权豁免,加速了数据的流通使用,体现出了尽可能促进数据创造其价值的立法意图。此外,欧盟与中国都强调去标识化是客观上的无法识别,而美国不仅仅要求客观上无法合理识别到特定个人,而且要求信息处理者主观上承诺确保其不会进行重标识。
02 常用的去标识化技术措施
1.有哪些常用的去标识化技术?
依据《去标识化指南》的规定,将常见的去标识化措施做出如下总结:
分类 | 名称 | |
常见的去标识化技术 | 统计技术 | 数据抽样 |
数据聚合 | ||
密码技术 | 确定性加密 | |
保序加密 | ||
保留格式加密 | ||
同态加密 | ||
同态秘密共享 | ||
抑制技术 | 屏蔽 | |
局部抑制 | ||
记录抑制 | ||
泛化技术 | 取整 | |
顶层与底层编码 | ||
随机化技术 | 噪声添加 | |
置换 | ||
微聚集 | ||
数据合成技术 | ||
假名化技术 | 独立于标识符的假名创建 | |
基于密码技术的标识符派生假名创建 | ||
常用的去标识化模型 | K-匿名模型 | |
差分隐私模型 | ||
2.如何开展去标识化?
《去标识化指南》提出的去标识化过程总结如下:
步骤 | 具体说明 | ||
1 | 确定目标 | 确定去标识化对象 | 依据法规标准、组织策略、数据来源、业务背景、数据用途、关联情况,确定去标识化的数据集范围。 |
建立安全目标 | 依据数据用途、数据来源、公开共享类别、去标识化模型和技术、风险级别,来确定重标识风险不可接受程度以及数据有用性最低要求。 | ||
制定工作计划 | 制定个人信息去标识化的具体实施计划,包括去标识化的目的、安全目标、数据对象、公开共享方式、实施团队、实施方案、利益相关方、应急措施以及进度安排等,形成去标识化实施计划书。 | ||
2 | 识别标识 | 查表识别法 | 需要预先建立元数据表格,存储需去标识化的直接标识符和准标识符名称,在识别标识数据时,将待识别数据的各个属性名称或字段名称,逐个与元数据表中记录进行对比以进行识别。查表识别法适用于数据集格式和属性已经明确的去标识化场景,如采用关系型数据库,在表结构中已经明确姓名等标识符字段。 |
规则判定法 | 通过建立自动化程序,分析数据集规律,从中自动发现需去标识化的直接标识符和准标识符。企业识别标识数据宜先采用查表识别法,并根据数据量大小和复杂情况,结合采用规则判定法。 | ||
人工分析法 | 人工分析法是通过人工发现和确定数据集中的直接标识符和准标识符。企业可在对业务处理、数据集结构、相互依赖关系和对数据集之外可用数据等要素分析的基础上,综合判断数据集重标识风险后,直接指定数据集中需要去标识化的直接标识符和准标识符。考虑到工作量和复杂程度等因素,人工分析法更适用于数据结构简单的数据集。 | ||
3 | 处理标识 | 预处理 | 根据数据集的实际情况选择是否进行预处理。具体方法如下:形成规范化,或满足特定格式要求的数据;对数据抽样,减小数据集的规模;增加或扰乱数据,改变数据集的真实性。 |
选择模型技术 | 基于考虑聚合数据是否够用;数据是否可删除;是否需要保持唯一性;是否需要满足可逆性;是否需要保持原有数据值顺序等因素,为不同类型的数据采用不同的去标识化技术。 | ||
实施去标识化 | 根据选择的去标识化模型和技术,对数据集实施操作。如果存在多个需要去标识化的标识符,则根据数据特点和业务特性设定去标识化的顺序,然后依次选择相应的工具或程序,获得结果数据集。 | ||
4 | 验证批准 | 验证个人信息安全 | 可以通过检查生成的数据文件、评估去标识化软件所使用的默认假设、进行有动机的入侵者测试、让团队利用内部数据进行有针对性的入侵者测试等方式来进行验证。 |
验证数据有用性 | 因为去标识化降低了数据质量和生成数据集的有用性,所以需要验证去标识化后的数据集对于预期的应用是否仍然有用。例如,内部人员可对原始数据集和去标识化的数据集执行统计计算,并对结果进行比较,以查看去标识化后是否导致不可接受的更改。 | ||
评审批准 | 在完成处理标识和验证结果后,企业管理层应依据数据发布共享用途、重标识风险、数据有用性最低要求等因素,以及验证结果、去标识化各步骤实施过程中的监控审查记录等因素,做出是否认可数据去标识化结果的决定。 | ||
5 | 监控审查 | 步骤实施过程 | 企业管理层在各个步骤完成时,对该阶段记录文档进行审查,检查输出文档是否内容完备,并采取适当控制措施,监督各步骤执行过程得到有效地执行。 |
持续监控效果 | 数据宜根据情况变化或定期进行去标识化数据的重标识风险评估,并与预期可接受风险阈值进行比较,以保障个人信息的安全性。 | ||
03 去标识化的效果
1.个人信息去标识化效果如何分级?
