2023年1月10日,《互联网信息服务深度合成管理规定》(以下简称《规定》)正式施行,《规定》要求深度合成服务提供者、技术支持者应当按照国家有关规定开展安全评估,落实信息安全主体责任并对深度合成服务提供者提出显著标识要求。2023年6月20日,国家网信办发布深度合成服务算法备案信息,包括阿里、腾讯、百度等41个厂商的算法榜上有名,深度合成技术已广泛应用于人脸图像、音视频生成、智能客服、即时通讯等场景,可能带来的安全风险再次引发社会关注。如何找到一种高效准确方法来识别检测图片、音频、视频的真伪,即:是否使用深度伪造技术已变得非常迫切。本文“基于改进型ViT的深度伪造鉴别算法”,从兼顾图像局部与整体特征角度优化改进,提出一种新的检测方案。
一、现有深度伪造检测技术背景
大多数深度伪造的检测模型都是基于CNN结构的。检测方法分为两种,一种是针对单帧的伪造信息进行检测,如人脸区域与背景分辨率的差异、生成人脸细节、篡改图像与真实图像存在分布上的差异;另一种方法是利用时间属性来发现视频帧之间的不自然。
1、帧内检测(空间信息)
许多学者基于各种CNN模型(即VGG16、ResNet50、ResNet101和ResNet152)来检测面部空间的篡改,并且开发出多种变体。然而由于CNN本身的局限性,一帧图像的每个部分都要互相交互和对比才能检测到篡改痕迹。针对DFDC数据集,当前主流检测模型是EfficientNet。基于EfficientNet的SOTA模型使用集成技术(将多个训练模型的预测结果进行平均)在DFDC数据集上实现了0.981的AUC。然而,这种使用二维CNN结构和空间特征的模型无法将远距离位置上的特征与时间信息相关联,要么耗时过长,要么性能不足。
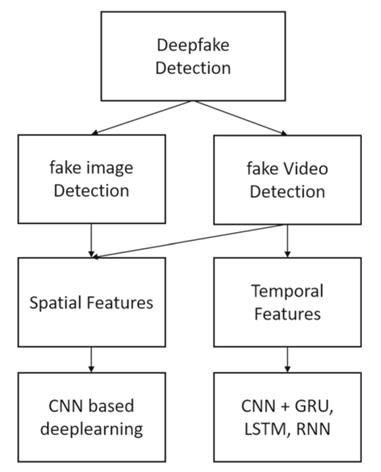
图1 基于空间信息的深度伪造检测网络结构图
2、帧间检测(时序信息)
伪造的人脸视频存在帧间不一致性,原因在于已有的伪造视频方法往往是将视频分解为单帧分别处理的,很少考虑前后帧之间的关联性。例如,许多伪造技术都使用人脸关键点检测,用于定位人脸的位置,但人脸关键点检测技术本身存在几个像素的误差。如果没有将误差考虑在内,生成的相邻视频帧的人脸位置就会存在明显的视觉差异。长短时记忆网络(long short term memory,LSTM)或光流估计可以对帧间的关联性进行建模。
然而,仅使用时间属性的检测模型往往表现不佳。例如,光流法伪造检测在使用Face2Face进行人脸篡改的测试集上准确率仅为81.61%。
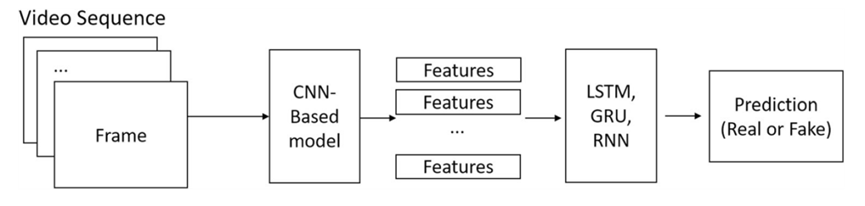
图2 基于时间信息的深度伪造检测网络结构图
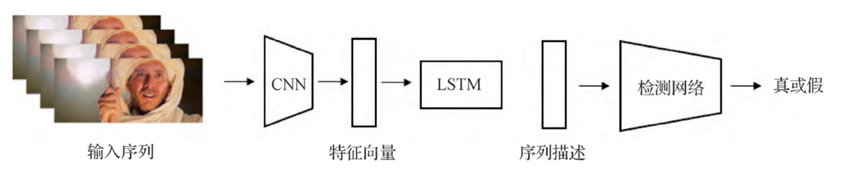
