摘 要
网络中的大部分流量来自于网络爬虫,互联网中的搜索引擎就是最大的网络爬虫。在大数据之下,深层挖掘数据价值是一个很有价值的课题,但是在此之前,获取数据这一步也是至关重要的。网络爬虫制作简单,而且大多数为了效率不会尊重网站的服务条款,高速的爬取会占用过多的服务器资源,因此需要一些方法来划分来自网络中的流量,并且拦截网络爬虫。本文将会对一些现有的网络爬虫拦截技术进行综合叙述。
一、Headers头部校验
网络爬虫的本质是对网络请求的模拟。脚本要发送请求,就需要构造请求头部,这个请求头部通常被称为Headers。Headers头部校验指的是服务器对HTTP请求报文中请求头键值对的检测。检测的键值对主要有三个:
(1) User-Agent:检测请求者的用户代理,此项缺失则判定为机器人。
(2) Referer:检测请求者是否以正常途径跳转到本页面,常用于防盗链技术。
(3) Cookie:检测请求者身份状态,在需要登录才能访问的网站通常需要携带。
要应对这类Headers头部检测非常容易,只需要在使用浏览器访问页面后进行抓包观察,大多数情况下直接复制请求头中的内容即可。值得注意的是,在需要登录才能访问的页面,其中的Cookie是有时效性的,需要及时更新。在一些安全防护较好的网站,Headers头部中也会额外加入一些本地JS运行后计算出的加密参数。
二、IP地址记录
对于IP地址的记录,主要是针对恶意爬虫,防止其在短时间内大量发起HTTP请求访问网站,造成网站资源的侵占。这种反爬虫手段原理就是检测异常访问用户,如果有请求在短时间(例如3秒)内连续访问网站高达数十次,则会进行IP记录,将其判定为机器人,在该IP地址的HTTP请求再次发来的时候,服务器就回复状态码403 Forbidden,禁止该请求的继续访问,这种防护手段的优点很明显,缺陷也很明显,那就是一刀切容易误伤人类用户。
此种反爬虫手段的应对需要爬虫开发者尽量减缓HTTP请求间隔,以求达到和正常人类访问页面相似的速度,避免被算法检测。或者可以建立IP代理池,也可以购买代理商IP,如图1所示:
图1快代理IP页面
在进行HTTP请求的时候使用代理IP访问,本地IP就会被隐藏在代理之后,即便被算法检测,也只需要更换新的IP地址。
三、Ajax异步加载
Ajax(Asynchronous JS And XML,异步JS和XML)是一种创建交互式网页应用的网页开发技术,简单来说,就是在浏览一个界面的时候,URL地址本身没有发生改变,页面内容却发生了动态更新,如图2所示,网页端里百度图片的瀑布流加载即使用了Ajax。
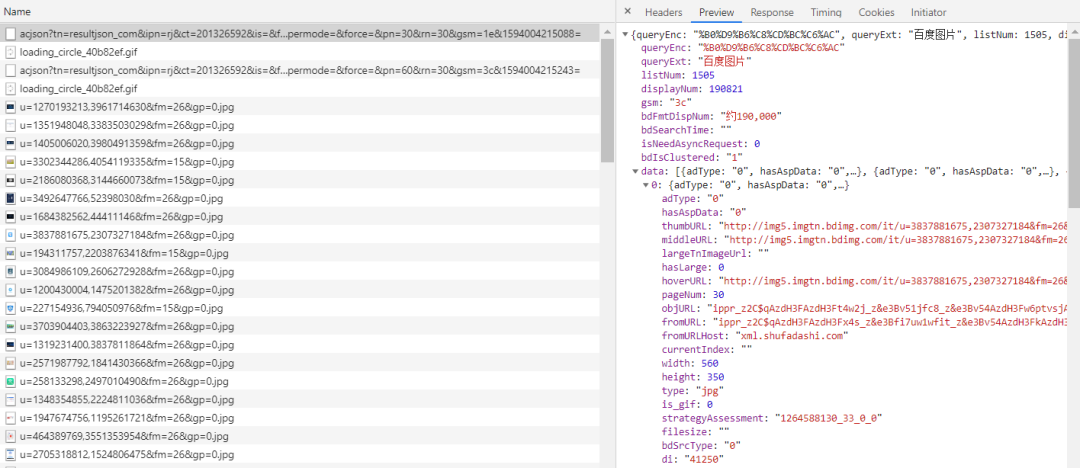
图2 百度图片抓包
这个时候,直接使用GET请求去获取页面内容是定位不到具体内容的,因为它的获取一般是经由数据接口进行返回的。
严格来说,这并不算是一种反爬虫技术,但是运用Ajax之后,爬虫开发者需要在网络请求包中去自行选择数据包才可以,而不是可以简单通过GET页面源代码来编写爬虫。面对此类技术,只需要进行网页抓包,在大量的数据包中寻找到真正包含网页内容的数据接口即可。因为数据如果要渲染到页面,就一定会有数据包将其传输到客户端,开发者要做的只是将它找出来。一般而言,此类技术进行数据传输返回的结果都是JSON格式的,所以需要用JSON包进行数据解析。
