基于深度学习和半监督学习的webshell检测方法
吴斌,赵力
(北京网思科平科技有限公司,北京 100089)
摘要:半监督学习是一种重要的机器学习方法,能同时使用有标记样本和无标记样本进行学习。在webshell检测领域,有标记样本少、形式灵活多变、易混淆,基于特征匹配的方式很难进行准确检测。针对标记样本较少的现状,提出一种基于深度学习和半监督学习的webshell检测方法,先使用卡方检验和深度学习方法获取样本的文本向量,然后分别使用单分类和增量学习方式训练,提高分类性能。使用github公开数据集进行训练和测试,实验结果验证该方法能够有效改善webshell检测的漏报率和误报率。
关键词:深度学习;半监督学习;webshell检测;单分类;增量学习
中图分类号:TP399 文献标识码:A DOI: 10.19358/j.issn.2096-5133.2018.08.005
引用格式:吴斌,赵力.基于深度学习和半监督学习的webshell检测方法[J].信息技术与网络安全,2018,37(8):19-22.
Webshell detection method based on deep learning and semi-supervised learning
Wu Bin,Zhao Li
(Beijing Onescorpion Technology Co.,Ltd.,Beijing 100089,China)
Abstract:Semi-supervised learning is an important machine learning method,which can use both labeled and unlabeled samples for learning.In the field of webshell detection,it is difficult to detect webshell accurately based on feature matching,because of few labeled samples,flexible forms and easy to be confused.A webshell detection method based on deep learning and semi-supervised learning is proposed in this paper,which firstly uses chi-square test and deep learning method to obtain the document vector of samples,and then uses one-class classification and incremental learning method respectively to improve classification performance.The open source data set in github is used for training and testing,and the experimental results show that this method could improve the rate of flase negative and false positive of webshell detection effectively.
