作者丨陈际红 吴佳蔚 陈煜烺
2023年7月13日,《生成式人工智能服务管理暂行办法》(以下简称“《办法》”)正式发布,将于8月15日正式施行。生成式人工智能(Generative AI,以下简称“AIGC”)技术,是指具有文本、图片、音频、视频等内容生成能力的模型及相关技术[1]。AIGC全生命周期所牵涉的数据合规问题非常复杂,主要阶段包括模型训练、应用运行和模型优化,通常还涉及AIGC开发者、服务提供者、服务使用者等多方主体。本文将由面及点,从整体的视角提出管理AIGC数据合规风险的方法论,并就其中的数据合规焦点问题进行讨论。本文作为作者AIGC系列解读文章全景透视生成式人工智能的法律挑战(二)。
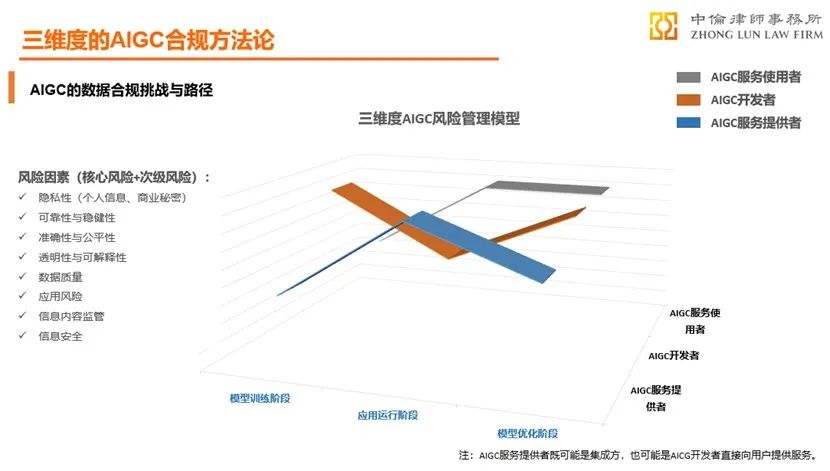
一、风险识别:三维度的AIGC数据合规风险管理框架
世界各国都在关注和研究人工智能的风险,美国国家标准技术研究院(National Institute of Standards and Technology)于2023年1月发布人工智能风险管理框架(AI Risk Management Framework,AI RMF)[2],该框架明确了AI系统的生命周期及各阶段的参与者、关键维度,为人工智能的风险管理提供了系统化的评估路径。我们参考该AI RMF,结合AIGC业务特点提出三维度的数据合规风险管理框架。
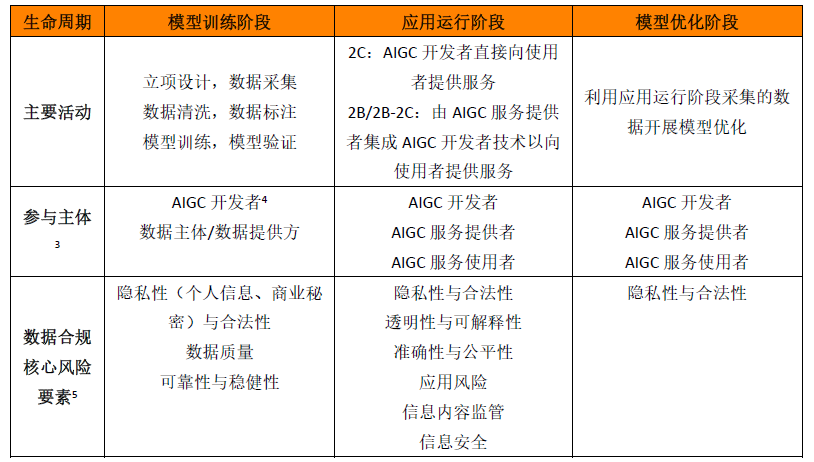
AIGC的生命周期大体可包括模型训练、应用运行和模型优化三个阶段,各阶段涉及各方主体的数据处理活动及其风险因素如下:
点击可查看大图
(一)模型训练阶段
处理活动及典型风险:AIGC的技术本质是通过既有数据寻找规律,并通过适当的泛化能力生成内容。模型的成熟度及生成内容的质量都与训练数据高度相关,故此阶段涉及大量数据收集,并对此等数据进行清洗和标注(tokenization)后用于模型训练和验证。数据清洗、标注及模型训练存在内部性,需要重点关注AIGC模型(及所用于训练的数据)的可靠性与稳健性以及数据质量(真实性、准确性、客观性、多样性[6]),并根据《办法》第八条制定标注准则、开展数据标注质量评估、抽样核验等;而数据收集的风险则需关注数据源合法性,《办法》第七条即要求AIGC服务提供者“使用具有合法来源的数据和基础模型”,典型数据收集形式及合规风险包括:
采取网络爬虫等形式爬取数据,具体分析见下;
收集已合法公开的公共数据,例如收集根据各地政务数据共享开放条例所合法公开的数据;
直接收集:直接面向人信息主体收集数据,如收集其个人信息,则需满足个人信息合规的要求;
间接收集:面向数据提供方间接收集数据,核心风险在于确保数据源合规,需对该等数据提供方采取合规管理措施;
合成数据(计算机模拟生成的数据),应主要关注数据质量。
主体:模型训练阶段的数据合规责任主体主要为AIGC开发者及数据提供方。
(二)应用运行阶段
