为进一步促进数据高效流通和数据要素市场高质量发展,推动隐私计算产业蓬勃生长,持续向前。由中国信息通信研究院、中国通信学会、隐私计算联盟主办的2023隐私计算大会暨首届“星河杯”隐私计算大赛颁奖典礼活动于7月26日成功落地青岛,本场大会也吸引了过万人次关注。
大会上,中国信通院云计算与大数据研究所副主任闫树正式发布了“2023隐私计算行业观察“,从政策、市场、技术等角度总结了隐私计算现状,并针对当前发展挑战与热点现象带来思考和观察。

政策背景:多地政策纷纷出台,明确支持隐私计算发展
首先回顾数据要素相关政策,“大数据”自2014年3月首次写入政府工作报告至今,我国大数据领域政策不断落地与深化,在2019年我国将数据上升为生产要素,并在近几年不断围绕数据要素谋篇布局,同时出台多项细化政策加快推进技术、市场与制度完善。另外,近几年数据流通需求持续增强,并且数据流通的安全要求进一步强化。隐私计算是一类在保证数据提供方不泄露原始数据的前提下,对数据进行分析计算的一系列信息技术集合,可以保障数据在流通过程中的“可用不可见”,一定程度上满足数据流通的安全要求。2023年以来,部委及地方出台政策明确支持隐私计算的技术研究、产品研发和部署应用,这些政策对于隐私计算来说都是很好的推动作用。

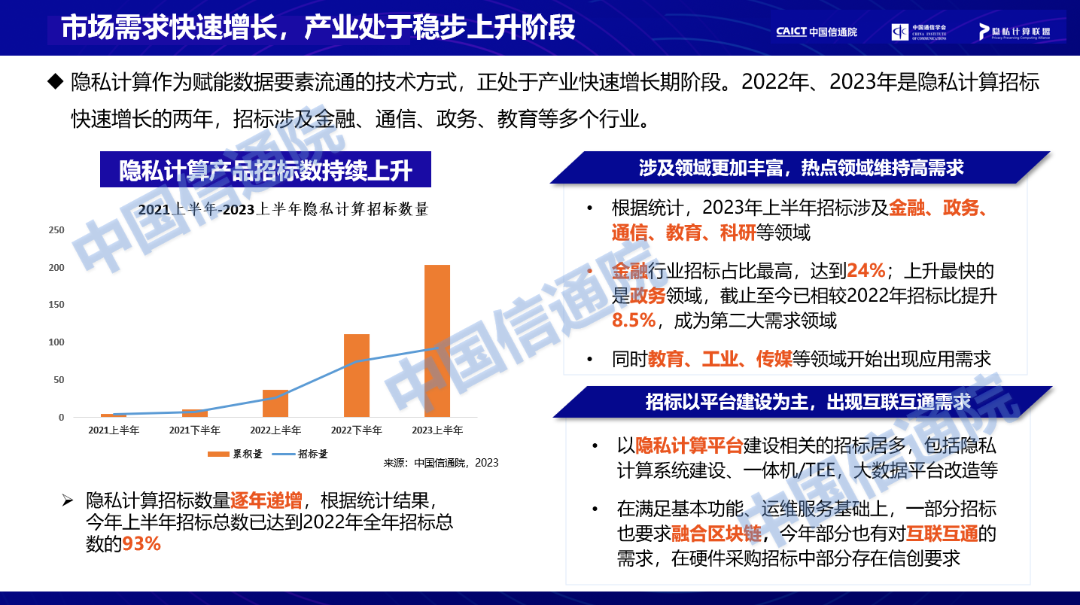
观点一:市场需求快速增长,产业处于稳步上升阶段
2023年隐私计算市场需求持续增长,当前隐私计算产业仍处于上升阶段。在招标数量方面,根据统计结果,从2021年至今,每年的招标数量逐年递增,今年上半年招标总数上升明显,已接近2022年全年的隐私计算招标量。另外,各个领域对数据流通的需求均有提高,招标不仅涉及金融、政务、通信、科研等众多领域,而且在工业、教育、传媒等领域也开始出现应用需求,其中政务领域招标量较去年上升最大。我们也看到,在数据流通基础设施和数据要素平台等建设的招标中也出现对隐私计算技术的要求。
观点二:开源提供新动能,持续助力生态繁荣
隐私计算通过开源一方面让算法和产品的安全性易于验证。另一方面,基于同一开放的算法方案实现会让用户更易达成共识,从而避免异构算法带来的不互通问题。
自2018年以来,国内众多企业加入开源生态建设,当前共有十余个隐私计算开源项目,涵盖多方安全计算、联邦学习、可信执行环境技术路线,项目类别丰富,以产品平台为主,突出平台易用性和功能完备性,也有协议算子库,包含可实现不同安全要求的协议或算法,极大降低算法开发成本,同时也有针对应用的解决方案类开源项目,众多开源项目为产学研各方提供丰富选择。
在2023年,一些开源项目均周期发布新版本,不断增强平台功能,提高平台易用性,在好用易用的同时又极大降低了隐私计算行业进入门槛。同时,多个开源社区围绕项目开展丰富的活动,包括线下会议、大赛、社区建设等,广泛的社区协作与活动有效链接了多方机构,形成开源共建力量,持续为隐私计算发展注入活力。