四、字体反爬虫
不同于一般的反爬虫思路,字体反爬虫主要在数据上做手脚。要获取的网页数据在浏览器中可以正常查看,但是在将其复制到本地后就会得到乱码。它的原理是网站自己自定义创造了一套字体,构建映射关系后将其添加到了css的font中,在浏览器中查看的时候,网站会自动获取这些文件,从而建立对应关系映射得到字符。而爬虫开发者在编写网络爬虫的时候,往往只会请求网页的URL地址,这就造成了映射文件的空缺,没有字符集能够解析这些字符,导致乱码问题。如图3所示,实习僧网页端使用了自定制的字体文件。
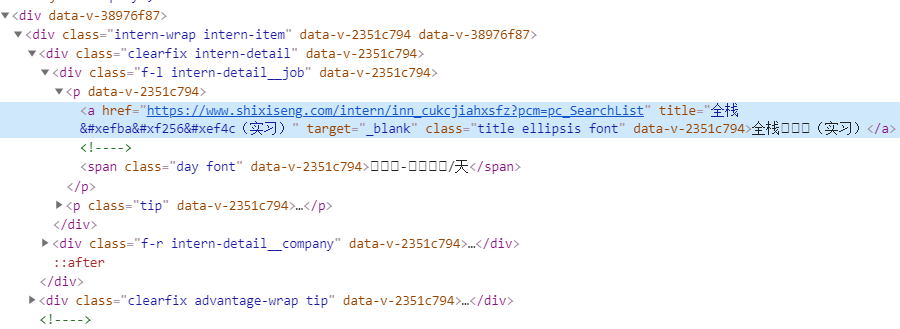
图3 实习僧字体反爬虫
字体反爬虫的突破有两种方法,第一种方法是找到font文件的URL请求地址,将其下载到本地后使用xml解析工具解析出来,然后就可以根据其中的字符对应关系,建立本地映射进行字符替换。第二种方法是直接手动复制其中的加密字符,在本地通过encode编码后得到对应编码,建立自己的本地映射字典,然后进行字符爬取替换。之所以可以使用第二种方法,是因为字体反爬虫的加密字符通常不会很多,大多是对阿拉伯数字和部分网站常用汉字进行加密,所以可以直接人工复制进行编码映射。
五、验证码反爬虫
如今的互联网恶意爬虫横行,上述的反爬虫手段虽然可行,但是被恶意爬虫突破也很容易。为了应对这种情况就诞生了验证码,从最开始的英数验证码到如今的图片点选验证码,验证码技术在不断更新迭代,未来也会出现更多类型的验证码。验证码的防护主要在两个阶段,第一个阶段是登录注册阶段,第二个阶段是访问页面阶段,前者是为了将恶意爬虫拦在门外,让人类用户进入,后者是为了清理那些突破了登录注册阶段,进入页面爬取的恶意爬虫,如果服务器检测到某IP地址在短时间内大量访问,不会直接封禁用户,而是出现验证码,这样就避免了对用户的误伤,不是一刀切,更加人性化。如果是人类用户自然可以通过这些点选识别的验证码,但如果是机器人就很难突破这第二道关卡,如图4所示的图片点选验证码。
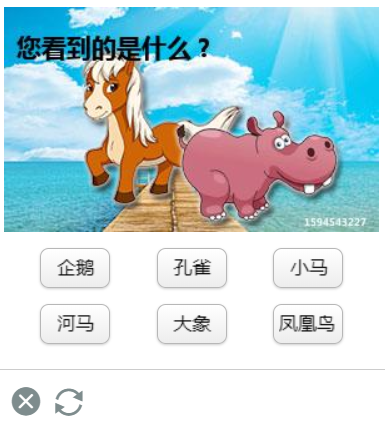
图4 图片点选验证码
这类反爬虫手段的应对主要是对接各大验证码识别平台或者是通过训练深度学习神经网络模型,让模型帮助爬虫程序过掉验证码。而且如今深度学习框架盛行,训练模型早已不是难事,单纯的验证码识别已经拦不住搭配了深度学习模型的网络爬虫,所以网站开发者会在验证码识别背后再加上较复杂的JS参数加密,即便验证码被识别,也很难构造出最终的加密结果来,这样就提高了破解门槛。不过使用特殊的测试工具,例如selenium,可以直接搭配训练模型模拟人类行为过掉验证码,免去破解JS加密参数的烦恼。不过自动化的测试工具存在着明显的特征,个别网站会在JS文件中添加对自动化软件特征的识别,从而拒绝服务。
六、JavaScript参数加密
