
目前市场上最主流的大语言模型生成式人工智能技术,例如ChatGPT、Google Bard和基于LLAMA的开源大语言模型,在威胁检测/分类和预测领域的性能表现如何?
网络安全是人工智能最大的应用市场,而威胁检测/分类又是最热门的人工智能技术安全用例之一,生成式人工智能大语言模型能比人类安全分析师更快、更大量地识别和分析潜在安全威胁。那么,市场上主流的大语言模型在威胁检测/分类方面的性能表现如何呢?
近日,网络安全公司Skyhawk在开发一种能大大提高威胁识别准确性并自我改进的人工智能威胁分析框架时(该框架利用投票系统和置信度综合分析来自多个大模型的威胁信息检测结果,形成一个比单一大语言模型更加健壮可靠的安全分析集合学习框架),对主流大语言模型的威胁检测和预测能力进行了评测和研究。
威胁检测准确率GPT4不敌开源模型
Skyhawk的大语言模型基准测试方法如下:
参评模型:ChatGPT、GoogleBARD、基于LLAMA2的开源模型
测试内容:
任务:确定从云日志(例如AWS日志)中提取的聚合序列的恶意级别。
评估指标:使用精度、召回率和F1分数来衡量性能。
阈值:引入最佳阈值来决定分类结果。
排行榜:评估结果和排名可在Skyhawk网站上查看。
测试结果(下图)显示,GPT4的F1评分最高,但出人意料的是,GPT4的准确率不及开源的Llama-2-70B-LoRA-assemble-v2。而野心勃勃的的GoogleBard的准确率排名倒数第二,甚至与GPT3.5-turbo尚存在不小的差距:
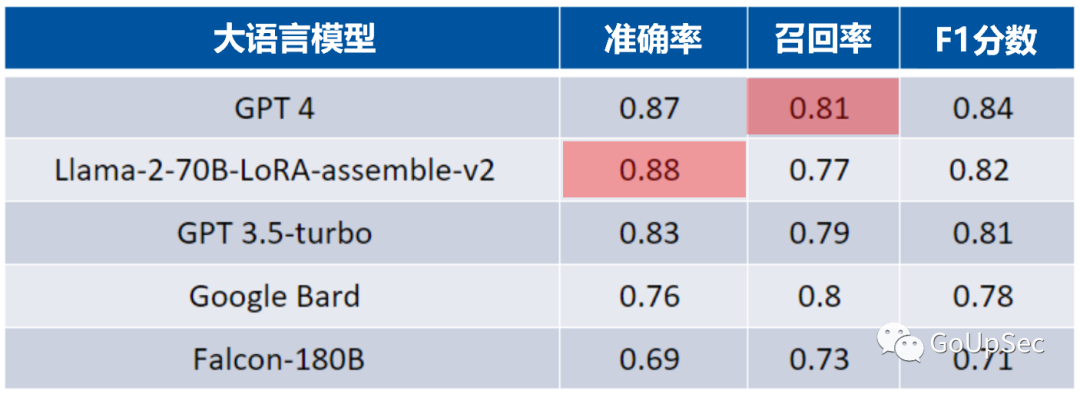
评测基于200个人类标记的代表性样本来源:Skyhawk
大语言模型威胁检测能力排名的意义
对主流大语言模型的威胁检测和分类进行基准测试是AI增强网络安全的基础工作。因为在开发由多个大语言模型组成的“联邦学习”或“集合学习”威胁分析框架时,研究者需要对每个主流大语言模型的威胁检测“天分”和潜力进行量化分析和排名,以此确定不同模型在威胁分类和评分流程中的权重,从而优化威胁分类流程,提高准确性和效率。
集成化多模型学习框架的优势
数字环境不断发展,云安全的复杂性不断增加。在这种动态环境中,查明和评估与云事件相关的风险变得越来越具有挑战性,尤其是当事件信息跨越恶意和良性评判的界限时,传统人工威胁检测和机器学习方法常常会出现问题,无法提供所需的检测精度和洞察力。
为了应对这一挑战,很多网络安全供应商选择使用大语言模型来充当高效的安全分析师,对每组事件信息的恶意程度进行评分,但这种方法需要多个大语言模型的“集成学习”(有别于联邦学习)来共同实现,利用投票系统和由结果差异确定的置信度来创建更强大的多模型安全分析集成学习框架(下图):
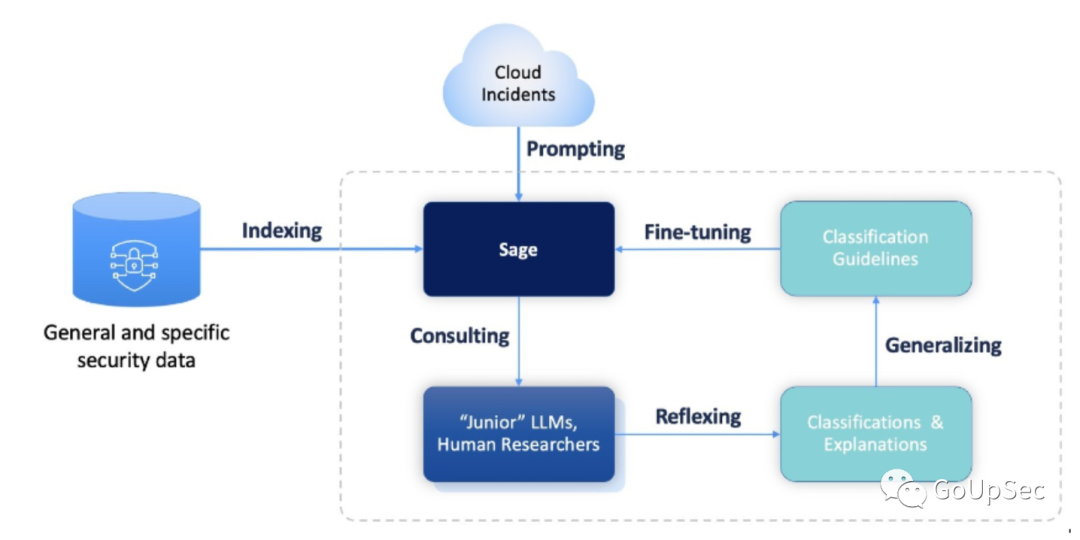
与Bagging和Boosting等现有MLEnsemble框架相比,这个新框架具有多项优势,包括:
改进的泛化能力:能够从“初级”模型的发现和错误中学习和适应,从而实现更好的预测准确性,特别是在复杂或嘈杂的数据集中。
模型可解释性:提供更精确、更易于理解的决策过程表示。
鲁棒性:增强对异常值和对抗性攻击的抵御能力,最大限度地减少过度拟合并增强数据质量管理。
效率:在处理大型数据集或资源受限的环境时可能提供计算优势。事实上,我们不需要单独运行每个模型(与堆叠和装袋相反)是一个优势。
灵活性:能够有效地整合各种“初级”模型以及人类驱动的见解,以满足不同的问题类型。
增量学习:根据随时间变化的数据分布促进持续适应和细化。
减少偏差:采用多方面的方法来减少预测偏差,确保结果更加平衡和公平。
研究者指出,集成学习多模型框架不仅优于单一大语言模型,而且还显著改进了基于平均值和方差评估的简单集成框架。
参考链接:
https://skyhawk.security/new-horizons-in-cloud-security-part-1/
声明:本文来自GoUpSec,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