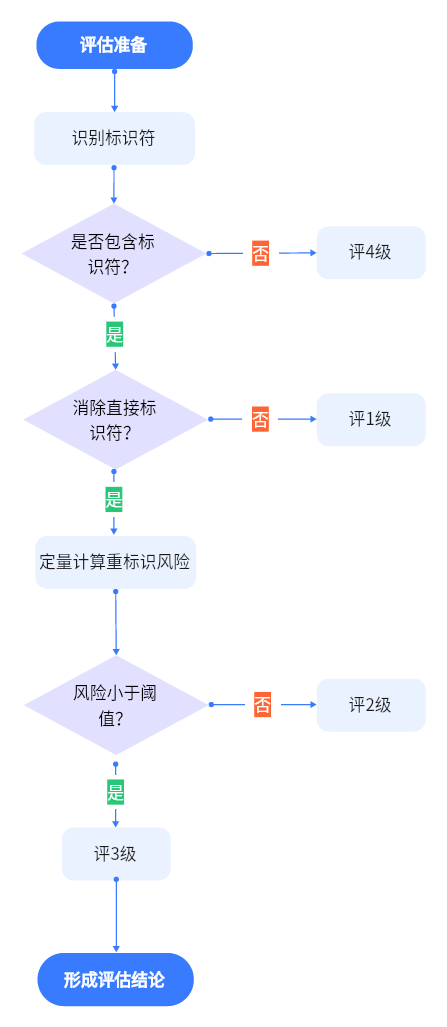
《指南》特别指出,经去标识化处理后的个人信息仍存在重标识的风险,需结合应用场景进行去标识化效果评估。基于数据是否能直接识别个人信息主体,或能以多大概率识别个人信息主体,个人信息标识度可划分为4级。级别越低,风险越高。
级别 | 风险 | 划分依据 | 备注解释 |
4 | 风险最低 | 不包含任何标识符。 | 直接标识符:在任何特定环境下可唯一识别个人的标识码,包括:姓名、公民身份证号、护照号、驾驶证号、详细住址、电子邮件地址、电话号码(包括手机号和固定电话号码)、传真号码、银行账户、车辆标识符和序列号(包括车牌号)、社会保障号码、健康卡号码、病历号码、设备标识符和序列号、生物识别码(包括指纹和声纹等识别码)、全脸图片图像和其他任何可比对的图像、账号、证书号或许可证号、互联网协议地址等。 |
3 | 风险较低 | 消除了直接标识符,但包含准标识符,且重标识风险低于可接受风险阅值。 | |
2 | 风险较高 | 消除了直接标识符,但包含准标识符,且重标识风险高于或等于可接受风险阙值。 | 准标识符:在相应环境下无法单独唯一识别个人信息主体,但结合其他信息可唯一识别的标识符,包括:性别、出生日期或年龄、事件日期(例如入院、手术、出院、访问相关日期)、地理范围(例如邮政编码、建筑名称、地区)、族裔血统、国籍、籍贯、语言、原住民身份、可见的少数民族地位、职务、工作单位、部门等职业信息、婚姻状况、受教育水平、上学年限、总收入、宗教信仰等。 |
1 | 风险最高 | 包含直接标识符,在特定环境下能直接识别个人信息主体。 |
2.个人信息去标识化效果是如何评估的?
《指南》规定,首先需要进行评估准备,确定评估的数据集和依据、组建评估团队、确定重标识风险计算方案和可接受的风险阈值,其次进行定性评估,按照标识符清单进行判断,再次进行定量评估,计算和比较重标识风险,最终形成评估结论,并需获管理层批准。沟通与协商和评估过程文档管理贯穿始终。具体流程图如下:
04 结语
技术的高速发展使得个人信息的绝对匿名化难以实现,同时绝对的匿名化也会损害信息质量,从而影响信息价值。因此,个人信息去标识化技术变得非常重要,因为去标识化处理不仅可以避免他人根据信息直接识别出个人,增强个人信息安全性,而且依据不同的业务和个人信息特性选择合适的去标识化技术,能够确保去标识化的个人信息尽量满足预期目的从而保证个人信息的有用性,既能保障个人信息安全又能促进信息利用。
《个人信息保护法》将去标识化作为法定的安全保护措施,但是如何证明采取的技术措施是去标识化措施,以及采取的技术措施是否真正达到了不可直接识别个人信息主体的效果都是非常重要的问题,《指南》通过明确个人信息去标识化效果评定流程,并在附录给出了可参考的计算方法和阈值推荐,为去标识化技术的落地发展提供了更明确的指引。企业还可以针对不同级别的去标识化的个人信息采取不用类型的个人信息保护措施,来细化落地内部的数据分类分级保护制度。
(作者:北京腾云天下科技有限公司 葛梦莹 南钰彤)
声明:本文来自CCIA数据安全工作委员会,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