处理活动及典型风险:将AIGC技术投入部署,包括直接提供2C应用、提供应用接口(也称MaaS,Model as a Service,“模型即服务”,具体包括“API-标准化服务”和“API-定制化服务”)或私有化部署,即可实现人机交互。具体而言:
AIGC服务使用者可能在使用服务时输入个人信息、公司商业秘密、他人享有著作权的作品;
而AIGC生成内容时也可能存在隐私风险及数据泄露等风险;
就AIGC服务提供者处理、分析数据而言,可能存在超目的处理、未就数据共享、数据跨境进行充分告知并取得有效同意等风险;
而就对外提供AIGC服务本身,也将面临可靠性与稳健性、透明性与可解释性、准确性与公平性等风险。
主体:应用运行阶段的典型数据保护责任主体是AIGC服务提供者,其中既包括AIGC开发者直接面向AIGC服务使用者提供服务,也包括通过引入第三方AIGC开发者技术能力进而面向AIGC服务使用者提供服务的服务提供者。
(三)模型优化阶段
处理活动及典型风险:基于人机交互所收集的数据,可能被用于模型的迭代训练。一方面,此等迭代训练过程同样面临模型训练阶段的可靠性与稳健性、透明性与可解释性、准确性与公平性等风险;另一方面,此阶段的外部风险集中在向AIGC服务使用者提供服务时,需明确就此等模型迭代训练等处理活动事先告知AIGC服务使用者并取得有效同意。
主体:本阶段的典型数据保护责任主体主要是利用人机交互所收集数据开展模型迭代训练的AIGC服务提供者和开发者,其中,在私有化部署及“API-定制化服务”等模式下,集成AIGC技术的服务提供者将可能构成责任主体。
二、合规挑战:我国监管框架下的典型数据合规问题
上述三维度合规风险管理框架适用于AIGC所涉相关主体开展系统化的风险识别、管控及合规设计。以欧盟和美国为代表的国家和地区一方面继续在GDPR等现行立法框架下将AI纳入监管范畴,同时亦在近期出台了一系列针对人工智能监管的专门立法或标准。
本部分就我国AI法律框架下的五个典型数据合规问题进行分析。
问题一:如何管理爬取数据的风险
网络爬虫通常是AIGC开发者收集数据并用于模型训练的常见手段。利用网络爬虫抓取数据的法律风险包括:
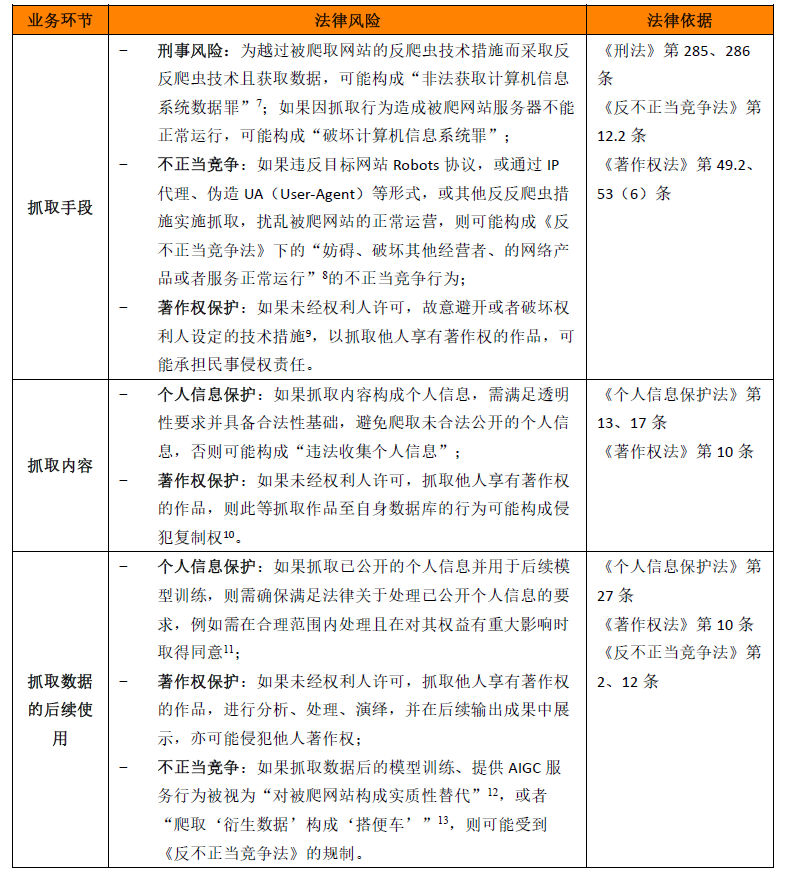
值得注意的是,尽管目前司法实践中大量案件通过《反不正当竞争法》规制网络运营者之间的爬取行为及使用行为,但《反不正当竞争法》的适用前提是网络运营者之间存在竞争关系,这就涉及对AIGC所涉及服务性质的认定,并结合二者是否存在相关市场、爬取行为是否可能对被爬网络运营者现实或潜在经济利益造成损害、是否争夺其交易机会或竞争利益(例如用户流量)等因素,具体仍有待于观察司法实践如何认定。
问题二:如何管理数据源风险
《办法》第七条要求AIGC服务提供者(含开发者)“使用合法来源的数据及基础模型”,不仅增加了对于数据的合法性要求,还强调了模型的合法性要求[14]。实践中,AIGC开发者可能通过引入第三方(数据提供方)数据以训练自身模型,也可能通过联合建模(但合作方数据不会提供至AIGC开发者)等形式开展。就AIGC开发者向数据提供方间接收集数据以用于模型训练的场景,核心在于确保数据源的合法合规。企业可对此等数据提供方采取的合规管理措施包括:
审查数据提供方是否具备提供数据的法律依据(legal basis),如涉及模型合作,还需审查模型是否具备合法来源。针对个人信息,应审查其是否具备提供个人信息的合法性基础[15];针对非个人信息,应确保所提供的数据不存在权属瑕疵;
与数据提供方签署数据处理协议或在业务合同中加入数据保护条款,明确各方权利义务及责任,以协议形式要求该数据提供方承诺数据源的合法合规;
针对数据提供方开展合规尽调,就其数据保护层面的安全能力、组织管理、操作规程等进行调查,避免因数据提供方的整体运营及业务模式不合规而影响合作持续开展;
要求数据提供方配合定期开展合规审计等。
问题三:AIGC应用运行及模型优化阶段典型个人信息合规问题
OpenAI在其官网公布的ChatGPT隐私政策中披露,其产品运营过程中会收集用户账户信息、对话内容(如含个人信息)、交流信息、社交媒体信息,以及日志信息、使用情况、设备信息、Cookies等个人信息,并表明其可能会利用AIGC服务使用者所提供的数据以开展模型优化和改进[16]。《办法》第十一条提出AIGC服务提供者的个人信息保护要求,强调“必要性”,以及不得“非法留存”和“非法提供”,在我国法律框架下,AIGC开发者/服务提供者所面临的典型个人信息合规问题包括:
透明性及合法性要求。《个人信息保护法》要求处理个人信息应告知AIGC服务使用者个人信息处理规则(例如通过隐私政策)并具备合法性基础(例如以勾选框等形式取得同意,或系为AIGC服务使用者提供服务所必需)。实践中,通常应当由直接面向AIGC服务使用者提供服务的AIGC服务提供者承担此等义务。
个人信息跨境。无论是境外AIGC开发者直接面向境内AIGC服务使用者提供服务,还是AIGC服务提供者接入境外AIGC技术API接口后向境内AIGC服务使用者提供服务,均可能涉及将AIGC服务使用者个人信息传输至境外。目前《个人信息保护法》《数据出境安全评估办法》《个人信息出境标准办法》均对个人信息出境提出合规要求,相关方应准确识别个人信息出境场景,选择出境合法机制(标准合同/安全评估/认证),开展个人信息保护影响评估(PIA),于隐私政策等文本中披露跨境情形,并具备相应合法性基础。《办法》第四章“监督检查和法律责任”第二十条特别提及来源于境外AIGC服务的场景,可以预见此等涉及跨境的AIGC服务将面临监管的重点关注。
将AIGC服务使用者输入数据用于模型优化。AIGC服务使用者可期待的个人信息处理目的往往并不包括将其数据用于非本次服务以外的目的,例如模型优化,因此将面临更高的用户权益保护风险。目前Open AI的做法是在隐私政策中披露该情况,并就Non-API模式采取默认同意用于模型优化、除非要求退出(opt - out)的机制,就API模式则采取默认拒绝用于模型优化、除非主动提供(opt - in)的机制[17]。在《个人信息保护法》的框架下,同意应采取opt - in的同意机制。
