机器之心报道,作者:邱陆陆
近日,谷歌科学家 Quan Wang 等在 arXiv 上发布了题名为 VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking 的一篇论文,介绍了团队在人声分离领域的最新进展,利用声纹识别技术,实现定向人声分离。

图 1:论文标题及作者截图
「语音识别」已经跟随着手机语音助手和智能音箱的普及变成了普通人日常生活的一部分,然而尽管包括谷歌、微软在内的诸多公司纷纷宣称其模型可以在标准数据集上「词错率降低到 6% 以下」、「水平超过普通人」乃至「水平超过专业速记员」,但是真实的场景里有很多标准数据集上不会出现的情况:远场问题、鸡尾酒会问题、中英文夹杂问题等等,这些情况的存在导致现实生活中,语音识别模型的效果还远远达不到人类的期望,亟待解决的问题还有很多。
人声分离是鸡尾酒会问题中一个比较难的分支,特指那些所有信号由同一麦克风收录,因此无法通过多个不同方向的麦克风解决的鸡尾酒会问题。人声分离问题的设定也有很多种,简而言之,是从有多个说话人同时发声的一段音频中,将不同人的声音区分开,以便对其中的某个(或每个)语音内容进行识别。现有的人声分离技术面临着三大挑战:
首先,现有人声分离算法几乎全部假设说话人数量已知,而在真实生活里,输入音频中同时说话的人的数量是未知的。
其次,在训练人声分离系统的过程中,如何保证置换不变性(Permutation Invariant),即确保时间轴上每一个点的说话者身份都与上一个点一致,对于经典的人声分离算法来说,也是一大难点。
最后,即使将不同说话者的声音成功分开,输出为多个人声频道,究竟哪一个频道是「有用的」目标频道,仍然需要设计额外的算法进行挑选。常用的做法是挑选音量最大的频道,但是在多种实际场景下,例如干扰者与目标说话者同样接近麦克风时,这种方法就有较大概率会失效。
VoiceFilter 用了「四两拨千斤」的一招处理了人声分离问题,他们请来了一位强有力的「外援」:声纹识别编码器(图 2 红色部分)。
VoiceFilter 网络的输入,除了含有噪声的人声时频谱(spectrogram)之外,还有一段代表目标说话者的嵌入码(embedding,又称 d-vector)。这段嵌入码是由声纹识别编码器从一段来自目标说话者的无噪声参考音频编码而成的。系统最终会根据这段嵌入码,定向地分离出有噪声时频谱中目标说话者的声音,效果如下。视频中分别展示了两段含有噪声的输入、目标说话者参考音频、以及分离后的效果。
