选自Medium,作者:Shaobo GUAN
机器之心编译,参与:王淑婷、路、张倩
基于描述生成逼真图像是一项比较困难的任务。本文介绍了一项新研究 Transparent Latent-space GAN (TL-GAN),它使用英伟达的 pg-GAN 模型,利用潜在空间中的特征轴,轻松完成图像合成和编辑任务。
使用 TL-GAN 模型进行受控人脸图像合成的示例。
教电脑根据描述生成照片
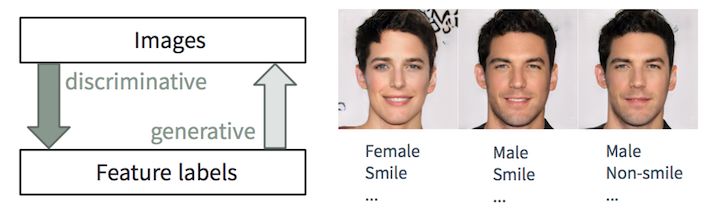
判别任务 VS 生成任务
描述一张图像对人类来说相当容易,我们在很小的时候就能做到。在机器学习中,这项任务是一个判别分类/回归问题,即从输入图像预测特征标签。随着最近 ML/AI 技术(尤其是深度学习模型)的进步,它们开始在这些任务中脱颖而出,有时会达到甚至超过人类的表现,如视觉目标识别(例如,从 AlexNet 到 ResNet 在 ImageNet 分类任务上的表现)和目标检测/分割(如从 RCNN 到 YOLO 在 COCO 数据集上的表现)等场景中展示的一样。
然而,另一方面,基于描述生成逼真图像却要困难得多,需要多年的平面设计训练。在机器学习中,这是一项生成任务,比判别任务难多了,因为生成模型必须基于更小的种子输入产出更丰富的信息(如具有某些细节和变化的完整图像)。
虽然创建此类应用程序困难重重,但生成模型(加一些控制)在很多方面非常有用:
内容创建:想象一下,广告公司可以自动生成具有吸引力的产品图像,而且该图像不仅与广告内容相匹配,而且与镶嵌这些图片的网页风格也相融合;时尚设计师可以通过让算法生成 20 种与「休闲、帆布、夏日、激情」字样有关的样鞋来汲取灵感;新游戏允许玩家基于简单描述生成逼真头像。
内容感知智能编辑:摄影师可以通过几次单击改变证件照的面部表情、皱纹数量和发型;好莱坞制片厂的艺术家可以将镜头里多云的夜晚转换成阳光灿烂的早晨,而且阳光从屏幕的左侧照射进来。
数据增强:自动驾驶汽车公司可以通过合成特定类型事故现场的逼真视频来增强训练数据集;信用卡公司可以合成数据集中代表性不足的特定类型欺诈数据,以改进欺诈检测系统。
在本文中,我们将描述我们最近的研究,称为 Transparent Latent-space GAN (TL-GAN),它扩展了当前的前沿模型,提供了一个新的界面。我们正在写关于这项研究的论文,里面将包含更多技术细节。
生成模型概览
深度学习社区在生成模型方面进展迅猛。其中有三种比较有前景的模型:自回归模型,变分自编码器(VAE)和生成对抗网络(GAN),如下图所示。如果你想了解详情,可以查看这篇 OpenAI 博客:
https://blog.openai.com/generative-models/。
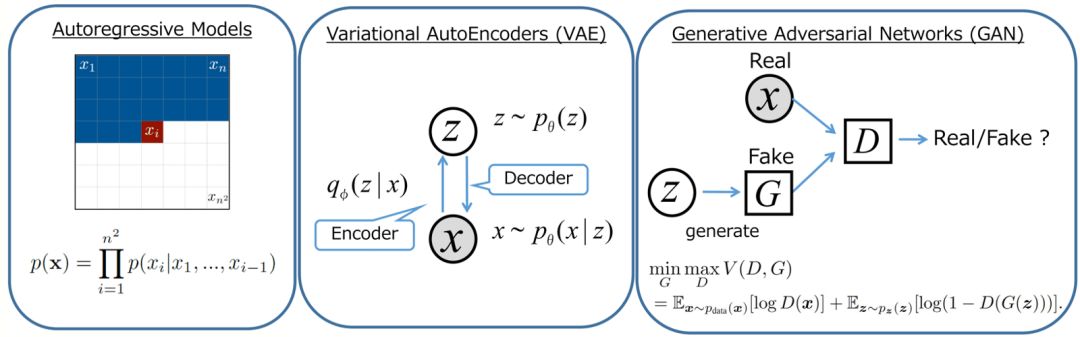
生成器网络对比。图源:https://wiki.math.uwaterloo.ca/statwiki/index.php?title=STAT946F17/Conditional_Image_Generation_with_PixelCNN_Decoders

英伟达的 pg-GAN 生成的合成图像。以上没有一个是真实图像!