图3 基于LSTM的伪造检测网络结构图
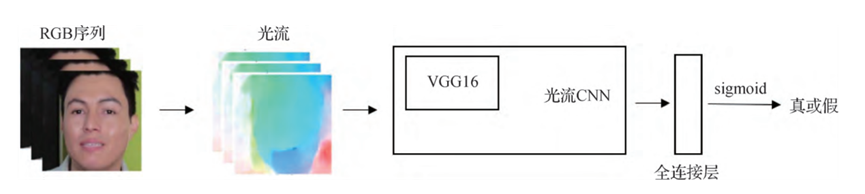
图4 基于光流的伪造检测网络结构图
3、ViT(vision transformer)模型
Transformer常用于自然语言处理,但近期很多研究将其应用在图像领域,发展出了ViT模型。与CNN相比,ViT模型更多地利用图像的全局信息。CNN使用卷积核通过过滤周围像素值来提取关键边缘,不考虑绝对位置。而ViT中的多头自注意力机制(MSL)能够察觉到整个图像内的关联信息。例如,CNN无法发现嘴巴和眼睛之间不同步的不自然关系,ViT却可以做到这点。
随着卷积核穿过整张图像,CNN模型的特征逐渐减少。图5说明了CNN模型的过程,在CNN结构的末尾,模型收敛到一个单一的特征并预测图像的类别。为了检测深度伪造图像,CNN模型通过搜索整个面部的局部特征来找到异常特征。
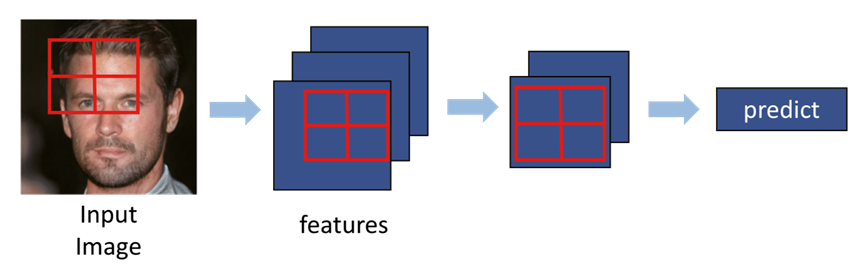
图5 CNN结构处理脸部图像
如图6所示,在ViT模型中,分类标记(class token)与所有局部特征进行交互,寻找局部特征和分类标记之间的关联。对于图像中被篡改的部分,分类标记会与被篡改的图像块强相关,与分类标记强相关的图像块会被视为“活跃区域”,这些区域在模型决策过程中起主导作用。而对于非篡改的部分,上述联系不存在。正因为这个特点,通过将图像块与class token的交互,ViT在寻找伪造图像方面表现异常出色。因此,本文作者考虑将ViT模型引入,与CNN结合起来,以达到更全面的深度伪造检测效果。
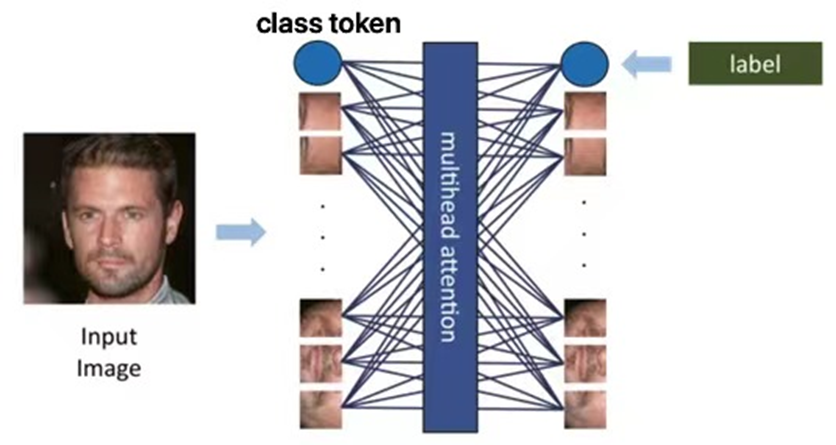
图6 ViT结构处理脸部图像
二、CNN与ViT结合的新模型
图7为作者提出的从视频预处理到训练再到预测的全过程。首先利用MTCNN模型在视频中提取人脸,再提取出关键点进行数据加强。预处理完的数据输入新模型,训练后即可预测视频是否为伪造。图8为新模型的网络结构。
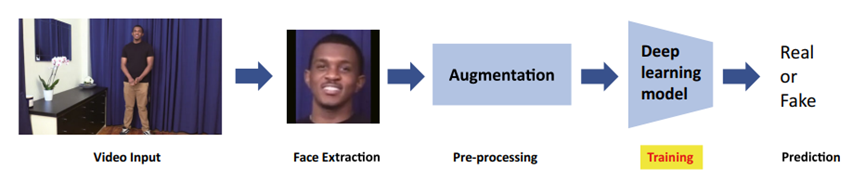
图7 新模型进行伪造检测的过程
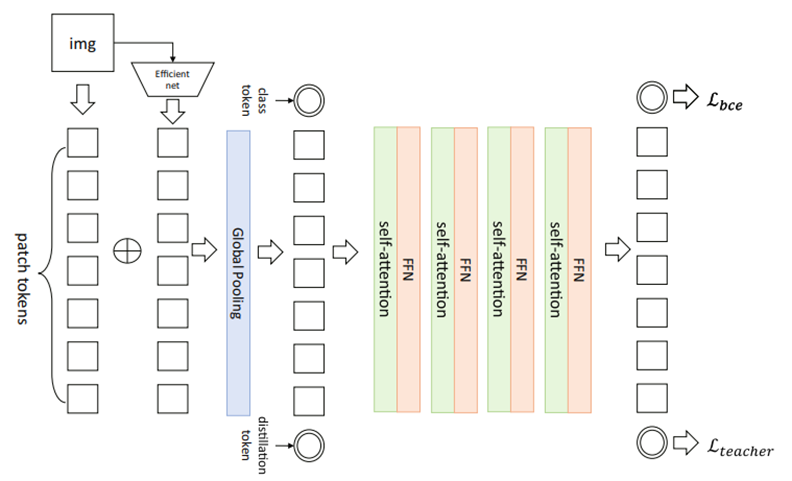
图8 新模型网络结构
1、数据预处理
数据预处理包括检测人脸,图像裁剪,提取关键点以及使用与伪造图像相似的结构化掩膜对真实图像进行预处理。这一步骤不仅可以提高模型的泛化性,也防止在训练过程中出现过拟合。

图9 图像预处理结果
2、图像块嵌入(Patch Embeddings)
