
最近,基于深度伪造技术的篡改视频在社交媒体上广泛传播,引发了人们对视频内容真实性的怀疑和个人隐私保护的担忧。尽管现有的方法现有的深度伪造检测方法在某些特定场景下取得了显著的进步,但随着深度伪造技术的快速发展,现有的基于帧的深度伪造视频检测方法陷入了一个困境,即基于帧的方法在遇到精细伪造的图像时可能会失败。为了克服上述问题,许多方法试图对视频的时空不一致性进行建模,以区分真实和虚假的视频。然而,目前的工作通过结合帧内和帧间信息对时空不一致性进行建模,但忽略了面部运动造成的干扰,这将限制检测性能的进一步提高。
为解决这个问题,本文研究了长距离和短距离的帧间运动,并提出了一种新颖的基于动态差异学习的深度伪造视频检测方法,以区分由面部操作引起的帧间差异和由面部运动引起的帧间差异,从而为深度伪造视频检测建立精确的时空不一致模型。所提模型整体结构如图1所示:
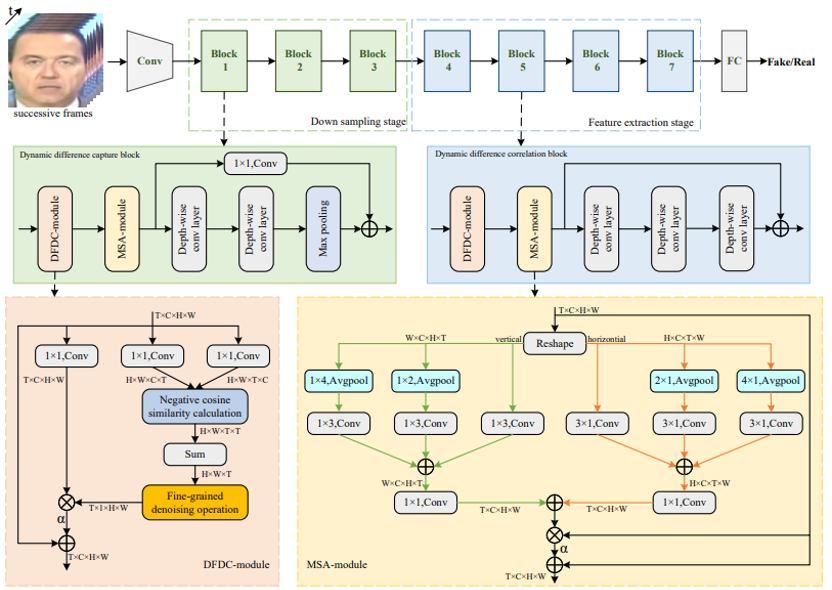
图1 模型整体结构图
具体来讲,本文提出了两个即插即用的模块,动态细粒度差异捕获模块 (Dynamic fine-grained difference capture module,DFDC-module)和多尺度时空特征聚合模块(Multi-scale spatio-temporal aggregation module,MSA-module)。这两个模块兼容各类2D CNN网络,与之融合可以使它们都有一定地建模时空特征的能力。
DFDC模块通过自注意力机制实现帧间差异的计算,形成注意力权重指导网络定位空域上的帧间差异。然而,此种帧间差异不仅包含了篡改操作遗留的伪造痕迹,还包含了正常脸部运动引起的脸部区域差异。为了消除脸部运动的干扰,我们进一步设计了细粒度去噪操作。一般来讲,由脸部篡改引起的帧间差异是突兀,而有脸部运动引起的帧间是连续、平滑的,因此,我们通过衡量帧间差异波动强度的大小来减轻脸部运动的干扰。

图2 DFDC模块的去噪能力
如图2所示,我们对连续的六帧进行DFDC操作并对注意力权重进行可视化。我们可以发现,引起了细粒度去噪操作不仅可以减轻脸部运动带来的干扰,还可以进一步突出伪造痕迹。通过DFDC模块,我们实现了将不一致信息从时域映射到空域,然而,如何将空间域的帧间差异特征关联起来,形成统一的时空不一致特征,以判断输入样本的真实性,仍然是一个问题。为此,我们设计了MSA模块对输入特征图进行时序维度的多尺度多方向的切片操作,并应用相应的条形池化操作和卷积操作来聚合帧间时空不一致信息。
表1 在FaceForensics++数据集上,所提方案与其他方法的检测结果对比
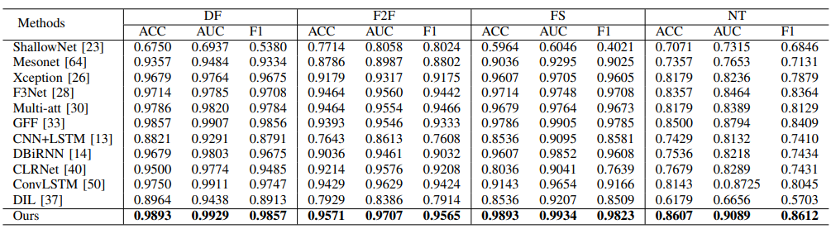
表2 在Celeb-DF和DFDC数据集上,所提方案与其他方法的检测结果对比
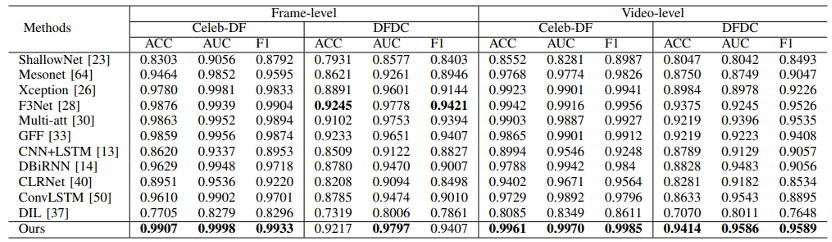
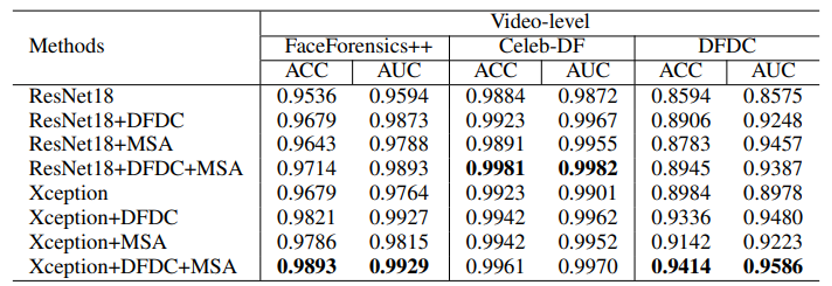
如表1和表2所示,在FF++,Celeb-DF和DFDC数据集上的实验结果表明,我们提出的方法优于多种先进的帧级或视频级深度伪造视频检测方法。此外,本文还验证了所提模块的兼容性。如表3所示,与不同的骨干网络融合,所提模块都能使它们在深度伪造检测任务上的性能获得一定的提升。
表3 DFDC模块与MSA模块的兼容性
论文信息
相关工作于2023年录用并发表于IEEE Transactions on Information Forensics and Security,作者为中山大学殷琪林,卢伟,深圳大学 李斌,黄继武。
Qilin Yin, Wei Lu, Bin Li, Jiwu Huang, "Dynamic Difference Learning with Spatio-temporal Correlation for Deepfake Video Detection," in IEEE Transactions on Information Forensics and Security, 2023, doi: 10.1109/TIFS.2023.3290752.
供稿:殷琪林,中山大学计算机学院网络空间安全研究所
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