控制 GAN 模型的输出

随机图像生成 VS 受控图像生成
GAN 的原始版本和很多流行的模型(如 DC-GAN 和 pg-GAN)都是无监督学习模型。训练后,生成器网络将随机噪声作为输入,并生成几乎无法与训练数据集区分开来的逼真图像。然而,我们无法进一步控制生成图像的特征。但在大部分应用程序(如第一部分中描述的场景)中,用户希望生成带有自定义特征(如年龄、发色、面部表情等)的样本,而且理想情况是能够不断调整每个特征。
为了实现可控合成,人们已经创建了很多 GAN 的变体。它们大致可分类两类:风格迁移网络和条件生成器。
风格迁移网络
风格迁移,以 CycleGAN 和 pix2pix 为代表,是用来将图像从一个领域迁移到另一领域(例如,从马到斑马,从素描到彩色图像)的模型。因此,我们不能在两个离散状态之间连续调整一个特征(例如,在脸上添加更多胡须)。另外,一个网络专用于一种类型的迁移,因此调整 10 个特征需要十个不同的神经网络。
条件生成器
条件生成器以 conditional GAN,AC-GAN 和 Stack-GAN 为代表,是在训练期间联合学习带有特征标签的图像的模型,使得图像生成能够以自定义特征为条件。因此,如果你想在生成过程中添加新的可调特征,你就得重新训练整个 GAN 模型,而这将耗费大量的计算资源和时间(例如,在带有完美超参数的单一 K80 GPU 上需要几天甚至几个星期)。此外,你要用包含所有自定义特征标签的单个数据集来执行训练,而不是利用来自多个数据集的不同标签。
我们的 Transparent Latent-space GAN 模型,通过从新的角度处理受控生成任务,解决了现有方法存在的这些问题。它允许用户使用单个网络逐渐调整单个或多个特征。除此之外,添加新的可调特征可以在一个小时之内非常高效地完成。
TL-GAN:一种新型高效的可控合成和编辑方法
让神秘的潜在空间变得透明
我们将利用英伟达的 pg-GAN,该模型可以生成高分辨率的逼真人脸图像,如前一节所示。一个分辨率为 1024x1024 的生成图像的所有特征仅由潜在空间(作为图像内容的低维表示)中 512 维噪声向量确定。因此,如果我们能够理解潜在空间代表什么(即,使其透明化),我们就能完全控制生成过程。
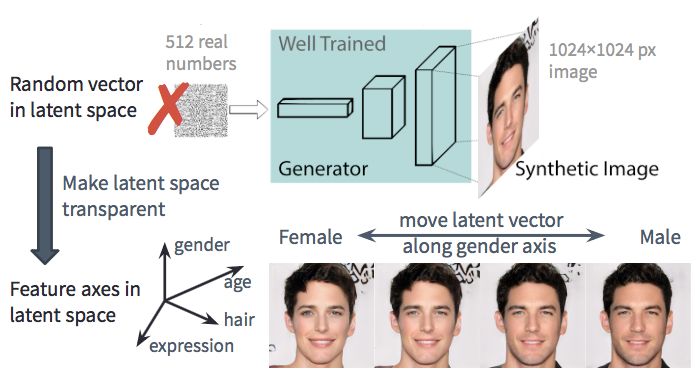
TL-GAN 的动机:理解潜在空间以控制生成过程
通过用预训练的 pg-GAN 进行实验,我发现潜在空间具有两个良好的特性:
它很稠密,这意味着空间汇总的大多数点能够生成合理的图像;