JavaScript(以下简称JS)参数加密常见于POST表单提交的情形里,主要是为了防范恶意机器人批量注册与模拟登录等行为。如果对POST表单进行抓包的话,会发现自己在表单里输入的数据被加密为了不可知的字符串,这主要是通过加载网站的本地JS脚本实现的。
对于这类反爬虫的应对,除了熟悉调试技巧外,还需要读者有较扎实的JS语言基础,因为此类加密的破解通常需要开发者能够读懂目标网站的JS加密脚本,并进行一系列的删改操作,用静态分析逐步从庞大的JS脚本中将具体的加密函数“扣”出来,在本地模拟运行得到加密结果,再通过POST发包将参数进行传递才能得到正常反馈,因此它能够阻挡大量技术力较低的恶意爬虫。
这类反爬虫手段的破解手段主要分两种:
(1)简单的加密直接使用Python语言进行复现。
(2)较复杂一些的加密可以将具体函数“扣”出来,组成加密脚本后模拟运行。同时还要对一些浏览器指纹检测进行模拟。
七、JS反调试
JS参数加密对于熟悉JS语言的开发者来说,防范的门槛并不高。所以为了从源头上断绝开发者对网站加密文件的分析,就诞生了JS反调试。
最简单的方法是通过禁止用户右击以及按F12等快捷键实现的,对于这种简单的防护只需要修改对应快捷键,或者在新窗口中打开开发者工具再切换回原页面即可。
较难一些的主要是通过检测用户是否打开了浏览器开发者工具或者是否修改了本地JS脚本文件,从而判断是否进行无限循环debugger的卡顿,让开发者无法进行脚本调试。这种反爬虫的破解需要熟悉JS Hook相关知识,因为检测控制台状态和脚本文件状态的源代码是大同小异的,可以通过编写Chrome拓展插件自动Hook反调试代码并进行函数替换,从而过掉检测让开发者能够进行静态分析。
八、AST混淆反爬虫
从理论上来说,任何反爬虫手段都无法阻止爬虫的进入,因为如果一个网站想要有用户流量,必然不会设置太高的门槛导致正常用户也无法访问。只要开发者的网络爬虫尽可能地模拟人类访问网站的情形,就能够进入网站肆意横行。
不过虽然无法根绝网络爬虫的进入,却可以提高网络爬虫进入的门槛,将网站的损失降到最低。在所有的反爬虫防护手段中,JS参数加密的防护效果是比较出色的,它能将大多数低技术力的爬虫开发者挡在门外。现在的网站即便是使用了验证码防护,其背后的HTTP请求传输也会使用JS对验证码参数进行加密,它虽然没办法完全阻止爬虫的进入,却能让爬虫开发者耗费大量时间在破解上,这是一种成本低廉却效果非凡的手段,如果网站的加密脚本经常更换的话,即便是再老练的爬虫开发者也会疲于奔命,因此如何加大JS脚本的破解难度是一个关键点。
常见的防止开发者调试JS脚本文件的方法无非禁止右击和禁止打开开发者工具,或者使用JS代码进行检测,但这些方法都存在着通杀通用的解决方案,因为它们的防护等级并不算高,只要熟练使用搜索引擎就可以过掉。要想在JS脚本防护上尽可能延长被爬虫破解的时间,最好的方法就是使用AST抽象语法树对JS脚本代码进行高度混淆,将其转化生成为不可阅读且不可识别,却可以正常运作的乱码文件。如图5所示,经过混淆的JS代码的可读性已经大大下降,这进一步增大了JS逆向的难度。
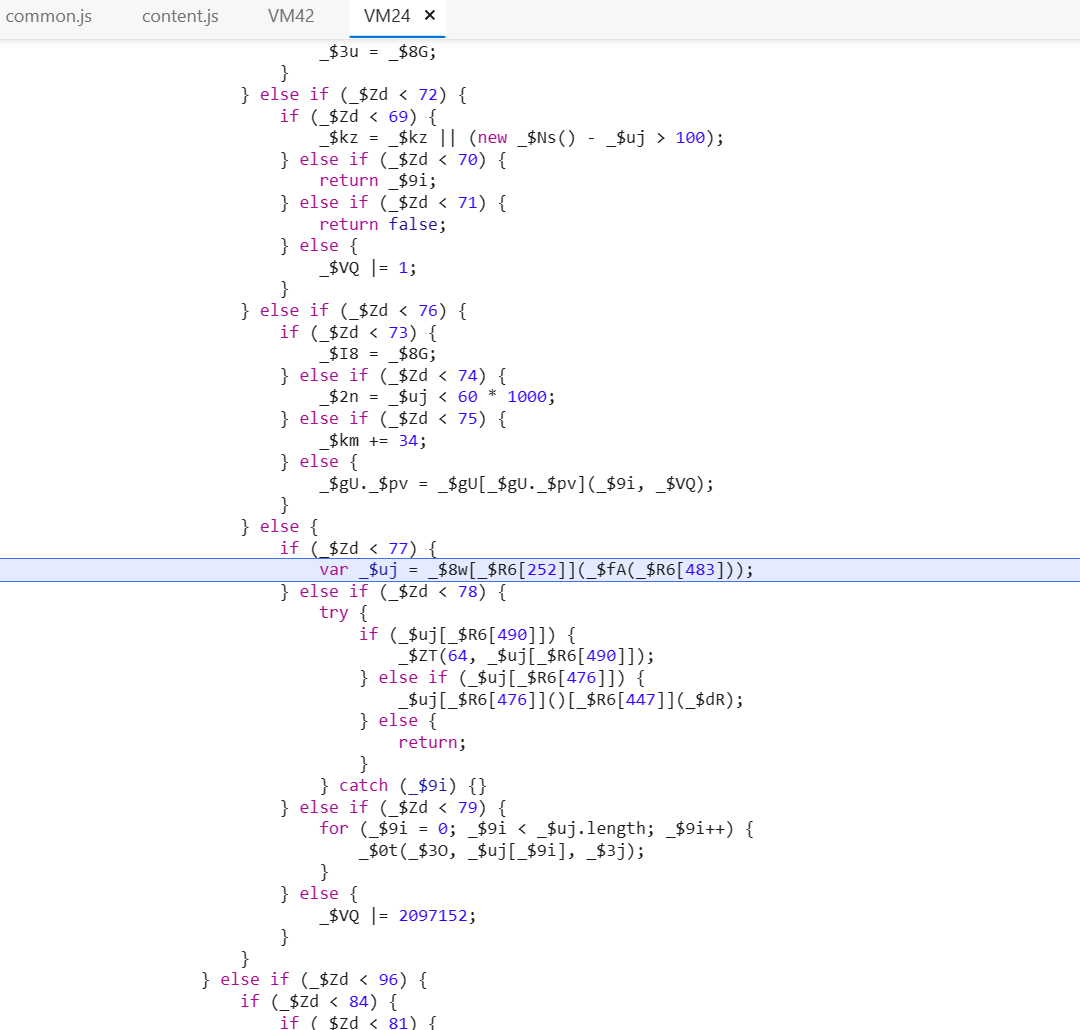
图5 经过混淆的JS代码
九、总 结