VoiceFilter 网络(图 2 蓝色部分)由一个 8 层的卷积网络、一个 1 层的 LSTM 循环网络和一个 2 层的全连接网络组成。
输入信号的时频谱经过卷积层后,参考音频的嵌入码会被逐帧拼接到卷积层的输出上,一同输入 LSTM 层,最终,网络的输出是一段与输入时频谱维度相同的掩码(mask)。将输出掩码与输入时频谱相乘,即可得到输出音频的时频谱。
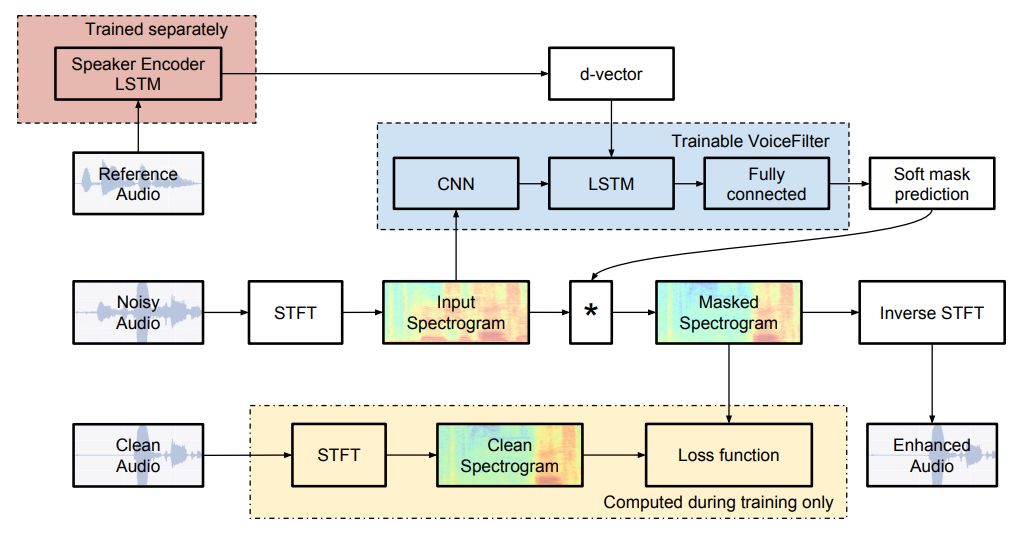
图 2:谷歌 VoiceFilter 的系统架构图。
VoiceFilter 系统分别在公开数据集 LibriSpeech 和 VCTK 上进行了试验。将训练好的 VoiceFilter 网络同时作用于多人环境与单人环境的测试集。在固定语音识别器不变的情况下,VoiceFilter 将多人环境下的语音识别词错率(Word Error Rate)从 55.9% 降至 23.4%,提升率超过 50%!在单人环境下,VoiceFilter 的词错率也维持在了正常波动范围内:从 10.9% 变化到了 11.1%。而在 VCTK 数据集上,VoiceFilter 则同时降低了多人环境与单人环境下的词错率。
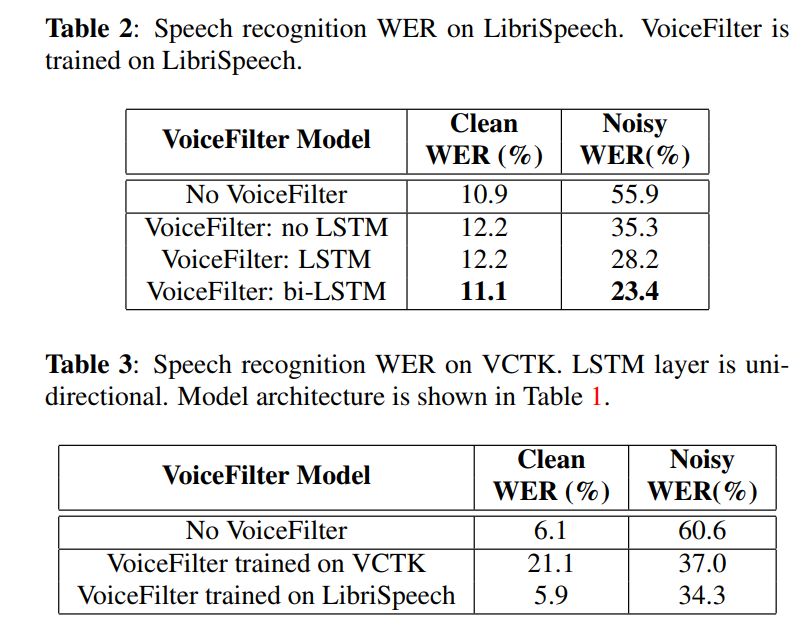
图 3:实验结果
此外,文中还给出了人声分离领域常用的指标 SDR(source-to-distortion ratio)。SDR 衡量的是分离后的信号中,包含的目标信号能量与噪声能量之比,以分贝为单位,越高越好。相同的神经网络架构下,VoiceFilter 的 SDR 能够达到 17.9 分贝,高于置换不变性训练方法下的 17.2 分贝。
声纹识别是一项已经发展非常成熟的技术,在 Pixel 手机与 Google Home 上,均有声纹识别系统的部署。这些设备中都有现成的目标说话者嵌入码(d-vector),VoiceFilter 系统部署到这类产品中时,不需要用户进行任何额外的交互。换言之,VoiceFilter 可以在没有为用户带来任何额外使用成本的前提下,实现无论用户的语音命令来自何种环境,被几个麦克风收音,都能在维持单人环境词错率不变的情况下,降低多人环境词错率。
原文链接:https://arxiv.org/abs/1810.04826
更多音频样本:https://google.github.io/speaker-id/publications/VoiceFilter
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
