
1 论文信息
论文题目:VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python
论文作者:Laura Wartschinski, Yannic Noller, Thomas Vogel, Timo Kehrer, Lars Grunske发表会议/期刊:Information and Software Technology (IST)发布时间:2022年主题类型:漏洞检测通信作者主页:https://seg.inf.unibe.ch/people/timo/笔记作者:WNN@2023
2 研究概述
信息技术不断发展,软件规模也在不断扩大,那不可避免的软件漏洞也在增多,而软件漏洞的存在,极有可能导致软件密集型的系统成为被攻击的目标,从而造成信息丢失、系统故障的巨大危害,例如著名的 OpenSSL 上的 HeartBleed 漏洞。当下人工手动进行漏洞检测的速度必然无法满足需求,因此如何自动化完成漏洞检测便是当下一个重要的研究领域。在这个领域,目前具体的方法主要有三种,软件元特征、异常检测以及误用检测,而随着机器学习技术的成熟,该技术所带来的效果已经让研究者们感受到了“甜头”,因此本文的研究方法也和深度学习密切相关。
深度学习的应用无外乎研究对象、数据来源、表征方式、预处理、模型选择这几个方面。因此本文在这几个方面进行了考量,最终确定了其主要研究方案。

表1是对本文主要研究内容的一个总结。由于当下漏洞检测大多专注于 Java、C/C++以及 JavaScript,因此本文选择了关注较少但实际使用广泛的Python代码;此外在代码表征方面,在 AST 和源代码之间,选择源代码是因为考虑到模型能够学习 AST 捕获不到的更深层的代码语义,从而帮助获取更好的效果;模型选择不用多说,RNN/LSTM 在捕获上下文信息方面相比较 CNN 有着天生的结构优势。
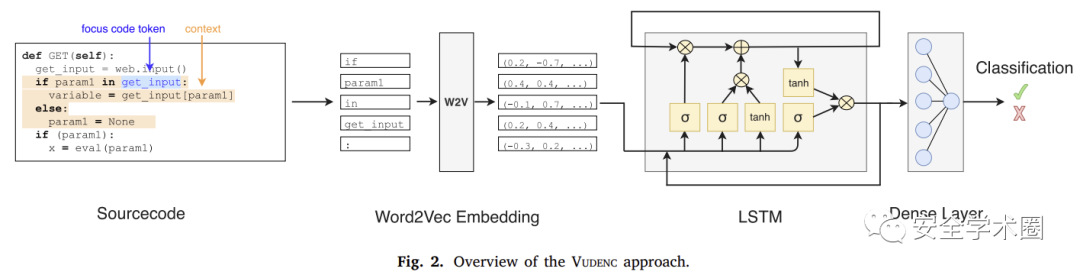
上图是论文整体研究流程,源代码由一个个 token 及其上下文构成,在经过分词器分词后送入 Word2Vec 模型嵌入为向量,最后将其输入到模型当中进行检测,输出最后的二分类结果。此外由于向量表征时使用的时源代码,可以使用同样的分词结果对代码进行不同上下文范围的置信度可视化,从而可能的定位代码漏洞位置,如图所示。

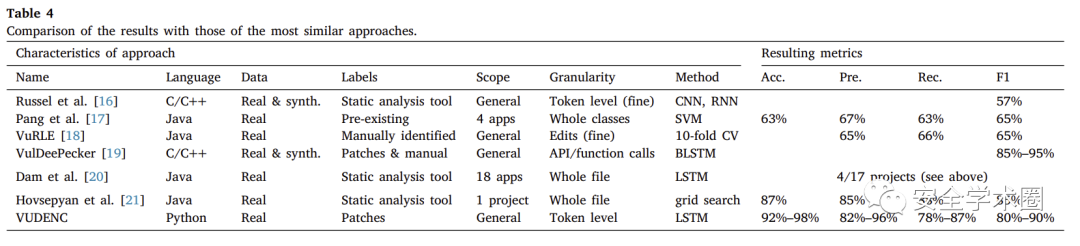
研究针对流程当中的 Word2Vec、LSTM 模型进行了有效性验证以及超参数调优后,对整个流程进行了实验性指标评估。如下图所示,结果表明该流程在精度、召回等多项指标由于其他类似方法,F1值达到80-90%,具有一定的参考价值。
3 贡献分析
贡献点1:论文针对当下Python代码漏洞检测研究较少的问题,提出了基于深度学习的漏洞自动化检测方法及工具,从研究对象到代码表征,再到模型选用上面进行了较为详细分析,实现了对Python代码中7种特定类型漏洞的检测,并且模型在构建的数据集上精度、召回和F1值分别达到了82%–96%、78%–87%以及80%-90%。
贡献点2:论文针对漏洞代码定位问题,提出了细粒度的分词与上下文捕获方法,在模型输入上选择对源代码分词粒度上进行分析,实现了能够在代码文本分词的基础上获取到模型的置信度输出,从而获取代码漏洞定位。
4 代码分析
代码链接:https://github.com/LauraWartschinski/VulnerabilityDetection
a) 代码使用类库分析,是否全为开源类库的集成?