Key words: deep learning;semi-supervised learning;webshell detection;one-class classification;incremental learning
0 引言
随着互联网的发展,基于B/S架构的Web应用迅速普及,包括应用在政府、银行、运营商、电商以及各大门户网站。由于不同的Web系统研发人员水平差异,在设计过程中难免对安全问题欠缺考虑,造成Web安全问题频发。常见的安全威胁有:SQL注入漏洞、上传文件漏洞、提交表单漏洞、跨站脚本攻击等。入侵者在获得Web系统漏洞后,会通过上传webshell来获得Web服务器的操作权限。对于入侵者来说,webshell就是一个后门程序,通常是ASP、PHP、JSP等网页脚本。入侵实施后,首先在网页服务器的Web目录下面放置脚本文件,然后可以通过Web页面对网站服务器进行控制[2]。由于webshell操作不会在系统安全日志中留下记录,并且与正常网页文件混在一起,一般管理员很难看出入侵痕迹[3]。
在Web安全检测领域,由于缺少样本,很难建立精准的监督学习模型,而无监督学习会造成误报率高的问题,需要大量的安全工程师分析过滤机器学习的警告,分析结果存在人工误差。由于Web攻击方式多变,传统的预测方式难以应对复杂的真实环境。本文利用深度学习提取特征完备性高的特点,结合半监督学习,将机器学习应用于webshell本地检测,使用github公开样本数据[4-5],采用单分类和增量学习方式,不断优化模型,经过多次试验效果证明,本文方法能够有效降低误报率和提高检测率。
1 深度学习
在机器学习领域,学者公认“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。本文webshell检测的测试数据来源于github上整理的webshell样本,具有一定的代表性。特征选择使用卡方检验和神经网络相结合,先用卡方检验选取前K个重要特征,过滤测试文本,进一步使用神经网络算法,获得每一个样本的文本向量。
1.1 卡方检验
卡方检验是一种常见的特征选择方法。其基本思想是根据样本数据推断总体的分布与期望分布是否有显著差异,或者推断两个分类变量是否相关。
一般可以设原假设为H0:观察频数与期望频数没有差异,或者两个变量相互独立不相关。实际应用中,先假设H0成立,计算出χ2值。根据χ2分布、χ2统计量以及自由度,可以确定在H0成立的情况下获得当前统计量的概率P。如果P很小,说明观察值与理论值的偏离程度大,应该拒绝原假设。否则不能拒绝原假设。
χ2的计算公式为:
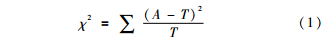
其中,A为实际值,T为理论值。
在本文的github样本中,使用卡方检验剔除与webshell攻击相关性较小的词,例如:“is”、“the”、“是”等。选取前500个特征词,例如“shell”、“package”等。
1.2 神经网络
深度学习是机器学习的重要分支,目前深度学习在图像、语音、自然语言等取得巨大突破。在文本分析领域,word2vec[6]和doc2vec是深度学习的重要研究成果,doc2vec与word2vec相似,只是word2vec在基于词的语义分析基础上,添加基于上下文的语义分析能力。
doc2vec是将词表征为实数值向量的一种高效的算法模型,利用深度学习的思想,构建两层神经网络,即输入层-隐藏层-输出层,通过训练,把对文本内容的处理简化为K维向量空间中的向量运算。其训练和预测过程如图1所示。
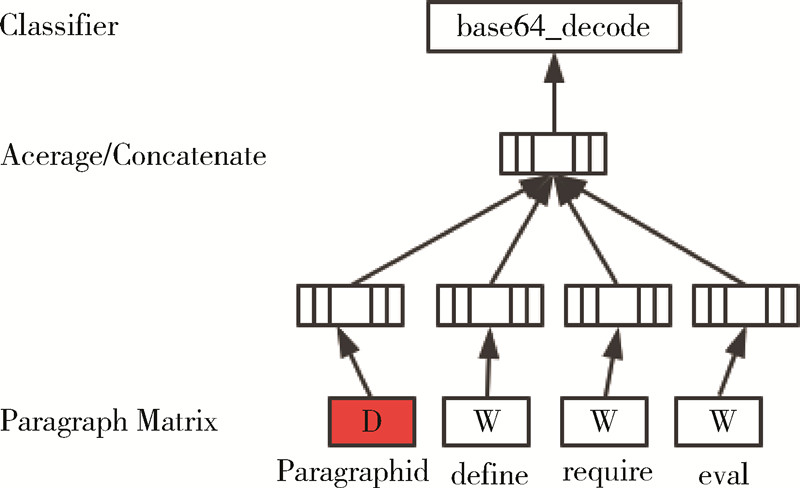
图 1 文档向量学习框架图
