
原文标题:When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan
原文作者:Yuqiang Sun, Daoyuan Wu, Yue Xue, Han Liu, Haijun Wang, Zhengzi Xu, Xiaofei Xie, Yang Liu发表状态:preprint原文链接:https://arxiv.org/abs/2308.03314主题类型:Sec-LLMs笔记作者:IzaiahSun主编:黄诚@安全学术圈
研究背景
智能合约的漏洞类型与传统软件不同,并不存在内存安全或者任意代码执行等问题。而根据已有研究,智能合约中约80%的漏洞是无法使用机器检测的(Machine Undetectable Bugs)。这些漏洞大多与业务逻辑相关,而传统的分析方法并不考虑业务逻辑,因此无法检测出这些漏洞。
漏洞案例

在上述案例中,实现了一个存款(deposit)的操作。当流动性池的余额为0时,share会被设置成存款总数。因此,第一个存款人可以存入很少的钱并占据所有的share,之后转入一大笔使share价格通胀,从而获取不正当利益。对于静态分析的检测方法来说,难点在于如何判断业务场景并识别出关键变量。
研究方法

这篇文章的方法分为三个步骤:
基于静态分析的函数筛选。
基于GPT模型的场景分析与关键信息提取。
基于静态分析的漏洞确认。
函数筛选
首先,作者使用了静态分析的方法,要求所有被分析的函数都是用户可达的,即存在一条调用路径,并且没有onlyOwner等权限修饰符。其次,作者使用了若干个基于文本和调用图的过滤规则,用于筛选每一条规则对应的潜在漏洞函数。对于每个漏洞函数,作者根据调用链关系,对其和其上下文函数进行组合,以确保语义完整性。经过了过滤和组合之后,一定程度上降低了候选项范围,并保证了一定的语义完整性。
场景分析与关键信息提取


作者使用了GPT-3.5-turbo模型,对于每个候选项,包括了两条自然语言描述,分别为scenario和property。针对每一个候选函数,模型会依次确认scenario和property是否匹配,如果匹配则认为该函数有较大概率存在漏洞,并进入到下一步。当认为函数有较大概率存在漏洞时,模型会进一步提取关键信息,包括vulnerable variable和vulnerable statement。这两项信息会交给最后一步,漏洞确认,用于确认漏洞是否存在。