问题四:如何处理AIGC数据泄露风险?
据媒体此前报道,韩国某头部科技企业内部发生三起涉及ChatGPT误用与滥用案例,包括两起“设备信息泄露”和一起“会议内容泄露”。报道称,半导体设备测量资料、产品良率等内容或已被存入ChatGPT学习资料库中,随时面临泄露的风险。而出现这些事故的根源,均是因为员工将涉密内容输入到了ChatGPT。[18]
AIGC所涉及的数据泄露主要包括两类:
一类是基于AIGC自身产品/系统发生数据安全事件而导致的数据泄露,这就要求AIGC开发者及服务提供者根据相关规定制定数据安全应急预案,在发生数据安全事件时及时履行上报及通知义务,并对前述第三方系统/产品供应商采取安全层面的合规管理措施。
另一类是由于AIGC服务使用者输入数据中含有公司商业秘密或其他敏感数据(个人信息、重要数据等),导致该等数据进入AIGC学习资料库中,进而面临向他人输出内容时泄露此等数据的风险。企业如在内部引入AIGC技术能力时,应对员工的使用规则作出严格限制;而作为向AIGC服务使用者提供服务的AIGC服务提供者,一方面可通过用户协议或其他交互文本提示AIGC服务使用者应避免输入重要数据、他人个人信息等敏感数据,另一方面应采取一定技术手段防止此等因输出内容而导致的数据泄露发生。
问题五:AIGC开发者与服务提供者如何认定数据权属及相关责任
针对由AIGC服务提供者引入第三方AIGC技术(以下称“集成方”)以向AIGC服务使用者提供服务的场景,目前合作模式主要有两种,一种是MaaS(Model as a Service,“模型即服务”)模式,集成方通过接入AIGC开发者API从而使用其技术能力,具体包括“API-标准化服务”和可进行模型微调和数据训练的“API-定制化服务”;另一种是私有化部署,即AIGC开发者将其技术能力私有化部署至集成方[19]。由于此种情形下涉及两方主体,进而可能在数据权属、个人信息保护责任及AIGC监管责任等问题上存在潜在争议。
数据权属。私有化部署模式下,AIGC开发者通常无法接触、处理数据,故该模式下数据权属取决于AIGC服务提供者与AIGC服务使用者之间的约定(例如用户协议);而在MaaS模式下,由于AIGC开发者通常有能力接触和处理由AIGC服务使用者输入至集成方界面的数据,故除需考虑集成方与AIGC服务使用者的约定外,还需考量AIGC开发者与服务提供者之间的协议约定,因此,相关方应提前在协议中对此作出安排,例如AIGC开发者是否有权将AIGC服务使用者输入数据纳入训练数据库用于自身模型优化,避免引发权属争议。