标准Transformer使用一维标记嵌入序列(Sequence of token embeddings)作为输入。ViT模型作为Transformer模型的变体,也需要将二维图像转化成一维作为输入。具体方法是将图像  reshape成序列
reshape成序列 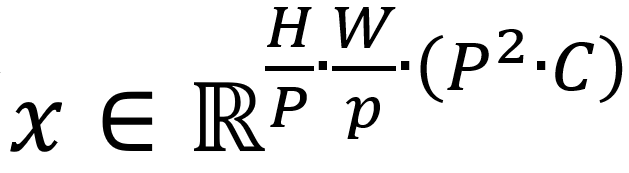 ,其中(H,W)为原始图像分辨率,C是原始图像通道数(RGB图像C=3),(P,P)是每个图像patch的分辨率,由此产生的图像patch数
,其中(H,W)为原始图像分辨率,C是原始图像通道数(RGB图像C=3),(P,P)是每个图像patch的分辨率,由此产生的图像patch数 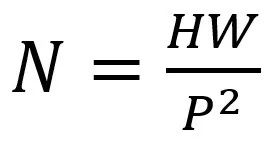 亦为ViT的有效输入序列长度。
亦为ViT的有效输入序列长度。
例如输入图片大小为224×224,将图片分为固定大小的patch,patch大小为16×16,则每张图像会生成个224×224/16×16=196个patch,即输入序列长度为196,每个patch维度16×16×3=768,线性投射层的维度为768×N(N=768)。因此,输入图像通过线性投射层之后的维度依然为196×768,即一共有196个token,每个token的维度是768。
3、图像块嵌入与CNN(EfficientNet)结合
图像块嵌入决定了块部分的图像特征,CNN部分决定图像整体特征,两者结合后进入全局池化层,比起只考虑单个结构特征性能更好。具体结合方式如下:
①定义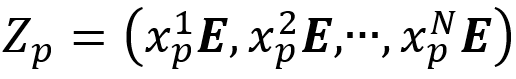 和
和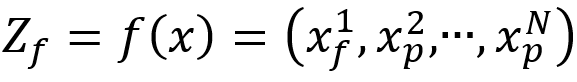 ,其中
,其中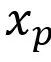 是某一个patch,E是一个可学习嵌入(相当于给patch另加一个token用于分类),N是patch的数量,M是CNN特征的数量,f(.)是CNN模型,这里指的是EfficientNet。
是某一个patch,E是一个可学习嵌入(相当于给patch另加一个token用于分类),N是patch的数量,M是CNN特征的数量,f(.)是CNN模型,这里指的是EfficientNet。
②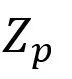 与
与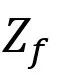 通过
通过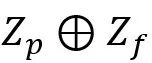 相结合,这里
相结合,这里 指的是按通道拼接(concatenate),之后再进入全局池化层,得到
指的是按通道拼接(concatenate),之后再进入全局池化层,得到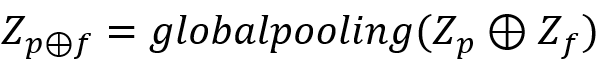 作为输入向量。