漏洞确认
漏洞确认采用了静态分析的方法,一共有四个内置分析器。包括了静态数据流追踪,变量比较检查,执行顺序检查和函数调用参数检查。这些分析器可以有效去除误报,以提升准确率和精确度。
规则汇总
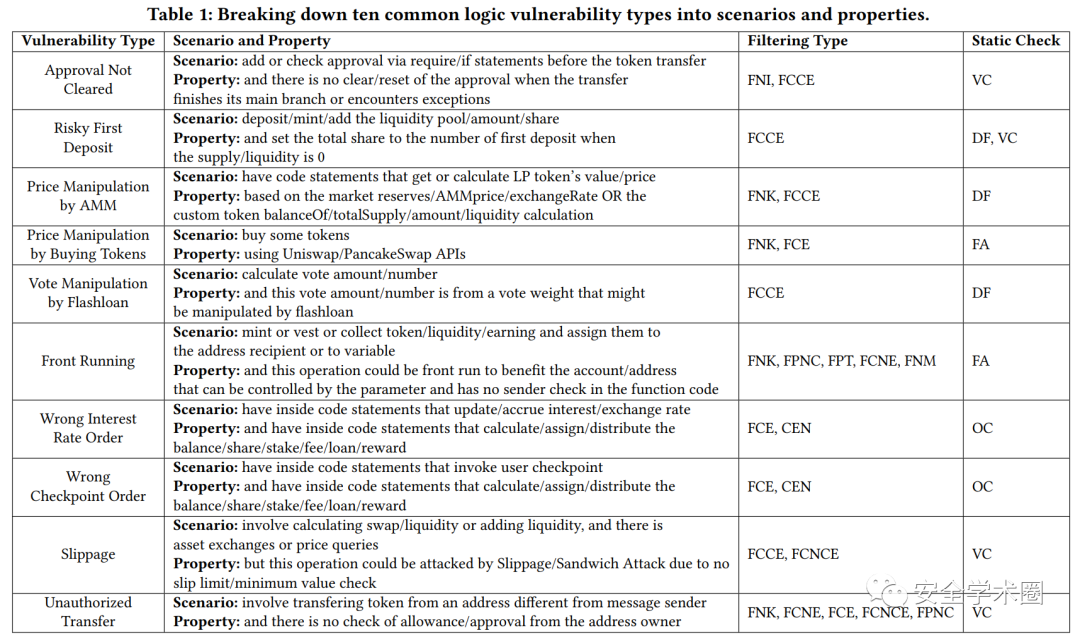
作者一共总结了10条规则,共对应了9个漏洞类型,包括授权未被清除、不安全的第一个存款人(案例中展示的漏洞)、基于AMM的价格操纵、基于购买或交换代币的价格操纵、投票操纵、抢跑、错误执行顺序、滑点和未经授权的转账。每一条规则包含四个部分,即两条自然语言描述,一些静态过滤器和一条静态确认器。
实验
数据集
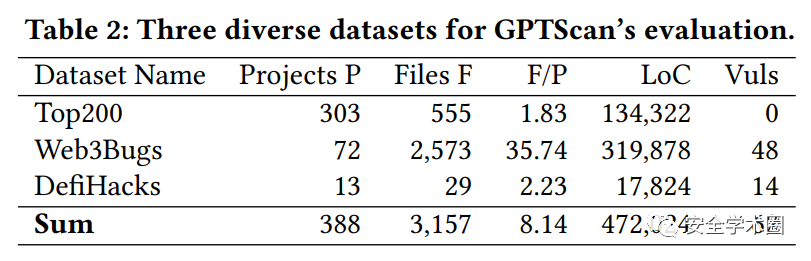
该论文共使用了三个数据集,分别是:
Top200,选择了市场份额前200的合约,这些合约被认为是安全的、经过市场检验的。
Web3Bugs,来源于https://github.com/ZhangZhuoSJTU/Web3Bugs/,为ICSE2023的论文的公开数据集,包括72个可编译的项目。
DefiHacks,共13个真实发生的攻击案例。
RQ1:误报问题
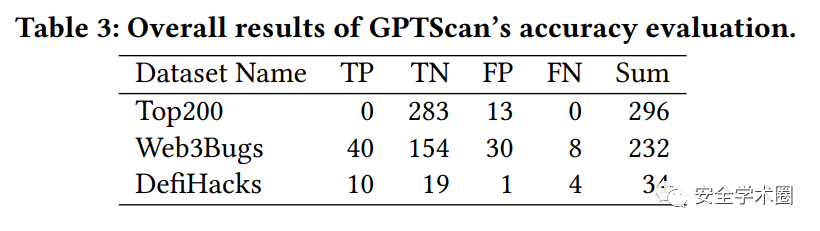
作者在三个数据集上进行了实验,结果如上图所示。在Top200上,误报率为4.39%;在Web3Bugs上,精确度为57.14%;在DefiHacks上,精确度为90.91%。
RQ2: 检出率问题
作者在两个有漏洞的数据集上进行了实验:在Web3Bugs上,召回率为83.33%;在DefiHacks上,召回率为71.43%。作者在文中分析了所有漏报案例及其原因。
RQ3:静态漏洞确认有效性问题
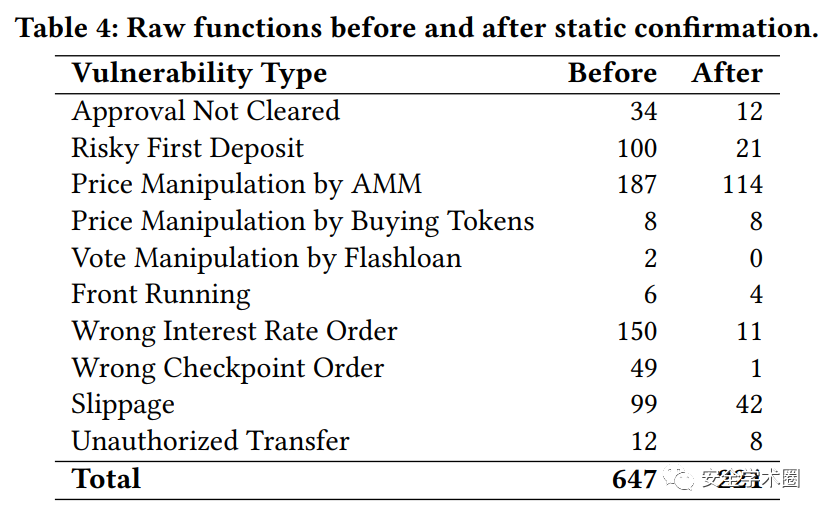
作者进行了一个消融实验(ablation study),对比了静态漏洞确认的重要性。实验发现,静态漏洞确认可以有效地去除误报,提升精确度。但同时,对于召回率影响非常有限。
RQ4:时间和经济开销
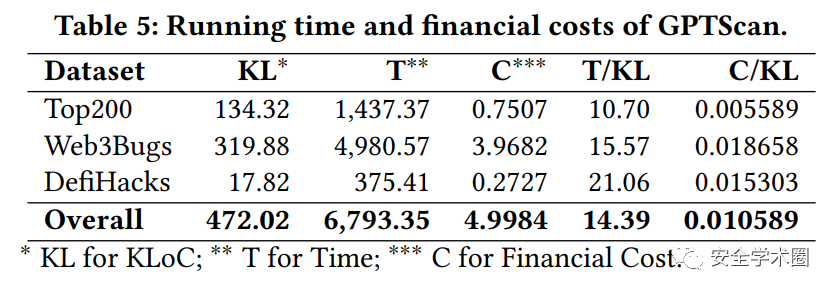
作者使用了GPT-3.5-turbo模型,在三个数据集共472K行代码上进行了实验。总耗时约6793秒,平均每千行代码耗时14.4秒;总共花费约5美元,平均每千行代码花费10.6美分(0.0010589美元)。相比于人工审计来说,AI辅助的漏洞检测可以大大降低成本。