个人信息保护。模型训练阶段的个人信息合规问题集中在AIGC开发者面向个人直接收集数据,此种情形其他合法性基础的论证空间有限,告知同意可能是必选项。而对于应用运行乃至模型优化阶段,争议场景仍聚焦在MaaS模式,此模式下存在多种数据流交互的场景,不同处理目的及各类数据流下各方责任将有所差别。目前《个人信息保护法》根据三种数据处理关系进行了责任分配[20],因此,服务提供者与AIGC开发者应当对于合作模式(核心为处理目的及数据流)进行清晰界定,例如,如果双方约定基于同一目的共同处理AIGC服务使用者输入的数据,且面向AIGC服务使用者提供服务时同时披露了两方主体,则构成共同处理关系,进而需依法承担连带责任。
AIGC监管责任认定。模型训练阶段由于不涉及服务提供者参与,故该阶段监管责任将直接面向AIGC开发者。在考虑开发者与服务提供者的责任分配时,由于开发者控制训练数据和算法,具有履责的技术优势,而服务提供者会面对用户端,系《办法》所规定的直接监管抓手,但由于其不掌握AIGC底层技术,仅有能力对自身可接触的环节负责(例如对基于API接口的模型开展进一步优化训练),《办法》正式稿第七条亦将此前征求意见稿中“应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责”调整为“应当依法开展预训练、优化训练等训练数据处理活动”,体现出鼓励技术创新的监管态度。据此,无论是私有化部署还是MaaS模式,均建议开发者和集成方通过签订协议等形式,将此等监管义务在法律允许范围内进行明确分配,对各自合规情况进行审计和核查并留存证明材料,以尽到审慎义务。
三、合规建议:关注不同主体身份的合规责任
AIGC的数据合规是一个大命题,建议相关方以“点面结合”的方式,一方面按照“三维度的数据合规风险管理框架”对AIGC全生命周期的数据合规风险进行整体识别,采取措施应对AIGC技术的可用性、机密性、完整性等信息安全风险,以及作为算法模型内生的可靠性与稳健性、透明性与可解释性、准确性与公平性等风险;同时重点关注业务开展中的典型数据合规问题。基于此,我们为AIGC相关方提供合规建议如下:
首先,针对AIGC开发者:
1) 规范数据收集活动,警惕爬虫风险。企业开展爬虫活动时应:(1)爬取公开的、非保密的前台数据,不应爬取非公开的后台数据;(2)避免采用破解密码、伪造设备IP绕过服务器身份校验、IP代理、伪造UA等技术手段以绕过或破解网站采取的保护数据的技术措施;(3)控制爬取的频率、流量等,不得因爬取数据导致被爬网站无法正常响应,甚至瘫痪。
2) 提高数据标注及清洗、模型训练阶段的透明性、可解释性及公平性,积极应对监管。模型训练阶段作为AIGC技术开发的开始,企业应采取措施,确保全程可控可见以及可审计和可追溯(透明性),使AIGC所使用的数据、算法、参数和逻辑对输出结果的影响能够被AIGC服务使用者理解(可解释性),保证所利用数据及开展决策时的公正、中立、不引入偏见和歧视因素(公平性)[21],由此,也可为应对后续应用运行及模型优化阶段的透明性、可解释性及公平性风险提供支撑。
其次,无论是AIGC开发者还是服务提供者,均应关注:
1) 加强第三方管理,提升可靠性与稳健性。数据提供方、系统/产品供应商等第三方作为外部实体,相较于内部管理具有不可控性和责任对立性。建议提前对其系统/产品可靠性与稳健性、合规情况、安全能力展开调查,并通过签订数据处理协议等形式就双方权利义务责任等予以明确,以缓释此等第三方主体的外部合规风险。
2) 开展个人信息保护影响评估(PIA),优先整改高风险事项。企业数据合规工作并非一蹴而就,如何在控制成本投入的同时与监管尺度、行业水位拉齐,需要企业做到有的放矢。从近期立法及执法动作来看,透明性、单独同意、个人信息出境、数据处理目的限定以及个人信息主体行权(例如是否可用于模型优化)已然是监管重点。AIGC开发者/服务提供者可对自身个人信息处理活动开展产品维度或业务维度的PIA,并就监管重点关注的高风险事项开展合规自查和整改,之后再逐步推进自身个人信息保护制度建设、操作规程等,建立数据合规的长效机制。
第三,针对AICG集成方:
如涉及集成AIGC开发者技术,应梳理合作模式,厘清数据权属,明晰各方责任。相较于私有化部署模式,MaaS模式下AIGC开发者与集成方的关系将尤为紧密。建议双方应对业务流、目的流、数据流进行清晰界定,并通过签订合作协议,于外部用户协议明确地披露服务提供主体等形式,事先对各方权利义务及责任作出安排,避免潜在争议。
第四,针对AIGC服务提供者:
防止数据泄露。为防止因AIGC技术不可预测风险而引发的AIGC服务使用者输入数据(尤其是含第三方敏感个人信息、重要数据等)对外泄露,AIGC服务提供者应通过用户协议等对AIGC服务使用者的使用规则作出限制,并事先制定数据泄露事件应急预案,以备不患。
最后,针对AIGC使用者:
1) 识别高风险应用场景,开展必要性审查并采取针对性措施。鉴于AIGC的应用存在隐私风险及数据泄露风险,建议对使用AIGC应用场景进行必要性审查,以及是否可以采用其他替代方案。此外,针对高敏感场景但有必要采用AIGC的场景,可设计针对性方案,例如采用私有化部署模式,以避免触发数据外泄、跨境传输等风险。
2) 规范AIGC使用行为,防止数据泄露。企业如欲在内部引入AIGC工具,建议在员工手册等内部制度中要求其不得输入保密数据等未向外部公开的数据。
3) 确保在依据AIGC输出结果采取行动之前进行人工审查。AIGC的技术原理决定其具有准确性和偏见层面的风险,企业应避免依赖AIGC输出结果直接采取行动,而应对其输出结果进行人工审查。
结语
除上述问题外,伴随重要数据界限逐渐明晰、网络安全审查实践等具有中国特色的机制逐次落地,新一轮AIGC技术狂飙或将面临中国本土的监管挑战。尽管如此,我们仍对AIGC在国内发展的前景充满信心,也对中国式治理实践充满期待。
[注]
[1]《生成式人工智能服务管理暂行办法》第二十二条第(一)项。
[2] See NIST AI 100-1 Artificial Intelligence Risk Management Framework (AI RMF 1.0). https://doi.org/10.6028/NIST.AI.100-1.
