医学成像、音频和人工智能的最新进展为医疗保健和研究带来了前所未有的可能性。以英国为例,其公共卫生系统充斥着人口规模级别的电子患者记录。
借助丰富的数据资源,加上强有力的学术和研究计划,英国正在推进及时和有影响力的健康研究,以提供更有效的治疗,用于跟踪和预防公共卫生风险,甚至拯救生命。
在国际上,医院每年产生的数据估计有50 PB,利用这一数据资源能够产生的巨大的公共利益,特别是人工智能辅助分析对于实现大健康数据的价值至关重要。
但站在患者角度,健康数据本质上属于个人,如果健康数据被滥用导致用户隐私受到损害,可能会导致公众对于医疗机构的不信任。
针对上述问题,隐私计算技术发挥了至关重要的作用,特别是在欧盟严苛数据保护条例下,它的作用更加明显,下面从联邦学习在医学影像领域的应用出发,梳理一下隐私计算技术在医学领域的现状和挑战。
01 联邦学习在医学成像领域中的应用
主要隐私风险
磁共振成像(MRI)是一种利用强磁场和无线电波产生身体内部和内脏详细图像的扫描。MRI扫描产生的图像为疾病进展的诊断和分期提供了关键信息。
MRI图像集可用于训练机器学习算法,以检测图像中的某些特征或异常。这项技术可以用于筛选大量图像,进而识别将患者行为、遗传或环境因素等变量与大脑功能联系起来的模式。
MRI成像和元数据可以揭示患者的敏感信息。事实上,即使是个人在数据集中的存在也可能是敏感的。虽然可以通过删除姓名、地址和扫描日期来识别图像本身,但有时可以重新识别神经图像。
联邦学习技术
联邦学习是一种远程执行模式,其中模型在本地训练好之后“发送”到服务器进行聚合。这可以让研究人员在不访问这些数据集的情况下使用其他站点的数据来优化模型。
例如,如果不同大学的研究人员持有神经成像数据,联邦学习方法将允许他们根据所有参与者的成像数据训练模型,即使这些数据对分析师来说仍然“不可见”。
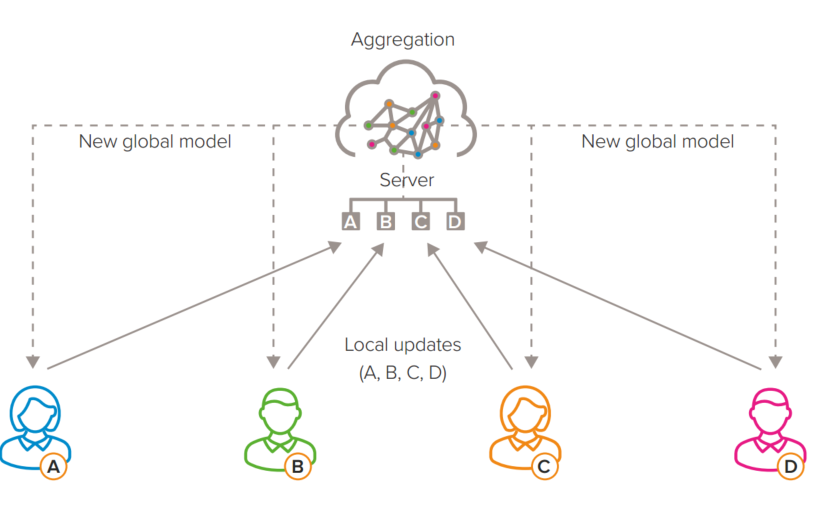
在这种情况下,有两种方法可以实现联邦学习:
(1)每个站点分析自己的数据并建立模型;然后将该模型共享到所有相关研究人员共同的远程服务器(集中节点)。然后,该节点将所有模型合并为一个“全局”模型,并将其共享回每个站点,研究人员可以在那里使用新的模型
(2)模型是迭代构建的,其中远程节点和本地节点轮流发送和返回信息。
无论哪种方法,所有用户的模型都是通过从远程数据集“学习”来改进,而这些数据集本身从未被揭示。通过使用联邦学习,原始数据不共享,从而排除了与数据保护相关的最常见问题。
同时,联邦学习并不能提供完美的隐私,模型仍然容易受到一些高级攻击。这些袭击的风险可能足够低,各方都可以接受,这样他们就可以继续进行。
当然也可以采取其他保障措施。这些可能包括检测何时对MRI数据集进行重复查询,该数据集可以与公共数据交叉引用以重新识别受试者
现有开源平台
COINSTAC是一个开源的跨平台应用程序,由佐治亚州亚特兰大的神经成像和数据科学转化研究中心(TReNDS)创建,它说明了如何通过联邦学习和隐私保护算法克服神经成像中的数据访问障碍。