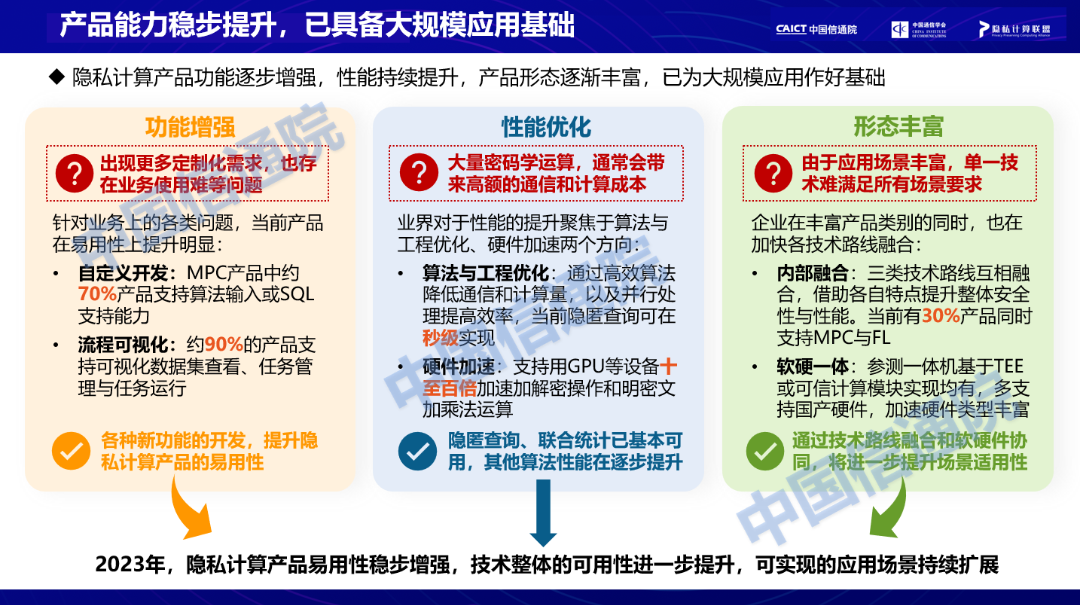
观点三:产品能力稳步提升,已具备大规模应用基础
由于隐私计算落地应用增多,在应用中出现如业务使用难、算法耗时长等问题,部分企业开始加大对产品易用性的支持能力,并通过技术融合和软硬结合手段提高整体安全性与性能。
产品功能方面,通过自定义开发和拖拉拽等可视化功能,降低了业务人员学习成本,简化了操作流程。根据测试数据统计,约7成左右产品具备算法输入和SQL能力,方便用户进行自定义开发;9成产品具备可视化数据集查看、任务管理等可视化操作能力,产品易用性较高。
性能方面,通过算法优化、工程优化、硬件加速等方式来加速计算效率。当下,较高安全强度的隐匿查询可在秒级实现。此外,市面上已经不少家厂商推出了一体机产品,可加速加解密和明密文加乘法运算操作,计算效率可提升数十到数百倍。
产品形态方面,通过三类技术互相融合,可借助各自特点提升整体安全性或性能,根据测试数据统计,当前约有30%产品同时支持多方安全计算和联邦学习。我们也观察到最近一年一体机的研发热度不减,不少一体机产品是基于TEE实现,也有一些基于可信计算模块实现,并且其中大多都支持国产硬件,加速硬件的类型也丰富。
2023年,隐私计算产品能力不断成熟,但在应用侧仍然面临合规性困局、性能瓶颈、互联互通难等问题;同样在2023年,大模型和AIGC蓬勃兴起,掀起新浪潮。针对AIGC兴起和当前隐私计算面临挑战,我们带来如下思考与观察。
观点四:AIGC带来数据流通新模式
由于AIGC需要海量数据训练和强大的通用能力,我们认为有可能会变革数据流通模式。对于AIGC,通过数据流通,可以提高通用大模型以及领域模型的语义理解、推理和专业能力,大模型在短期内对数据流通的需求将提高,所以有观点认为,未来数据流通模式会从之前的数据供方直接给到数据需方,变成数据供方将数据发给大模型进行训练,训练好的大模型私有化部署到数据需方。同时,可能随着大模型能力逐步增强,在部分实时性和准确性要求不高的场景中大模型将减少对数据流通的依赖。当前AIGC与大模型在快速发展,我们也将持续关注他们与数据流通的相互影响。