在本文的测试样本中,经过卡方检验筛选之后,运用doc2vec模型,训练得到样本的文本向量:[-2.083 977 50×10-2,-4.902 341 22×10-2,-2.033 572 83×10-2,-7.650 934 16×10-2,…]。
2 半监督学习
传统的机器学习通常分为有监督学习和无监督学习。有监督学习是通过训练标记的样本,尽可能正确地对训练之外的未标记样本进行预测;无监督学习是通过训练无标记的样本,以发现未标记样本之间的内部特征。半监督学习是介于有监督学习和无监督学习之间的机器学习方式,同时运用标记样本和无标记样本,训练机器学习模型。
在实际应用中,有标记的webshell样本数量极少,人为手动标记代价大,少量有标记的webshell样本极其珍贵,而样本中未标记的样本大量存在。本文的webshell检测模型,由于正常样本数量相对于webshell样本数量占绝对优势,因此首先把未标记的样本全部当作正常样本,使用无监督方式训练单分类SVDD模型;再运用有标记的样本,修正单分类SVDD模型,达到增量学习的目的。
本文充分运用现有少量有标记的webshell和大量无标记的样本数据,使用半监督学习,利用先验单分类SVDD模型信息和新的标记样本更新模型,一方面能够继承先前学习到的知识,让整个学习具有可积累性;另一方面可以实现在线学习,不断更新webshell检测模型。
2.1 单分类SVDD模型
支持向量数据描述(Support Vector Domain Description,SVDD)是由TAX D M J和DUIN R PW[7]提出并发展起来的一种单值分类算法,标准的SVDD模型属于无监督学习,把要描述的对象作为一个整体,建立一个封闭而紧凑的超球体,使得描述对象全部或尽可能多地包在这个球体内。
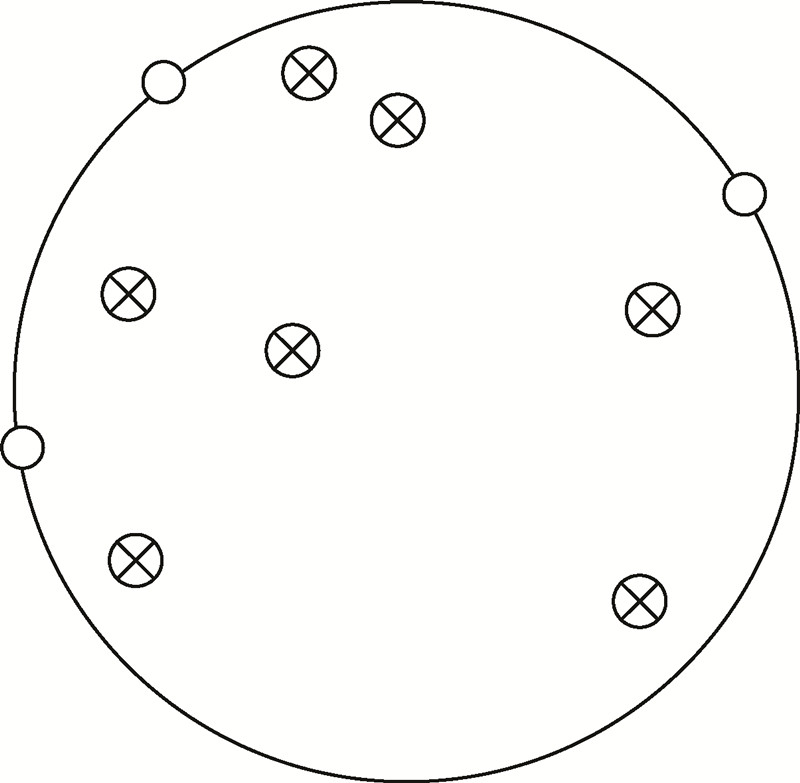
图 2 单分类SVDD模型图
假设训练数据集为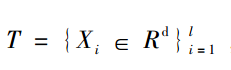 SVDD的优化目标是在T中,找到最小半径R。最优超球体的求解可以转化为以下优化问题:
SVDD的优化目标是在T中,找到最小半径R。最优超球体的求解可以转化为以下优化问题:
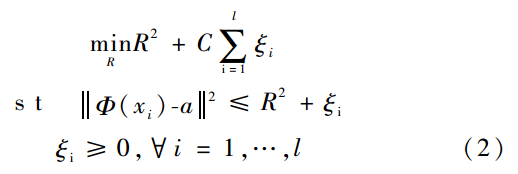
其中,R为待求的球的最小半径,C为惩罚系数,ξi为惩罚项,a为超球体的球心。
训练结束后,需要判断新的数据点Z是否属于这个类,即:
(z-a)T(z-a)≤R2 (3)
至此已经用未标记样本训练了单分类SVDD模型,对于测试数据可以用该模型直接进行判断。但是未标记样本中存在少量的webshell攻击样本,直接使用单分类SVDD模型存在一定误差。接下来使用标记样本,通过有监督学习方式增量训练SVDD模型,修正已经训练好的单分类SVDD模型。
2.2 增量学习SVDD模型
webshell攻击方式多变,脚本更新速度快,攻击的特征也不是一成不变的。使用当前的webshell样本训练单分类SVDD模型,难以适应webshell入侵方式不断更新的现状。而增量学习是一种在线学习方式,指的是一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识。准确地说,增量学习并不是一种模型,而是一种模型的训练更新方式。
本文提出的增量学习SVDD模型,在单分类SVDD模型的基础上,运用有标记的样本,更新单分类SVDD模型,达到增量学习的目的。在这个过程中,以前处理过的大部分样本不需要重复处理,只选取作为支持向量的样本,结合新的有标记的样本,重新学习并更新SVDD模型,一旦学习完成之后,训练的样本被丢弃。学习系统没有关于整个训练样本的先验知识。