作为输入向量。
4、知识蒸馏方法与教师网络(DeiT)
在ViT模型中,处理好的patch在进入编码器前,需要加入一个特殊字符class token以达成分类的目的。而这里在ViT架构基础上引入了Distillation token,其地位与Class token相等,并且参与了整体信息的交互过程,这就是DeiT模型。DeiT模型是学者针对ViT需求数据量大的问题而提出的,其核心是将蒸馏方法引入ViT的训练,引入了一种教师-学生的训练策略,这种训练策略使用CNN作为教师网络进行蒸馏,能够比使用transformer架构的网络作为教师取得更好的效果。
因此,在前面池化层输出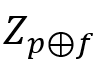 的基础上,新模型结构重新定义了输入:
的基础上,新模型结构重新定义了输入:
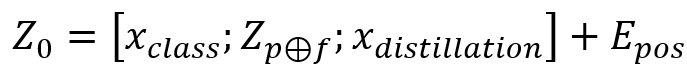
其中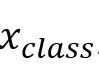 和
和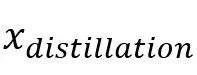 是标签和教师网络的标签,
是标签和教师网络的标签,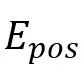 是一个可学习位置嵌入。最后,损失函数定义如下:
是一个可学习位置嵌入。最后,损失函数定义如下:
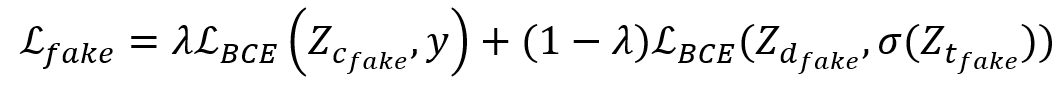
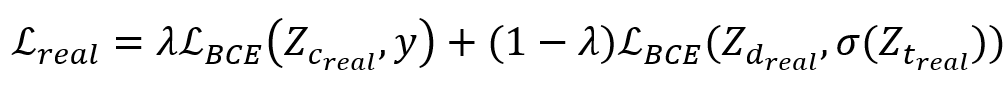
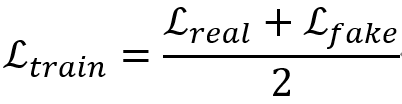
其中,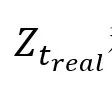 和
和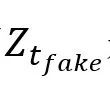 是教师模型对真伪预测的logit值,
是教师模型对真伪预测的logit值, 是蒸馏标签和分类标签对真伪预测的logit值。根据实验分析,λ设定为1/2,
是蒸馏标签和分类标签对真伪预测的logit值。根据实验分析,λ设定为1/2,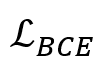 为二值交叉熵(binary cross entropy),σ为sigma函数。
为二值交叉熵(binary cross entropy),σ为sigma函数。
根据其他研究,这种蒸馏方式能够有效地防止过拟合,而且当CNN作为教师网络时,Transformer会展现出最佳性能。因此,本文在新模型中选择了在DFDC上表现优异的EfficientNet作为教师网络。