它相当连续,意味着潜在空间中两点之间的插值通常会导致相应图像的平滑过渡。
考虑到这两点,我觉得可以在潜在空间中找到能够预测我们关心的特征(如,女性-男性)的方向。如果是这样的话,我们可以把这些方向的单位向量用作控制生成过程(更男性化或更女性化)的特征轴。
方法:揭示特征轴
为了在潜在空间中找到这些特征轴,我们将通过在成对数据 (z,y) 上训练的监督学习方法构建潜在向量 z 与特征标签 y 之间的关系。现在问题变成了如何得到此类成对数据,因为现有数据集仅包含图像 x 及其对应特征标签 y。
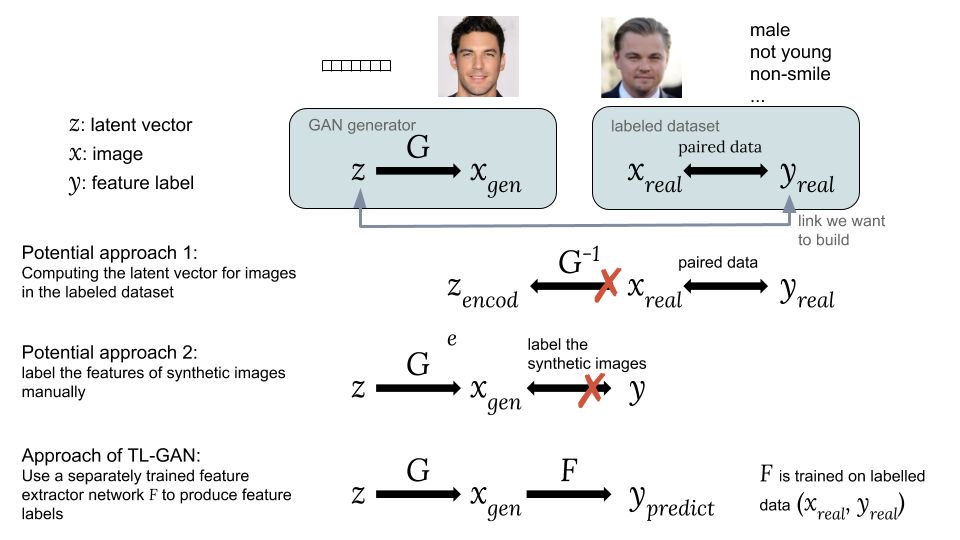
连接潜在向量 z 和特征标签 y 的方法。
可能的方法
一种可能方法是计算来自现有数据集的图像 x_real 的潜在向量 z,x_real 的标签是 y_real。但是,GAN 无法提供计算 z_encode=G^(−1)(x_real) 的简单方式,因此这个方法很难实现。
第二种可能方法是使用来自随机潜在向量 z 的 GAN 来生成合成图像 x_gen,即 x_gen=G(z)。问题在于合成图像没有标签,我们无法轻松地利用可用的标注数据集。
为了解决该问题,TL-GAN 模型做出了一项重要创新,即利用已有标注图像数据集 (x_real, y_real) 训练单独的特征提取器(用于离散标签的分类器或用于连续标签的回归器)模型 y=F(x),然后将训练好的 GAN 生成器 G 与特征提取器网络 F 结合起来。这样,我们就能利用训练好的特征提取器网络来预测合成图像 x_gen 的特征标签 y_pred,从而通过合成图像建立 z 和 y 之间的联系,即 x_gen=G(z) and y_pred=F(x_gen)。
现在我们有了成对的潜在向量和特征,可以序列回归器模型y=A(z) 来找出可用于控制图像生成过程的所有特征轴。
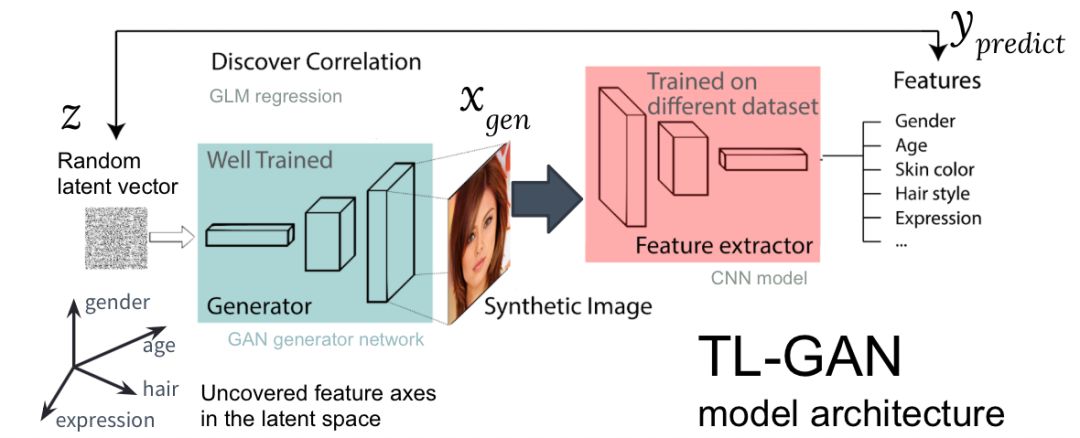
TL-GAN 模型架构
上图展示了 TL-GAN 模型的架构,共包括五步:
学习分布:选择一个训练好的 GAN 模型作为生成器网络。我选择的是训练好的 pg-GAN,它提供的人脸生成质量最好。
分类:选择一个预训练的特征提取器模型(可以是卷积神经网络,也可以是其它计算机视觉模型),或者利用标注数据集训练自己的特征提取器。我在 CelebA 数据集上训练了一个简单的 CNN,该数据集包含三万余张人脸图像,每个图像有 40 个标签。