RQ5:新发现的漏洞
作者在Web3Bugs数据集上发现了9个新的漏洞,其中5个是不安全的第一个存款人,3个是基于AMM的价格操纵,1个是抢跑。
讨论
可拓展性。若要拓展GPTScan,开发者仅需要完成两条自然语言描述,并使用现有静态分析过滤器和规则的组合即可,无需重新训练模型,难度较低。
局限性。目前过滤器部分,针对修饰符仅使用黑名单,不够准确,可以引入语义分析。
其它模型的适用性。目前仅使用了GPT-3.5-turbo模型,其它模型,如Google Bard,LLaMa等是否适用,需要进一步研究。
贡献总结
将项目进行切片以适应大语言模型的输入长度限制,降低尝试次数并保留一定的语义完整性。
使用自然语言描述漏洞来检测漏洞,而不需要重新训练模型。
结合静态分析和大语言模型,提升了漏洞检测的准确率和精确度。
论文文献
@misc{sun2023gpt,title={When GPT Meets Program Analysis: Towards Intelligent Detection of Smart Contract Logic Vulnerabilities in GPTScan},author={Yuqiang Sun and Daoyuan Wu and Yue Xue and Han Liu and Haijun Wang and Zhengzi Xu and Xiaofei Xie and Yang Liu},year={2023},eprint={2308.03314},archivePrefix={arXiv},primaryClass={cs.CR}}作者
Yuqiang Sun, 南洋理工大学博士生,研究兴趣漏洞检测,静态分析,软件工程。https://aboutme.izaiahsun.com。
Daoyuan Wu, 南洋理工大学高技研究员。
Yue Xue, MetaTrust 安全研究员。
Han Liu, 华东师范大学博士生。
Haijun Wang, 西安交通大学教授。
Zhengzi Xu, 南洋理工大学研究员。
Xiaofei Xie, 新加坡管理大学助理教授。
Yang Liu, 南洋理工大学教授。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