三、实验结果
1、DFDC数据集
DFDC数据集是Facebook AI团队发布的目前最大的公开深度伪造数据集(截至论文发稿时),包含了约10万个由GAN生成的视频。DFDC完整数据集总共有128,154个视频,其中104,500为伪造视频。
针对DFDC数据集,我们提出的自研新模型方案(以下简称新模型)与作为SOTA模型的2D CNN网络模型EfficientNet相比表现出了更好的性能。表1(左)显示了在DFDC数据集上,新模型和最近现有模型的AUC、F1分数和复杂性。在相同条件下,SOTA模型的AUC为0.972,而新模型在没有集成方法的情况下AUC达到了0.978。在相同的阈值条件下,新模型达到了0.919的F1分数,而SOTA模型的F1分数为0.906。此外,与近期的其他模型(Li,Mittal等)相比,新模型的AUC提高了0.17。通过集成方法,新模型在DFDC数据集上最终实现了0.982的AUC,而SOTA模型只能实现0.981的AUC。
2、 Celeb-DF(v2)数据集
Celeb-DF(v2)数据集包含590个真实视频和5639个合成的高质量假视频。表1(右)显示了在Celeb-DF(v2)数据集上,本文模型和最近现有模型的AUC、F1分数和复杂性。总体而言,除了R3D模型以外,比起其他模型,新模型的AUC都有提高。这意味着,改进的ViT模型也能够在其他数据集上表现出良好的性能。
尽管复杂性较高,本文模型通过将ViT模型与CNN模型相结合,展现出更好的深度伪造检测性能。从表1可以看出,提出的新方案在DFDC和Celeb-DF(v2)数据集上实现了更好的AUC和F1分数。特别是在Celeb-DF(v2)数据集上,观察到非常高的F1分数(0.978)。

表1 在DFDC(左)和Celeb-DF(v2)(右)数据集上新模型的表现
四、结论与展望
本文提出的新模型依然局限在单帧图像检测中,仅考虑单帧的帧内特征,可能会错过伪造视频中的相邻帧之间的“不自然”信息。目前,上海市信息安全测评认证中心正在研究能够将视频帧间信息加以利用的新方案,进一步提升针对视频画面的真伪检测能力,为《互联网信息服务深度合成管理规定》落地做好技术支撑。
参考文献:Heo Y J, Yeo W H, Kim B G. Deepfake detection algorithm based on improved vision transformer[J]. Applied Intelligence, 2023, 53(7): 7512-7527.
声明:本文来自测评能手,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