反爬虫技术并不能够根绝网络爬虫,这是必然的。网站的前端加密文件是任何用户都可以随意读取的,网站的存在是以真实用户的流量为依托的,如今的网络爬虫技术飞速发展,几乎能够达到以假乱真的状态。即便是检查JS文件是否真实运行在浏览器当中,爬虫开发者也可以在脚本文件中模拟对应的对象原型。但不论怎么说,爬虫和反爬虫的对抗,一方面提高了爬虫的门槛,强化了企业的安全意识,另一方面,又促进了爬虫技术的发展。
参考文献
[1]Ma Xiaoju,Yan Min. Design and Implementation of Craweper Based on Scrapy[J]. Journal of Physics: Conference Series,2021,2033(1).
[2]Deng Kaiying,Chen Senpeng,Deng Jingwei. On optimisation of web crawler system on Scrapy framework[J]. International Journal of Wireless and Mobile Computing,2020,18(4).
[3]Wang Wei,Yu Lihua. UCrawler: A learning-based web crawler using a URL knowledge base[J]. Journal of Computational Methods in Sciences and Engineering,2021,21(2).
[4]Tianyi Ma,Ziyang Zhang. Medical Consultation System based on Python Web crawler[C]//.Proceedings of 2021 2nd International Conference on Electronics, Communications and Information Technology (CECIT 2021).,2021:772-776.DOI:10.26914/c.cnkihy.2021.065511.
[5]Addo Prince Clement,Dorgbefu Jnr. Maxwell,Kulbo Nora Bakabbey,Akpatsa Samuel Kofi,Ohemeng Asare Andy,Dagadu Joshua Caleb,Boansi Kufuor Oliver,Kofi Frimpong Adasa Nkrumah. Video Ads in Digital Marketing and Sales: A Big Data Analytics Using Scrapy Web Crawler Mining Technique[J]. Asian Journal of Research in Computer Science,2021.
作者:李岳阳 网络与空间安全学院
责编:眼 界
声明:本文来自中国保密协会科学技术分会,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