生成:生成大量随机潜在向量,并传输到训练好的 GAN 生成器中以生产合成图像,然后使用训练好的特征提取器为每张图像生成特征。
关联:使用广义线性模型(Generalized Linear Model,GLM)执行潜在向量和特征之间的回归任务。回归斜率(regression slope)即特征轴。
探索:从一个潜在向量开始,沿着一或多个特征轴移动,并检测对生成图像的影响。
这个过程非常高效。只要具备一个预训练的 GAN 模型,在单 GPU 机器上识别特征轴仅需一小时。这是通过多个工程 trick 达成的,如迁移学习、下采样图像大小、预缓存合成图像等。
结果
沿着特征轴移动潜在向量
首先,测试发现的特征轴能否用于控制生成图像的对应特征。为此,我在 GAN 的潜在空间中生成了一个随机向量 z_0,然后将它传输到生成器网络 x_0=G(z_0) 以生成合成图像 x_0。接下来,我将潜在向量沿着特征轴 u(潜在空间中的单位向量,对应人脸的性别)移动距离 λ,到达新的位置 x_1=x_0+λu,并生成新的图像 x1=G(z1)。理想情况下,新图像的对应特征可以沿着期望方向进行修改。
下图展示了沿着多个示例特征轴(性别、年龄等)移动潜在空间向量的结果。效果非常棒!我们可以流畅地在男性 ←→ 女性、年轻 ←→ 年老之间变化图像。

沿着示例相关特征轴移动潜在向量的初始结果
解除相关特征轴之间的关联
上述示例也展示了该方法的缺点:相关特征轴。举例来说,当我打算减少胡须量时,生成的人脸图像更女性化,而这并非用户期望的结果。问题在于性别特征和胡须特征天然相关,修改一个必然会导致另一个也发生改变。类似的还有发际线和卷发。如下图所示,潜在空间中原始的「胡须」特征轴不垂直于性别特征轴。
为了解决这个问题,我使用直接的线性代数 trick。具体来说,我将胡须特征轴投影到新的方向,新方向垂直于性别特征轴,这就有效去除了二者之间的关联,从而解除生成人脸图像中这两个特征的关联。
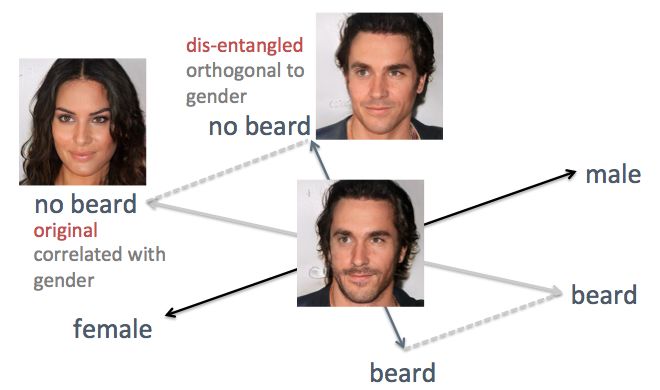
使用线性代数技巧解除相关特征轴之间的关联
我将该方法应用于相同的人脸图像示例中。这次我使用性别轴和年龄轴作为参考特征,将其它特征轴投影到与性别和年龄特征轴垂直的方向,然后检测潜在向量沿着新生成的特征轴移动时的生成图像(见下图)。如我们所料,发际线、卷发和胡须等特征没有改变人脸的性别。

灵活的交互式编辑
为了查看 TL-GAN 模型控制图像生成过程的灵活程度,我构建了一个交互式 GUI 来探索沿着不同特征轴调整特征值的效果。