3 基于深度学习和半监督学习的webshell检测算法
3.1 webshell检测算法流程
基于深度学习和半监督学习的webshell检测算法主要包含卡方检验、深度学习、半监督学习、单分类SVDD、增量学习SVDD等。其中算法结构如图3所示。
3.2 webshell检测算法描述
本文运用深度学习和半监督学习相关算法,对于有标记样本集{(X1,Y1),(X2,Y2),…,(Xn,Yn)},其中Yi=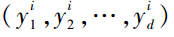 为对应样本Xi=
为对应样本Xi=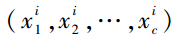 的标记向量,以及无标记样本{Z1,Z2,Z3,…,Zm}进行webshell建模分析。其中webshell检测算法具体流程如下:
的标记向量,以及无标记样本{Z1,Z2,Z3,…,Zm}进行webshell建模分析。其中webshell检测算法具体流程如下:
(1)对有标记样本进行分词处理,再用卡方检验分析各个特征词与样本标记之间的相关性,选择前K个重要特征词作为筛选特征词;
(2)对于未标记样本,用(1)中获取的筛选特征词获得未标记样本特征;
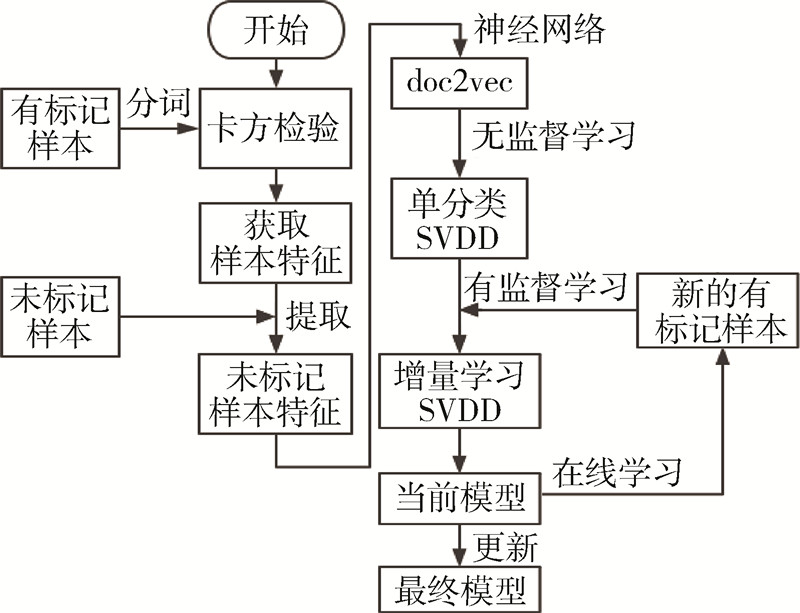
图 3 webshell检测算法流程图
(3)对于(2)中获取的未标记样本特征,使用神经网络训练获得各个未标记样本的文本向量及doc2vec;
(4)利用(3)中获取的文本向量,使用无监督学习方法训练单分类SVDD模型,最小化超球体半径,最大情况包含未标记样本;
(5)对于新的标记样本,运用在线学习方式训练增量学习SVDD模型,修正单分类SVDD模型,提高现有模型的识别能力。
4 实验与分析
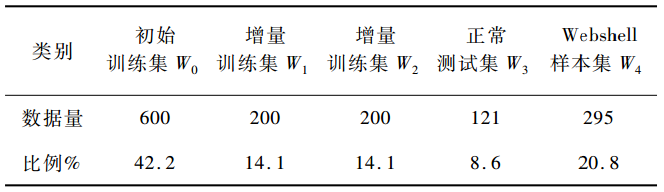
为了验证本文中基于深度学习和半监督学习的webshell算法检测性能,使用github中数据进行实验,数据样本分布情况如下表1所示。
表1数据的类别分布表
4.1 数据预处理
原始的webshell训练样本是直接在github上下载的webshell脚本文件,在进行样本训练之前,需要进行数据预处理。为了获得高质量的特征集,在所有的数据集合中选取有标记样本作为卡方训练样本,其中选取增量训练集W1中50份样本,增量训练集W2中50份样本,正常测试集W3中50份样本,webshell样本集W4中50份样本,组合成200份有标记卡方训练样本。
经过卡方检验之后,选取前500个特征作为样本的重要特征,其中前7个特征结果如表2所示。
表2前7个卡方检验特征表

通过卡方检验选择的特征是与标记样本相关性较高的特征词。为简化样本复杂程度,需要进一步使用卡方检验获取的前500个特征值,过滤初始训练集W0。然后使用神经网络训练过滤后的样本,获取训练样本的文本向量,即doc2vec。其中最终获得文本向量示例如下
X1=[-2.083 977 50×10-2,-4.902 341 22×10-2,-2.033 572 83×10-2,-7.650 934 16×10-2,…]
X2=[0.340 425 997 972,-0.016 084 445 640 4,
-0.757 030 189 037,0.497 053 474 188,…]
X3=[0.256 792 724 133,0.113 478 787 243,