观点五:大模型带来隐私计算发展新机遇
对隐私计算而言,隐私计算在大模型构建的过程中也可以起到一定作用,主要是满足在训练阶段的数据安全和性能的需求,以及预测阶段的隐私保护的需求。在模型微调训练阶段,通过联邦学习实现数据不出域的多方联合训练,以及通过TEE结合硬件加速方式,汇聚多方数据进行安全高效的大模型训练,我们发现已经有一些企业发布隐私保护大模型的产品和训练工具。在保护隐私方面,对于大模型本身的云上部署方式,由于使用方自身的数据可能包含隐私信息,同时用户也担心其连续的输入数据被服务端记录并用于后续推理或训练,造成隐私信息泄露。而服务方通过TEE部署的方式,可以解决大家普遍关心的大模型泄露隐私的问题,目前也有厂商在做最新的探索实践。

观点六:尝试技术手段度量“匿名化程度”推进合规性验证
在我国,《个人信息保护法》对匿名化的定义是“个人信息经过处理无法识别特定自然人且不能复原的过程。在某些隐私计算场景下,其计算结果本身包含标识符,导致隐私计算技术对个人信息的处理并不能满足“无法识别”的要求。当前,通过匿名化实现数据安全流通的路径仍不清晰,需要综合考虑数据分类分级、流通环境限制条件,根据特定范围来划分相对匿名化要求,隐私计算联盟和信通院云大所尝试从各种角度去解决和推进用技术手段度量匿名化程度,推进合规性的验证。我们已经在部委的指导下开始相关的工作,如通过攻防的方式验证匿名化程度,当前在技术研究方面已经有了理论支撑,正在逐步完善标准规范和有效评价。

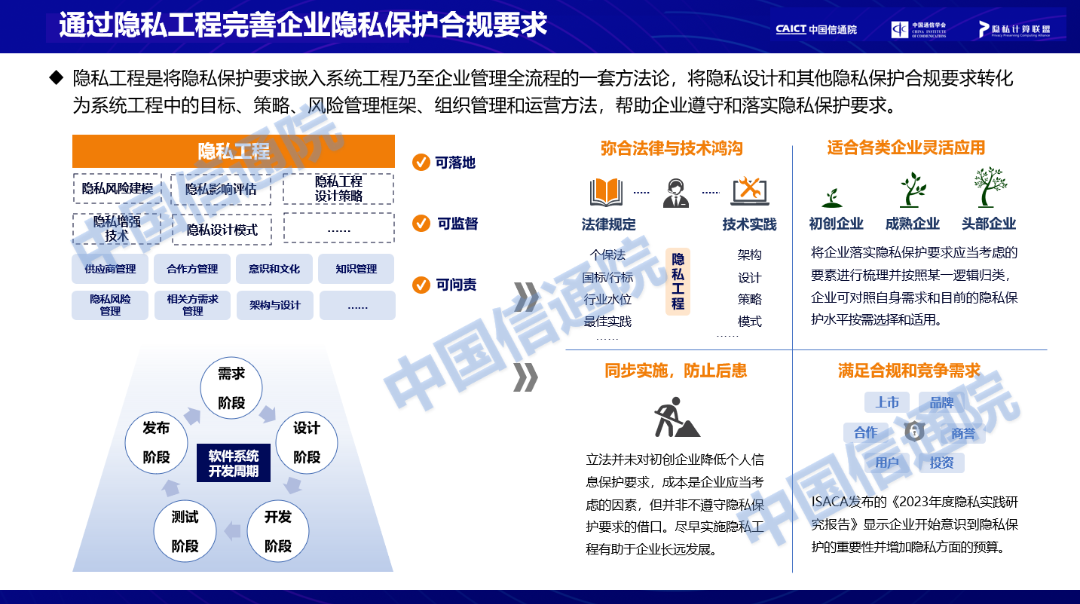
观点七:通过隐私工程完善企业隐私保护合规要求
通过隐私工程来完善企业隐私保护合规要求,就是把隐私计算技术真正嵌入到业务中,尤其在业务刚成型时就考虑整体的隐私保护。隐私工程来源于隐私设计,是20世纪90年代提出的一种保护隐私的理念,认为隐私不能仅靠遵守法规监管框架来保证。相反,保障隐私安全在理想情况下应当成为一种默认操作模式。隐私设计理念提出将隐私增强技术的应用扩展为一套完整的隐私设计框架,旨在注重个人信息的保护,是一套用在企业全生命周期的完整方法论,并且可以把技术语言翻译成系统工程里的目标策略,包括风险管理的框架、组织管理和运营方法,帮助企业遵守和落实隐私保护的要求。信通院云大所今年下半年也会发布隐私工程的报告,其中包括如华为、蚂蚁、阿里、腾讯等很多厂商的实践,他们已经运用该理念并在不断弥合法律和技术的鸿沟。
观点八:多技术融合助力突破应用瓶颈
隐私计算各路线有着其独特的优势与不足,这些不足阻碍了隐私计算的落地应用。多方安全计算(MPC)具有较高的安全性,但是由于通信与计算开销大,导致其计算效率差;联邦学习(FL)通过各方数据不出域,仅交互中间参数的方式来实现联合建模,相比基于MPC方式的联合建模有着较高的性能,但联邦学习对中间参数的保护能力有待提升;可信执行环境(TEE)结合了密码技术与可信硬件,能够在不过多损失性能的前提下,通过可信认证、一致性核验、密文传输、计算隔绝等手段保护数据隐私。但是,若攻击者通过如侧信道攻击等方式破环了可信硬件的安全性,将会导致明文数据泄露。
通过技术融合可实现整体安全性或性能的提升。MPC与FL融合,以实现更加安全的联邦学习聚合算法,如通过秘密分享或全同态加密等方式在密态的环境下完成模型参数聚合;TEE与FL融合,借助TEE的可信性和隔绝性实现模型参数的安全汇聚,增强FL的安全性;MPC与TEE融合,通过MPC将明文数据转为密态或分片数据,可防止因TEE被破坏而导致泄露原始数据;借助TEE的隔绝性、保密性等能力,可将跨网的MPC计算节点安全的放置在同一网络内,提高MPC性能。

