
原文标题:Exploring Pre-trained Language Models for Event Extraction and Generation
原文作者:Sen Yang, Dawei Feng, Linbo Qiao, Zhigang Kan, Dongsheng Li原文链接:https://aclanthology.org/P19-1522.pdf发表会议:Association for Computational Linguistics笔记作者:soda@安全学术圈笔记小编:黄诚@安全学术圈
1、研究介绍
事件抽取存在两个问题:
(1)论元角色重叠问题:事件中的论元可能存在多个角色。例如,"The explosion killed the bomber and three shoppers"中的论元"the bomber"同时身为"Attacker"和"Victim"两个角色。目前论元角色重叠现象较多,但是大多数方法在评估时将其简化:例如,只要预测命中其中一个角色,就算模型预测成功,这与现实世界明显是不相符的。
(2)训练需要大量标注数据:传统的事件抽取方法通常依赖人工标注的数据,难以获取且规模有限,所以需要使用事件生成方法生成训练所需的事件。其中最常使用远程监督方法对外部语料库进行标注,但生成数据的质量过度依赖于源数据。
针对上述问题,作者提出了一个基于预训练语言模型的框架,主要包括事件抽取与事件生成两个部分。作者首先提出了一个事件抽取模型,在BERT的基础上添加了多组二元分类器,每一组分类器代表一个论元角色,对基于角色重要性的损失函数重新加权,解决了论元角色的重叠问题;作者又提出了一种事件生成方法,以现有样本为原型进行论元替换和辅助字符重写,并对生成的新事件打分,选择其中的高质量样本,新事件的标注与原型相同,实现了新样本的自动标注,解决了训练数据不足的问题。
2、主要思路
基于预训练语言模型的事件抽取器(PLMEE)

作者所提出的PLMEE模型架构图如上图所示,由触发词抽取器和论元抽取器组成,其中论元抽取器利用触发词抽取器的结果进行推理。并且,作者使用基于角色重要性的损失函数,来提升抽取器的性能。
(1)触发词抽取器
触发词抽取器的目的是预测出触发了事件的字符,因此,作者将触发器抽取定义为字符级别的多类别分类任务,分类标签是事件类型。整体的触发词抽取器由BERT和一个多类别分类器构成。
触发词抽取器的输入为WordPiece嵌入、位置嵌入和segment嵌入的和。
触发词有时不是一个单词而是一个词组,因此,作者将相同预测标签的连续字符视作一个完整的触发词,同时在微调过程中使用交叉熵损失函数。
(2)论元抽取器
根据提取出来的触发词,提取相关的论元与其对应的角色。
论元提取的常见问题:
大多数论元为长名词短句
论元角色重叠问题
为了解决这两个问题,作者在BERT上添加了多组二分类器,每一组分类器代表一个论元角色,并决定这个角色对应的所有论元的跨度(包含开始和结束位置)。由于将角色分开进行预测,同一论元能扮演多个角色,同一字符也可以属于不同的论元。
基于预训练语言模型的事件生成方法

作者提出的预训练语言模型的事件生成方法主要框架如上图所示,主要包括三个阶段:预处理、事件生成、打分。在事件生成阶段包括论元替换与辅助字符重写两个步骤:
(1)论元替换
为了生成事件,需要对输入的原型语句先进行论元替换,使用ELMO(可以避免OOV问题)来对论元进行嵌入,并使用余弦相似度来衡量论元之间的相似度,选取相似度top10的论元,使用softmax计算概率,取概率最高的论元作为替换论元。同时,一个论元有80%的概率发生替换,20%的概率保持不变,使表示偏向真实事件。触发词保持不变,避免依赖关系产生偏差。这样就可以实现替换后的论元与原来的论元角色相同、语义上相似且上下文一致,这样就可以继续使用原来的标签作为新生成语句的标签。
(2)辅助字符重写
论元替换后的结果上下文固定,可能会导致过拟合。为了平滑数据并拓展其多样性,作者定义句子中除触发词与论元之外的字符为辅助字符(包括单词、数字和标点符号等),使用微调后的BERT对语句进行进一步的辅助字符重写。
在打分阶段根据困惑度(perplexity ,反映生成数据的合理性)和距离(生成数据和原有数据集间的距离)来对生成句子的质量进行评估。
实验结果
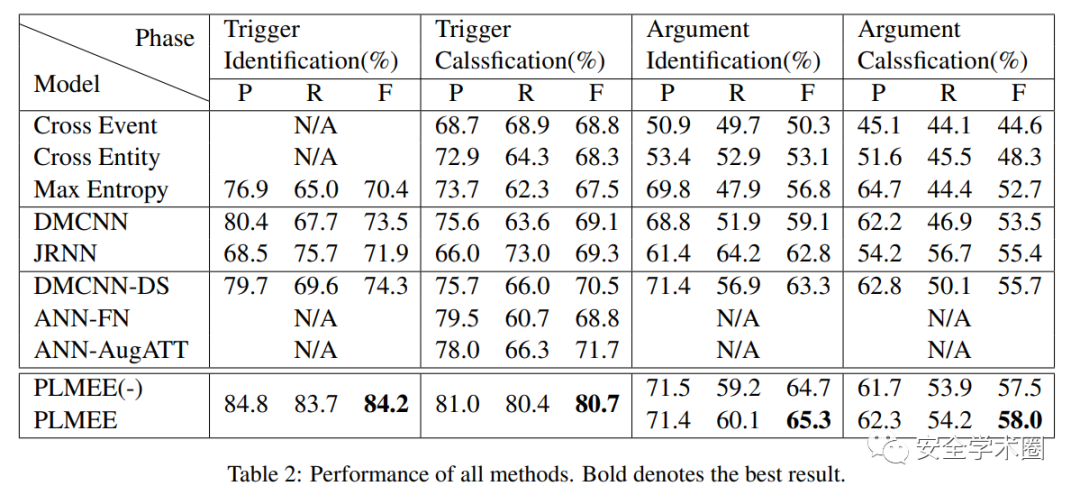
3、个人思考
本文针对论元角色重叠问题和训练数据标注问题所提出的解决方法有较好的参考价值,但仍然存在一定的局限性。
作者所使用的EE模型采用的是流水线式抽取的方法,即先抽取触发词,再抽取论元,存在误差传播的问题(导致误差在流程中传递与累加,即前面的触发词提取错误导致的后续论元错误,误差进一步加大)。可以考虑更换为更加精准的联合抽取。
同类型事件之间存在相似性、同时出现的论元角色之间存在紧密的联系,而作者所提出的模型忽略了此类特征。后续可以考虑把事件之间的关系和论元之间的关系纳入预训练语言模型中。
尽管作者所提出的生成方法可以控制生成样本的数量并进行质量过滤,但仍然存在着与远程监督类似的角色偏差。
论文团队信息
通讯作者团队:李东升(Dongsheng Li):国防科技大学教授,CCF杰出会员。曾获全国优秀博士学位论文奖,国家优秀青年科学基金。主要研究方向为分布式计算、云计算、数据中心资源管理、大规模数据处理等。邮箱:dsli@nudt.edu.cn
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