-0.708 586 812 019,0.289 009 481 668,…]
4.2 实验结果和分析
在有少量有标记样本和大量无标记样本情况下,半监督学习是能够同时兼顾训练样本和提高训练结果的学习方法。在无监督学习阶段,本文使用初始训练集W0获得的文本向量训练单分类SVDD模型M0。在有监督学习阶段,首先在单分类SVDD模型M0的基础上,使用增量训练集W1训练增量SVDD模型M1;然后在增量SVDD模型M1的基础上,使用增量训练集W2训练增量SVDD模型M2。对于每个模型,均使用正常测试集W3和webshell样本集W4样本混合测试。对于本文的webshell检测方法,使用漏报率和误报率来验证模型分类效果,测试结果如表3所示。
表3测试结果表
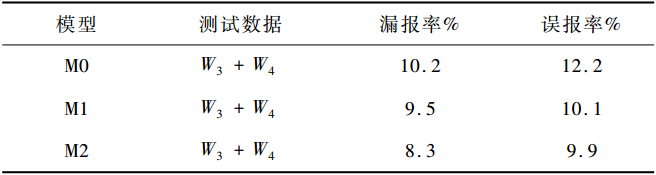
从实验结果可以看出,对于相同的W3+W4测试样本,使用增量SVDD训练的模型在漏报率和误报率上均优于单分类SVDD模型,并且使用增量样本修正的次数越多,模型的效果越好。说明基于深度学习和半监督学习方法在webshell检测中的优越性,充分利用少量有标记样本,使用在线学习方法训练增量SVDD模型,不断优化最终模型,降低检测的漏报率和误报率。
5 结论
经过多次的实验结果可知,本文提出的基于深度学习和半监督学习webshell检测方法,在webshell检测中一定程度上改善了系统的性能,有效降低了漏报率和误报率,并在增量学习框架下,通过不断学习新增标记样本,能够持续优化系统。在深度学习领域,本文使用文本向量的方式获得样本特征,此后的重点研究方向在于如何获取更有价值的样本特征。在半监督学习领域,本文使用单分类SVDD模型和增量SVDD模型,此后的重点研究方向在于如何优化模型提高漏报率和误报率。
参考文献
[1] QUINLAN J R.C4.5:programs for machine learning[M].San Francisco:Morgan Kaufmann,1993.
[2] 胡建康,徐震,马多贺,等.基于决策树的Webshell检测方法研究[J].网络新媒体技术.2012,1(6):15-19.
[3] 龙啸,方勇,黄诚,等.Webshell研究综述:检测与逃逸之间的博弈[J].网络空间安全,2018,9(1):62-68.
[4] https://github.com/tanjiti/webshellSample
[5] https://github.com/tennc/webshell
[6] MIKOLOV T, LE Q V, SUTSKEVER I.Exploiting similarities among languages for machine translation [J] arXiv, arXiv1309.4168,2013.
[7] TAX D M J, DUIN R P W.Support vector data description[J].Pattern Recognition Letters,1999,20(11-13):1191-1199.
(收稿日期:2018-07-10)
作者简介:
吴斌(1991-),通信作者,男,硕士,大数据分析师,主要研究方向:数据挖掘、机器学习。E-mail:wubin@onescorpion.com。
赵力(1990-),女,硕士,大数据分析师,主要研究方向:数据挖掘、机器学习。
声明:本文来自电子技术应用,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