观点九:公共数据授权运营为隐私计算提供新场景
2022年12月“数据二十条”发布,提出要建立公共数据确权授权机制,为此前公共数据开发利用中存在争议的数据“所有权”问题提供了一种合理解决思路。公共数据授权运营涉及的公共数据本身也是高价值、高敏感数据,通过数据确权授权,公共数据要素将具备更明确的流通范式。在“数据二十条“指导下,我们看到各地方今年不断开展公共数据授权运营的实践和发布运营管理办法,一些行业主管部门也开展了行业级的授权运营探索,形成了电子社保卡、司法大数据服务网等产品及服务。
安全合规的运营平台是高价值公共数据通过授权运营实现价值释放的首要发力点,而隐私计算必将成为公共数据运营平台关键的技术模块,通过隐私计算将会全方位助力公共数据授权运营安全有序开展,促进公共数据与社会数据融合。当前我们在做的技术标准和相关实践工作,发现隐私计算在公共数据授权运营中扮演着重要作用,在今年7月份的“2023全球数字经济大会”上我们成立了公共数据运营工作组,将继续与大家共同探讨公共数据授权运营标准体系和后续工作。

观点十:通过互联互通助推构建广泛生态圈
隐私计算互联互通参与方包括数据提供方,技术提供方和业务需求方,通过标准体系建设、试点推广和适配验证的实施路径,有利于吸纳更多成员参与,从而形成良好的互联互通生态圈,助力数据要素可信流通。
标准体系方面,中国信通院云大所牵头的隐私计算联盟、全国信息安全标准化技术委员会(TC260)、北京金融科技产业联盟、IEEE等在内的标准化组织都在推进相关技术标准的研讨和编写;另外,在今年上半年隐私计算联盟也完成了《隐私计算 跨平台互联互通》系列标准,在标准层面凝结多方共识。
示范实践方面,由于仅靠标准层面的、原则性的框架要求很难指导实践落地,所以需要打造具有标杆性、可复制、可验证的实践案例。在2022年,隐私计算联盟开始探索行业试点,征集试点项目,通过制定开放算法协议助力互联互通生态建设,我们看到当前已有ECDH-PSI,SS-LR等开放协议以及算法调度互联等十余个实践示范。
生态建设方面,随着标准体系建设完善和实践示范逐步建立,隐私计算联盟将继续发挥资源优势,吸引更多数据资源和业务场景,通过适配验证和方案推广结合的方式,助推解决“数据群岛”问题,从而有望实现隐私计算规模化应用。

声明:本文来自CAICT数据要素,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
