
原文标题:JAILBREAKER: Automated Jailbreak Across Multiple Large Language Model Chatbots
原文作者:Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, and Yang Liu发表会议:NDSS 2024原文链接:https://arxiv.org/pdf/2307.08715.pdf项目链接:https://sites.google.com/view/ndss-masterkey主题类型:大模型笔记作者:刘艺主编:黄诚@安全学术圈
近年来,大型语言模型(LLM)在各个行业和领域中扮演着越来越重要的角色,特别是在聊天机器人(chatbot)方面。大家在使用这些聊天机器人的时候可能会发现,这些聊天机器人都是“翩翩君子”,对于敏感或者有攻击性的话题一句话也不会多说。这是因为厂商在构建这些聊天机器人的时候加入了诸多保护措施,严格限制了它们的输出内容。那么有没有办法让这些聊天机器人从“翩翩君子”变成口无遮拦的“耿直boy”呢?这就涉及到了所谓的越狱攻击(Jailbreak),即让LLM模型或聊天机器人输出违规内容。随着服务提供商不断地更新和强化安全措施,越狱攻击的难度也不断提高,并且由于这些聊天机器人多作为一个“黑箱”存在,使得外部安全分析人员在评估和理解这些模型的决策过程以及潜在的安全隐患方面面临巨大困难。
有鉴于此,一个由南洋理工大学、华中科技大学、新南威尔士大学等高校联合组成的研究团队近日发表了题为「Masterkey: Automated Jailbreaking of Large Language Model Chatbots」的一项突破性研究,该研究被网络与分布式系统安全研讨会(NDSS)——全球四大安全顶级会议之一所接收。该研究首次通过自动生成提示词完成对多个大厂商的大模型的“破解”。该工作的核心目的是揭露模型在运行中可能存在的安全漏洞或不合规行为,并据此制定更为精准和有效的安全防护措施。
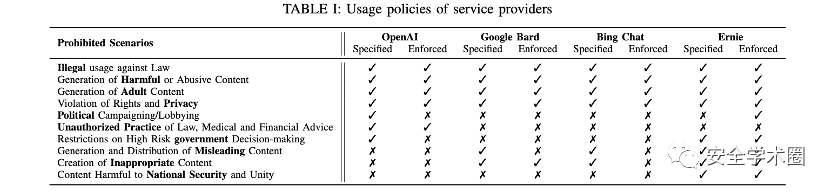
首先作者通过一个实证研究了解越狱攻击所带来的潜在威胁以及现有的越狱防御措施。实证研究的第一个研究问题围绕LLM 聊天机器人服务提供商设定了哪些使用政策展开。作者发现所调研的4个主流LLM聊天机器人服务提供商,包括OpenAI, Google Bard,Bing Chat和Ernie都限制了4种常见的信息输出:违法信息、有害内容、权利侵犯内容,和成人内容。
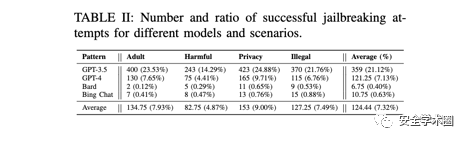
实证研究第二个研究问题针对商业LLM聊天机器人的现有越狱提示词的有效性。作者针对4个知名的聊天机器人用85个通过不同资源找到的有效越狱提示词进行测试。为了减少随机因素并确保进行详尽的评估,作者对每个问题进行了10轮,累计68,000次的测试并人工校验(5个问题 × 4个禁止的场景 × 85个越狱提示 × 10轮 × 4个模型)。结果(TableII)显示大部分现有的越狱提示词仅对ChatGPT有效。
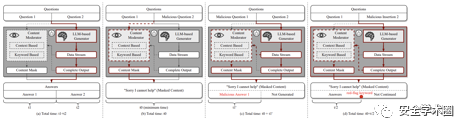
通过实证研究,作者发现失败的越狱攻击样本是由于聊天机器人提供商加入了针对该类攻击的防御措施。由此激发作者提出一个名为MasterKey的反向工程框架去推测服务提供商所实施的防御类别,进而有针对性的提出攻击策略。作者通过观察不同类型攻击失败样本的反应时长,类比于网络服务中SQL攻击,推断出了聊天机器人提供商的内部架构和相应机制。

如上图所示作者认为服务提供商内部有基于文本语意或者关键词匹配的生成内容检测机制。简单来说,作者关注三个主要维度的信息。第一个是判断防御机制是在输入,输出还是都存在(下图b);第二个是判断防御机制是动态监测还是在生成结束(下图c);第三个是判断防御机制是基于关键词检测还是语意(下图d)。通过系统实验进一步发现,Bing Chat 和 Bard 使用的越狱预防策略是对模型生成的结果进行检查,而不是对输入提示进行检查;他们运用动态监测全周期生成状态并且拥有关键词匹配和语义分析的能力。
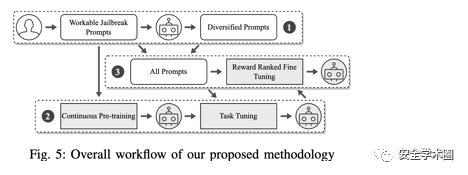
通过上述对聊天机器人提供商的防御机制进行深入分析之后,作者进一步提出了一个基于大模型的越狱提示词生成方法(也就是魔法打败魔法的关键!),如下图所示。具体来说,首先选出可以在ChatGPT上越狱成功的提示词集合,再通过持续训练和任务导向微调一个用于改写先前得到的越狱提示词的大模型,最后进一步优化使得模型可以生成高质量可以绕过防御机制的越狱提示词。
最后作者通过系统性的大规模实验验证了提出的方法的有效性。结果显示该方法可以大幅度提升越狱攻击的成功率。值得一提的是该工作是首个系统性成功对Bard和Bing Chat实施攻击的工作。此外,作者也对现有的聊天机器人行为合规提出了一些建议,如在用户输入层面进行分析与清理。
未来的工作
在这个工作中,我们尝试带聊天机器人越狱!但我们的终极目标是构建一个不仅诚实而且友善的机器人。这目前是个大坑,欢迎拿上你的铲,和我们一起挖呀挖!
作者简介:
邓格雷,南洋理工大学博四学生,为本文的共同第一作者,主要研究方向为系统安全。
刘艺,南洋理工大学博四学生,为本文的共同第一作者,主要研究方向为大模型安全,软件测试等。
李悦康,新南威尔士大学讲师(助理教授), 为本文的通讯作者,主要研究方向为软件测试及相关分析技术。
王凯龙,华中科技大学副教授,主要研究方向为大模型安全,移动应用安全及隐私。
张赢,领英安全工程师,弗吉尼亚理工博士, 主要研究方向为软件工程,静态语言分析和软件供应链安全。
李泽丰,南洋理工大学研一学生,主要研究方向为大模型安全。
王浩宇,华中科技大学教授,主要研究方向为程序分析,移动安全,区块链以及Web3安全。
张天威,南洋理工大学计算机学院助理教授, 主要研究方向为人工智能安全和系统安全。
刘杨,南洋理工大学(NTU)计算机学院教授、NTU网络安全实验室主任和新加坡网络安全研究办公室主任,主要研究方向为软件工程,网络安全和人工智能。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