论文合理使用开源类库。代码的主要工作由作者自己的代码实现,涉及Word2Vec、LSTM模型以及评价指标的部分分别使用对应的 genism 和 keras 以及 sklearn 类库完成。
b)代码实现难度及工作量评估;
整体代码实现难度及工作量不大。代码主要包含对 python 代码预处理、分析以及模型调用、训练的代码。由于模型架构并不复杂,因此模型部分代码并不困难,更多的问题可能在于代码预处理的一些细节实现上面,例如如何对代码进行分词、代码缺陷提取及标签、仓库爬取等。
c)代码关键实现的功能(模块)。
代码关键功能有三部分,分别为数据集构建、Word2vec向量化、LSTM模型。
数据集构建:首先获取仓库提交时的commit信息,并在此基础上过滤出满足漏洞关键字的仓库,进而获取到这些仓库commit时的差异代码,最终完成数据集构建。
Word2Vec向量化:获取足够大的Python语料库后,进行代码预处理,将语法、缩进等错误进行修改;进一步地,在此基础上完成代码分词,从而完成模型的训练;随后在进行LSTM输入时,提供了代码的向量化功能。
LSTM模型:构建LSTM模型,并且实现Dataset和DataLoader的功能。在此基础上完成模型的训练、评估等。
5 论文点评
这篇文章的主要研究方法并不复杂,这里将从论文整体、模型选用及实验部分进行简要分析。
a)论文整体
整体论文的结构比较合理,相比起该期刊的其他论文长度也比较适中。第二章相关研究方面总结的比较好,介绍清晰;第三章论文方法上面没有很好的突出创新性,个人感觉论文的亮点不足,尽管其在场景分析、模型选用方面做了较为详细的理论分析工作,但确实存在一些相对不必要的介绍,例如常用评价指标公式等;文章实验部分整体工作比较细致,在对词嵌入和分类模型上面做了较为细致的分析,在 GitHub 数据集也进行了分析介绍,但是在对类似方法比较的实验上可能不够合理, 同时缺少其他实验验证,这部分在下面进行补充。
b)模型选用
在模型选用上面,并没有选择当下表现最好的模型,而是使用了较为传统的Word2Vec以及LSTM。在这个方面论文尽管在理论上分析了模型的可用性,但却没有和当下表现更好的Code2Vec以及Transformer进行比较分析,这方面相信还是有提升的空间的,同时Transformer相比较只能串行输入的LSTM也能大大缩短训练时间,从而更快的完成模型迭代。另外,向量化使用的是静态向量,当Word2Vec模型训练后,无法及时迭代也会造成信息的不完善,因此考虑动态向量也是一共不错的补充。
c)实验部分
第四个对比实验种,由于针对语言不同,可能存在难度不一致问题,因此该实验的对比数据合理性需要进一步思考。此外个人认为可以补充一个验证性实验,在开放数据集上进行检测,并对其精度进行人工验证,从而进一步证明论文方法的有效性。
6 论文文献
[1]. Wartschinski L, Noller Y, Vogel T, et al. Vudenc: Vulnerability detection with deep learning on a natural codebase for python[J]. Information and Software Technology, 2022, 144: 106809.
论文团队信息
通信作者团队:https://seg.inf.unibe.ch/ Research at SEG concerns multiple facets of Software Engineering, reflecting scientific interests of its members.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