COINSTAC允许无法直接共享数据的用户使用可以在任何环境(如个人设备、私人数据中心或公共云)中运行的软件包,协同运行开放、可复制的联邦学习和协调预处理。
它使用容器化软件(在一个环境中运行所有必要代码的软件,无论主机操作系统如何都是可执行的,因此在各个平台上是一致的),此软件可在GitHub上获得MIT许可。
COINSTAC开发人员已经记录了几个案例。在一项研究中,使用欧洲和印度数据集的联邦分析发现,青少年大脑灰质的结构变化与年龄、吸烟和体重指数(BMI)有关。
另一个案例研究使用联邦神经网络分类器在静息状态功能MRI(fMRI)数据中区分吸烟者和非吸烟者。联邦模型通常会获得与使用合并数据的模型类似的结果,并且比仅从孤立站点提取数据的模型更好。
此外,TReNDS研究人员正在开发用于深度学习的优化算法,以在不牺牲准确性的情况下减少传输带宽。
在第三个例子中,大脑年龄估计算法被训练来使用神经成像预测实际受试者年龄;然后将其应用于估计新受试者的生物大脑年龄。这是有用的,因为生物大脑年龄的估计和实际年龄之间的巨大差距是阿尔茨海默病等大脑疾病的潜在生物标志物。该模型获得的结果在统计学上与集中式模型相当。
TReNDS目前还正在开发一个COINSTAC Vault网络,这将使研究人员能够对多个大型、精心策划的数据集进行联邦分析。这一开放科学基础设施将实现快速的数据重用,在不同的数据集上创建更通用的模型,并通过消除小型或资源不足群体的进入障碍来实现研究民主化。
02 未来:医疗数据分析的新兴隐私挑战
放射学在临床和研究环境中使用医学成像来诊断、治疗疾病和监测。基于机器学习的高质量模型可以提供图像的二次读取,充当医学研究人员和临床医生的“数字同行”。
一旦该模型能够识别疾病模式,就可以导出供其他临床医生和研究人员使用(如果该模型可以转移的话)。
导出模型后,原始创建者将放弃控制权。虽然模型不是“原始数据”,但也存在潜在的漏洞。过度训练的模型可能仍然忠实于训练数据集,以至于它们有可能泄露有关训练数据的细节。链接攻击可以获取来自模型的信息,当与第三方数据链接时,会导致个人数据暴露。
最后,模型反演或重建攻击可以允许攻击者对来自模型的训练数据集进行逆向工程。作为一种相对较新的可能性,模型反演中的风险收益评估相对不成熟。
数据保护法规(如英国GDPR)可能缺乏对敏感数据训练模型的明确性。传统上,模型被视为知识产权或商业秘密,而不是个人数据。
然而,“经过训练的模型可以将步态或社交媒体使用等看似不敏感的数据转化为敏感数据,如个人健康或医疗状况的信息。”
03 总结
训练机器学习模型需要大型、稳健的国际神经成像数据集。这些数据集存在于世界各地的各种机构中。安全地使用远程数据集来训练机器学习模型可以改变该领域的研究。此外,保护成像受试者的隐私可以增加对研究的参与度,增强未来神经科学进步所需的多样性和大规模数据。
本文由“开放隐私计算”翻译整理自《From privacy to partnership》节选,转载请注明来源。
声明:本文来自开放隐私计算,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