[3] 除本表所列主体外,实践中AIGC开发者/服务提供者还可能引入其他系统/产品供应商,以支撑其模型训练或业务运营的软件/硬件环境、技术支持等。
[4]《生成式人工智能服务管理暂行办法》第二十二条第(二)项所定义的“AIGC服务提供者”概念实际上已涵盖了“通过提供可编程接口等方式提供AIGC服务”的主体,为便于区分主体以厘清各方责任,本文针对此等“提供可编程接口的技术开发者”与“服务提供者”并非同一主体时,使用“AIGC开发者”的概念。
[5] 事实上,AIGC技术的模型训练、应用运行和模型优化等各个阶段涉及的数据合规风险要素包括:隐私性(个人信息、商业秘密)与合法性、可靠性与稳健性、透明性与可解释性、准确性与公平性、应用风险、信息内容监管、信息安全(完整性、机密性、可用性),本表仅列举各阶段所涉及的核心风险要素。
[6]《生成式人工智能服务管理暂行办法》第七条第(四)项。
[7] 司法实践中,诸如IP代理等行为均可能被认定为侵入性行为,典型案例包括:(2017)京0108刑初2384号、(2017)浙0110刑初664号、(2019)闽08刑终223号、(2016)浙0681刑初1102号、(2016)沪0115刑初2220号、(2016)浙0602刑初1145号。
[8]《反不正当竞争法》第十二条第二款规定,利用技术手段,通过影响用户选择或者其他方式,实施妨碍、破坏其他经营者合法提供的网络产品或者服务正常运行的行为,构成不正当竞争。
[9] 具体而言,技术措施包括两种:1)访问控制技术措施(又称防止未经许可获得作品的技术措施),该类技术措施是通过设置口令等手段限制他人阅读、欣赏文学艺术作品或者运行计算机软件;2)保护版权人专有权利的技术措施(又称保护版权专有权利的技术措施),即防止对作品进行非法复制、发行等的技术措施。
[10] 关于合理使用的讨论,请见此前文章全景透视生成式AI的法律挑战(一):知识产权挑战与路径。
[11]《个人信息保护法》第二十七条 个人信息处理者可以在合理的范围内处理个人自行公开或者其他已经合法公开的个人信息;个人明确拒绝的除外。个人信息处理者处理已公开的个人信息,对个人权益有重大影响的,应当依照本法规定取得个人同意。
[12] 例如点评诉百度案、点评诉爱帮案,案件具体情况参见(2016)沪73民终242号民事判决书、(2010)海民初字第24463号民事判决书。
[13] 例如“淘宝诉美景案”,案件具体情况参见(2018)浙01民终7312号民事判决书。
[14] 部分域外案例中,Clearview AI 和OpenAI的数据来源以及模型的合法性均受到法律挑战。
[15]《个人信息保护法》第十三条规定了处理个人信息的合法性基础,包括取得个人同意、基于履行合同或人力资源管理所必需、基于履行法定义务所必需等。
[16] https://openai.com/policies/privacy-policy,最后访问日期:2023年5月30日。
[17] 详情见Open AI: How your data is used to improve model performance, https://help.openai.com/en/articles/5722486-how-your-data-is-used-to-improve-model-performance,最后访问日期:2023年5月31日。
[18] https://www.thepaper.cn/newsDetail_forward_22643886,最后访问日期:2023年5月31日。
[19] 例如,近期开源ChatGLM-6B可以在消费级的显卡上进行本地部署,https://github.com/THUDM/ChatGLM-6B,最后访问日期:2023年5月31日。
[20] 例如,在《个人信息保护法》项下,委托处理关系通常由委托方对外承担责任,共同处理关系则由双方承担连带责任,对外提供关系则各自承担责任。
[21] 具体见全国信息安全标准化技术委员会 大数据安全标准特别工作组:《人工智能安全标准化白皮书(2023版)》。
作者简介
陈际红 律师
北京办公室 合伙人
业务领域:知识产权权利保护, 网络安全和数据保护, 反垄断和竞争法
特色行业类别:金融行业, 通讯与技术
吴佳蔚 律师
北京办公室 知识产权部
陈煜烺
北京办公室 知识产权部
声明:本文来自中伦视界,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