视频:使用 TL-GAN 的人脸图像交互式编辑
我使用特征轴控制生成图像时,效果惊人的好!
总结
该项目提供了一种新方法来控制无监督生成模型(如 GAN)的生成过程。利用已经训练好的 GAN 生成器(英伟达的 pg-GAN),我通过发现其中有意义的特征轴使其潜在空间变得透明。当向量沿着潜在空间中的特征轴移动时,对应的图像特征发生变化,实现受控的合成和编辑。
该方法具备以下显著优势:
高效性:为生成器添加新的特征调整器(feature tuner)时,无需重新训练 GAN 模型。使用该方法添加 40 个特征调整器仅需不到一小时。
灵活性:你可以使用在任意数据集上训练的任意特征提取器来给训练好的 GAN 模型添加特征调整器。
伦理问题
这项研究允许我们对图像生成进行细粒度的控制,但它仍然严重依赖数据集的特征。基于好莱坞名人的照片进行训练意味着该模型擅长生成「好看」的人脸照片。这可能导致用户仅能够生成这种特定类型的人脸图像。如果将该模型部署为一个应用的话,我们希望能够增强原始数据集,以考虑用户的多样性。
此外,虽然该工具可能是一个巨大的创造性帮助,我们仍应该自问如果这个模型被用于邪恶目的呢。如果我们能够生成任意类型的逼真人脸图像,那么我们看到的还是真实的吗?这类问题很重要。我们看到了近期 deepfake 的出现与应用,AI 方法的能力正在快速增长,因此就如何最好地部署 AI 方法展开对话是非常重要的。
在线 demo 和代码
该研究的所有代码和 demo 均可在项目主页看到:https://github.com/SummitKwan/transparent_latent_gan
如果你想在 web 浏览器中尝试该模型
无需下载代码、模型或数据。只需按照 GitHub README 页面中的部分指令操作即可。(https://github.com/SummitKwan/transparent_latent_gan#1-instructions-on-the-online-demo)
如果你想尝试我的代码
按照 GitHub README 页面操作即可。代码是使用 Tensorflow、Keras 和 Anaconda Python 3.6 构建的。
原文链接:https://blog.insightdatascience.com/generating-custom-photo-realistic-faces-using-ai-d170b1b59255
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
